No Token Left Behind: Reliable KV Cache Comopression via Importance-Aware Mixed Precision Quantization
LLM-KV-Cache-Q

- 한 줄 정리
- KV cache eviction method에서 기존에 evict되는 unimportant token들을 low-precision으로 저장해서 최소한의 정보를 유지하고,
important token은 high precision으로 저장하는 mixed-precision 접근.
- KV cache eviction method에서 기존에 evict되는 unimportant token들을 low-precision으로 저장해서 최소한의 정보를 유지하고,
Observation
1) context damage from KV cache eviction
-
token eviction에서 사용되는 imoprtance criteria에는 locality, frequency, attention structure 등이 있다.
-
아무리 좋은 importance 기준을 사용하더라도, model의 intermediate states를 제거해버리기 때문에, input context의 loss가 발생하는 risk가 있다.
evict된 token(evicted KV pair)이 미래에 중요한 정보로 사용될 지 예측할 수 없다. -
KV pair가 eviction됨에 따라 input context의 key detail이 빠르게 손실되며, 이로 인해 contextual incoherency, hallucinatory response, 그리고 detail loss가 발생하는 것을 확인했다.
1-1) Saftety Breach (Qualitative Analysis 1)
- () eviction strategy의 사용은 critical information의 손실을 초래할 수 있으며, 이는 safety mechanism을 저해하고 상당한 potential risk를 유발할 수 있다.

1-2) Contextual incoherency (Qualitative Analysis 2)
-
과거에 해당하는 정보는 점차 소실되는 반면, 상대적으로 미래에 해당하는 정보는 유지되어 coherence가 부족한 문장이 생성된다.
-
() context-based question-answering task에서 Two New Sciences에 대한 중요한 정보가 손실됨으로써 모델이 해당 내용을 잊었지만, 책의 출판 연도는 여전히 기억하는 상황이 발생하였다. 이러한 부분적인 정보 손실은 결국 논리적으로 일관되지 않으며, 잠재적으로 오해를 유발할 수 있는 response를 생성하게 만든다.

contextual incoherency 실험에 사용한 prompt
1-3) Loss of detail and hallucination (Qualitative Analysis 3)
-
KV pair의 eviction은 필연적으로 contextual information의 손실을 초래하며,
이 과정에서 모델은 누락된 context segment를 ‘hallucinate’할 가능성이 있다. -
() topic retrieval task (Li et al., 2023a).
이 task에선 여러 주제에 대한 user-assistant 간 dialogue가 진행된 후, 시스템이 특정 topic을 회상해야 한다.
그러나 eviction으로 인한 information loss는 generation 과정에서 오류를 유발할 수 있다.

1-4) Quantitative Analysis: Line Retrieval task
-
KV cache eviction이 context에 미치는 영향을 정량적으로 평가하기 위해, 보다 통제된 환경에서 robustness를 분석함.
-
이 task에서는 LLM이 key와 value로 구성된 일련의 randomly generated string을 context로 제공받고, 이후 user가 context 내 존재하는 특정 key를 입력하여 해당하는 value를 retrieval하도록 요청한다.
strategy는 hypothetical simulation을 기반으로 cache eviction scenario를 가정하여 수행된다.
즉, 실제로 KV를 제거하는 것이 아니라, full cache 상태에서 attention map을 먼저 계산한 후, post-attention 단계에서 top-k sparsity를 적용하는 방식이다.
이를 통해 특정 token을 생성할 때 과거 KV의 importance를 정확히 예측할 수 있는 proxy upper bound를 제공한다. -
비교 대상: importance-based eviction (H2O (Zhang et al., 2023)), oracle eviction을 full cache와 비교하여 분석하였다.
-
() cache eviction은 빠른 performance degradation을 초래하였다.
더 나아가, 에서도 performance degradation이 관찰되었으며, 이는 미래 KV의 importance를 사전에 알고 있더라도 performance loss를 피할 수 없음을 보여준다.
