"optimize the parallel function calling performance of LLMs"
Significance(의의)
- first framework to optimize the orchestration of LLM function calling that can not only improve latency and cost, but also accuracy,
by minimizing interference from the outputs of intermediate function calls.
Motivation
- current function calling methods
- require sequential reasoning
and acting for each function
➡️ latency, cost
- require sequential reasoning
pioneering work in function calling
- important challenge: what is the most effective approach to incorporate multiple function calls?
- notable approach: ReAct(Yao et al., 2022)
- LLM calls a function, analyzes the outcomes, and then reasons about the next action, which involves a subsequent function call.
- pioneering work in enabling function calling
- integrated into several frameworks(Langchain)
- notable approach: ReAct(Yao et al., 2022)
ReAct Architecture
- Figure1 (left) React
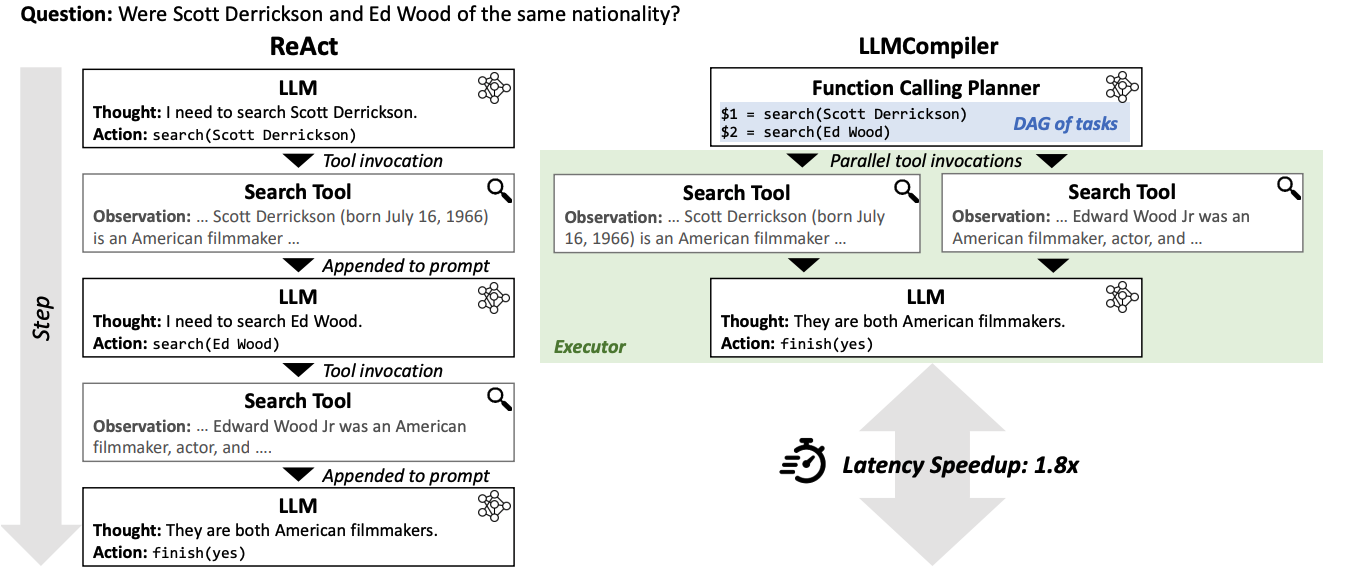
- LLM is asked if Scott Derrickson and Ed Wood have the same nationality.
- ReAct initially analyzes the query
and decides to use a search tool to search for Scott Derrickson. - result of search is then concatenated back to the original prompt for the LLM to reason about the next action,
which invokes another search tool to gather information about Ed Wood.
- ReAct initially analyzes the query
ReAct Limitation
-
However, scaling ReAct approach for more complex applications requires considerable optimizations.