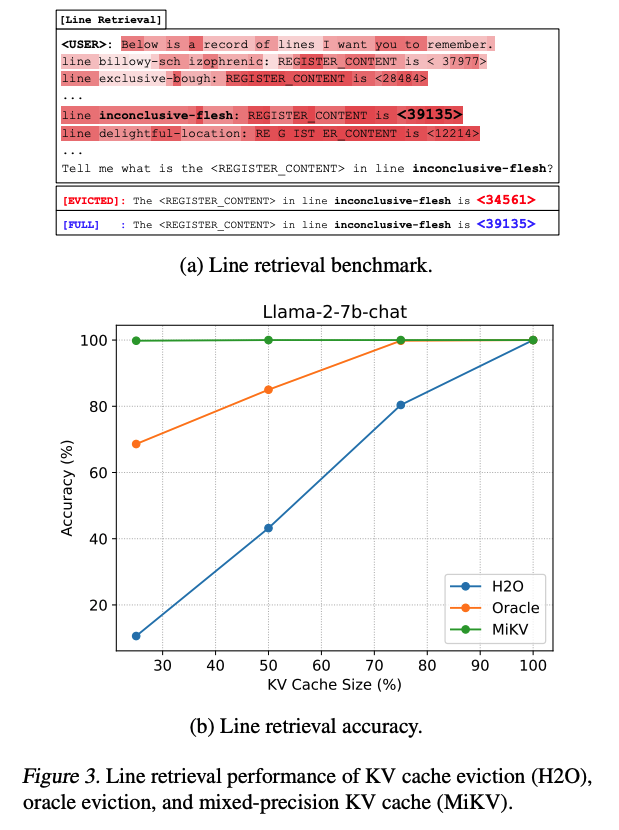
-
이 실험은 KV cache eviction strategy가 초래할 수 있는 potential risk를 명확히 확인시켜 준다.
따라서, contextual detail을 안정적으로 보존하면서도 효율적인 compression ratio를 달성할 수 있는 KV cache compression methodology의 필요성이 더욱 강조된다.
Key contributions
- () MiKV Framework
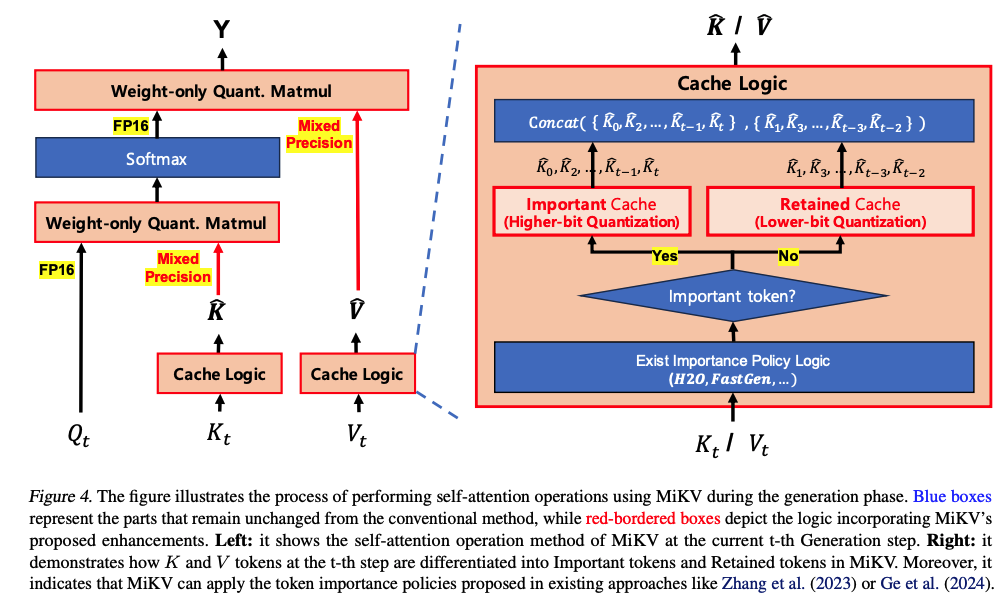
1) unimportant evicted KV를 low-bit Quantize해서 유지
-
eviction method의 context damage를 해결하기 위해, low-bit quantization을 활용해 evicted KV pair를 보존하는 방법을 제안.
-
사용한 eviction method: importance-based eviction strategy(H2O)
사용한 quantization method: 일반적인 per-token asymmetric quantization (LLM-QAT, Liu et al., 2023b) -
() evicted KV를 low-precision quantization을 통해 보존할 경우, 다양한 eviction ratio에서 손실된 성능을 상당 부분 복구할 수 있음을 확인하였다.
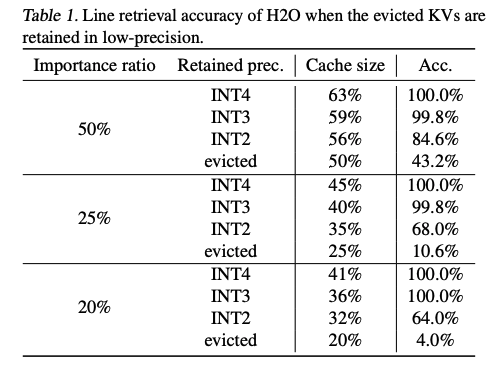
-
이 방법의 trade-off: low-bit preservation은 eviction에 비해 performance degradation을 효과적으로 완화하지만, memory consumption이 증가.
-
따라서, 효율적인 compression rate을 달성하려면, evicted KV의 precision을 충분히 낮은 수준으로 조정 필요.
하지만 precision이 지나치게 낮아지면 (예: INT2), performance recovery가 저하되므로 memory trade-off를 개선하는 데 어려움이 따름.
=> 이는 KV cache에 최적화된 low-precision quantization scheme이 필요함을 시사.
2) Outlier-aware 처리
-
quantization error로 인한 performance degradation 명확히 이해하기 위해,
attention module 내 query, key, value의 magnitude characteristic을 empirical하게 분석함. -
()
✅ query와 key에서 systematic outlier가 발생함. => 이는 quantization 과정에서 상당한 error를 초래
✅ 또한, RoPE를 적용하면 이러한 outlier가 중복되어 발생함.
✅ outlier channel의 위치는 sequence 내에서 크게 변하지 않고 일정하게 유지됨을 관찰.
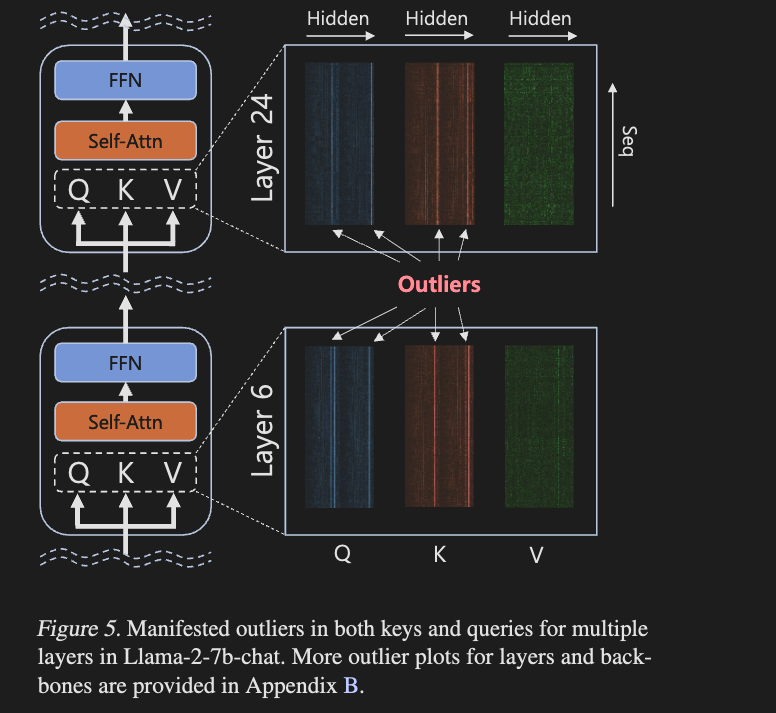
-
기존 연구 착안
기존 LLM의 weight 및 activation quantization 연구에서는 outlier를 조정하여 weight와 activation 간 균형을 맞추는 방법이 제안됨().