-
This is due to the sequential nature of ReAct,
where it executes function calls and reasons about their observations one after the other. -
limitation and effect 1) agent systems that extend ReAct may lead to inefficiencies in latency and cost, due to the sequential function calling and repetitive LLM invocations for each reasoning and action step
-
limitation and effect 2) while dynamic reasoning about the observations has benefits in certain cases, concatenating the outcomes of intermedi- ate function calls could disrupt the LLM’s execution flow, potentially reducing accuracy (Xu et al., 2023)
-
Common failure cases include repetitive invocation of the same function, which is also highlighted in the original paper (Yao et al., 2022),
-
LLM Compiler's inspiration
-
classical compilers,
where optimizing instruction executions in traditional programming language has been extensively explored. -
key optimizaiton technique in compilers
: identifying instructions that can be executed in parallel and effectively managing their dependencies.
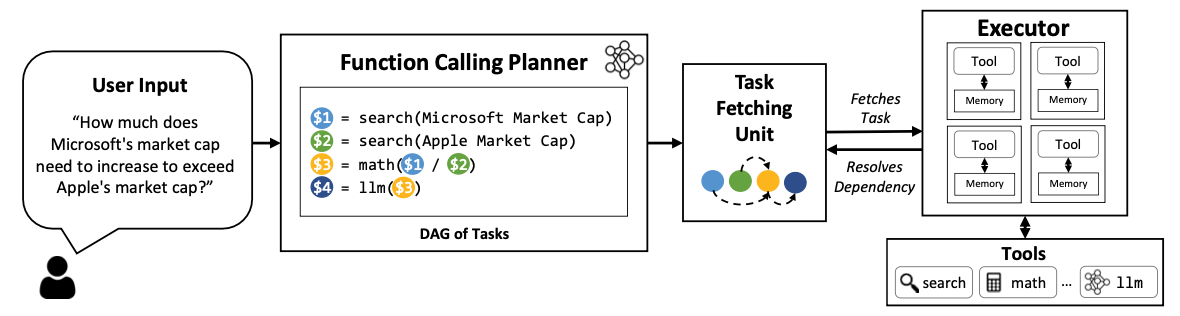
Methods
- parallel function calling
with components
(fig 2)
-
1. function calling planner (LLMs)
-
identifies an execution flow.
-
generates a sequence of tasks and their dependencies
-
example
- Task $1 and Task $2 are two independent searches
that can be performed in parallel.
However, Task $3 has a dependency on the outcomes of the first and second searches.
- Task $1 and Task $2 are two independent searches
-
Planner's Role
-
LLM의 reasoning capability를 사용해서,
automatically identify-
the necessary tasks,
-
their input arguments,
-
their inter-dependencies
essentially forming a directed acyclic graph(DAG) of task dependencies. -
placeholder variable 사용
If a task is dependent on preceding task,
it incorporates a placeholder variable,
such as $1 in Task 3 of Fig.2
which will later be substituted with the actual output from the preceding task.
-
-
즉, natural language inputs를 받아서, decompose tasks
-
pre-defined prompt
pre-defined prompt that guides it on how to create dependency graphs and to ensure correcy syntax


-
users are only required to provide
-
tool definitions
-
tool descriptions
-
argument specifications.
-
This is essentially the same requirement as other frameworks like ReAct and OpenAI function calling.
-
-
optional in-context examples
-
examples of how the Planner should behave.
-
examples illustrating expected inter-task dependencies for certain queries.
-
These examples can assist the Planner LLM understand how to use various tools and generate the appropriate depen- dency graph for incoming inputs in the correct format.