이에 착안해, query와 key에서 발생하는 outlier를 동적으로 균형 조정하여 quantization error를 줄이는 방법을 제안. -
Think 1) Figure 5에서 outlier channel의 위치는 sequence 내에서 크게 변하지 않고 일정하게 유지됨을 관찰함.
Think 2) Query를 FP16 precision으로 유지하는 scheme을 채택하면, quantization burden을 주로 query 측으로 전가할 수 있음.
✅ Key의 outlier를 줄이기 위해 channel-wise scaling factor 를 곱한 후 quantize하고,
Query에는 channel-wise scaling factor 를 나누어주는 방식을 제안. -
논문에서는 channel balancer라고 부르는 channel-wise scaling factor를 아래와 같이 정의한다.
prefill 과정에서, layer 𝑙, head ℎ, channel 𝑐 에 대해,
query와 key의 intra-head channel별 max 값을 이용해 channel-wise scaling factor를 계산한다.그리고 이 channel-wise scaling factor를 Key의 outlier를 줄이기 위해 Key에 를 곱한 후 quantization하고,
Query에는 를 나누어준다.(여기서 는 quantization 연산을 의미)
- K 측면: 을 곱함으로써 의 dynamic range를 줄여, clipping을 방지하고 low-bit quantization이 더 안정적으로 수행되도록 한다.
- Q 측면: Query는 로 나누어 원래 크기로 복원되는데, 가 FP16 precision을 유지하므로, 이 과정에서 quantization error가 발생하지 않는다.
- 즉, Key에서 outlier 제거를 위해 scaling 처리를 수행하되, 그 보정 연산을 Query에서 수행하게 되며, FP16 precision을 유지하는 Query가 이러한 변화를 absorb할 수 있기 때문에 quantization error를 최소화할 수 있다.
-
결과 () outlier-aware quantization 방식은 INT2 precision에서도 line retrieval performance를 효과적으로 복구 가능함.
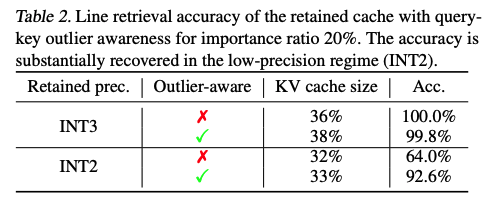
-
부가 설명
-
이 과정에서 balancer는 prefill phase에서 한 번만 계산되므로,
generation phase에서는 element-wise product 연산만 수행되기에, computational 및 memory overhead가 적다. -
RoPE로 인한 artifact를 완화하기 위해 attention head dimension의 절반 크기를 group size로 설정했다.
-
Alternative Approach: Per-Channel Quantization
다른 방법으로, outlier를 isolation하는 per-channel quantization (Rethinking Heo et al., 2023)도 고려할 수 있다.
하지만, 이 방식은 기존 mixed precision scheme을 수정해야 하며, triple mixed precision을 사용해 KV pair를 buffering해야 하는 추가적인 computational cost가 발생한다.
관련 Appendix C 요약
-
3) important KV를 high-precision으로 Quantize
-
mportance cache도 quantization하여 memory footprint를 추가로 줄이는 방안을 조사함.
-
() importance cache가 전체의 20%를 차지하고, outlier-aware retention cache가 2-bit precision으로 동작하는 환경에서 수행한 실험 결과.
INT4 까진 줄여도 accuracy 유지 가능. INT2로 줄이면 accuracy 심각하게 하락.
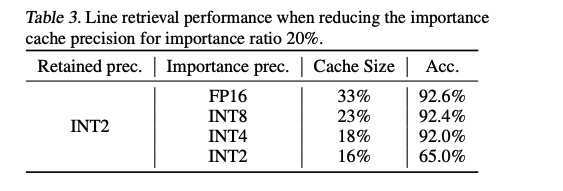
Experimental Results
Memory Footprint Analysis
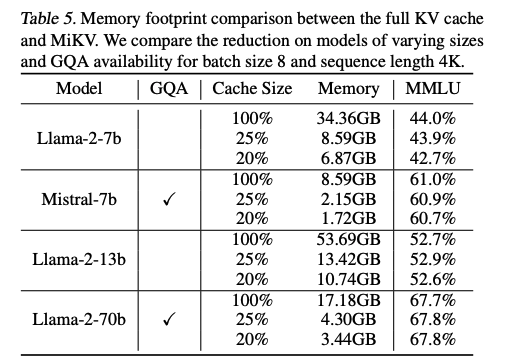
추가 참고 내용(Appendix 포함)
3.4. Accelerating the Mixed-Precision KV Cache
-
우리는 mixed-precision KV cache의 operation을 가속화하는 방법을 논의하며, 기존의 weight-only quantized kernel을 활용하는 방안을 제안한다 (Park et al., 2022; Lin et al., 2023). 이 방법은 다음 두 가지 핵심 원리에 기반한다.
-
Positional Embedding 이후 Self-Attention의 순열 불변성
- Self-attention은 permutation invariant하기 때문에, KV pair가 함께 permute되면 임의로 정렬할 수 있다.
이를 활용하면, precision에 따라 KV pair를 그룹화할 수 있으며, 이는 quantization 적용을 더욱 효율적으로 만든다.
- Self-attention은 permutation invariant하기 때문에, KV pair가 함께 permute되면 임의로 정렬할 수 있다.
-
Generation Phase에서의 Memory Wall 문제 해결
- Self-attention은 batch-GEMV (Generalized Matrix-Vector Multiplication) operation을 통해 수행된다.
GPU와 같이 높은 연산 성능을 가진 장치에서는 memory bandwidth가 병목이 되어 latency가 증가하는 memory wall problem이 발생한다 (Hong et al., 2023).
이를 해결하기 위해, MiKV (Mixed-Precision KV)는 K와 V의 precision을 줄이면서, Q와 attention map은 floating point precision을 유지한다.
이러한 방식은 기존의 batch-GEMV operation 대신 weight-only quantization kernel을 활용할 수 있도록 하며, 결과적으로 연산 속도를 증가시킨다.
- Self-attention은 batch-GEMV (Generalized Matrix-Vector Multiplication) operation을 통해 수행된다.
saftey breach 실험에 사용한 prompt

contextual incoherency 실험에 사용한 prompt

alter native approach: per-channel quant
이 방식은 outlier channel을 자연스럽게 격리하는 효과가 있으며, 최근 연구에서는 outlier 방향과 quantization 방향이 일치할 때 quantization error가 감소한다는 점을 확인하였다 (Heo et al., 2023).
이를 검증하기 위해, 우리는 Section 3.2에서 수행한 실험을 per-channel key quantization 방식으로 재구성하여 실험을 진행하였다. 하지만, per-channel dynamic quantization을 적용하려면 기존의 caching mechanism을 구현 수준에서 변경해야 한다.
KV pair를 임시 버퍼에 저장: 일정 개수의 KV pair가 모일 때까지 임시 버퍼에서 대기 후 quantization 수행
중요한 KV pair와 중요도가 낮은 KV pair를 별도로 유지: 추가적인 임시 버퍼 필요
Groupwise per-channel quantized tensor에서 eviction 처리 문제: 타일 크기가 비균등해지므로 기존 eviction policy를 수정해야 함