-

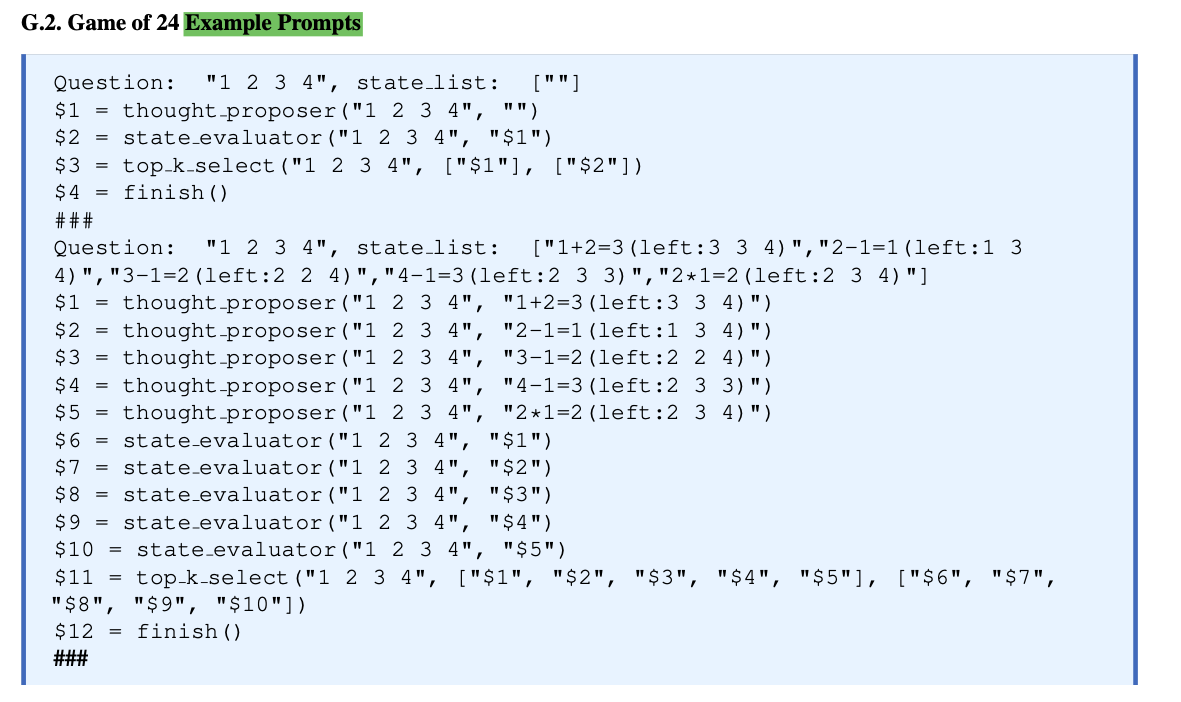
-
-
-
-
-
- help the planner to better understand the rules.- LLM의 input = pre-defined prompt + (user) tool definitions + optional in-context examples
- additional optimization for the planner
- streams tasks as soon as they are created,
instead of waiting to complete the entire planning process. - sec 4.1
- sec 4.2
- streams tasks as soon as they are created,
-
2. task fetching unit
-
dispacthes the function calls in parallel
-
replace placeholder variables with the actual outputs from preceding tasks.
-
inspiration
- inspired by the instruction fetching units in modern computer architectures,
fetches tasks to the Executor as soon as they are ready for (parallel) execution
based on a greedy policy.
- inspired by the instruction fetching units in modern computer architectures,
-
example
- variable $1 and $2 in Task $3 would be replaced with the actual market cap of Microsoft and Apple.
- variable $1 and $2 in Task $3 would be replaced with the actual market cap of Microsoft and Apple.
-
여기선 LLM 안씀
This can be implemented with a simple fetching and queuing mechanism without a dedicated LLM.
-
-
3. executor
-
ashynchronoulsy executes the tasks
fetched from the Task Fetching Unit,
using the associated functions(tools) in parallel. -
as the Task Fetching Unit gurantees that all the tasks dispatched to the Executor are independent,
it can simply execute them concurrently. -
euipped with user-provided tools
-
and delegate the task to the associated tool.
-
tool:
- simple functions like a calculator
- wikipedia search
- api calls
- LLM agents that are tailored for a specific task.
-
each task has dedicated memory to store its intermediate outcomes,
similar to what typical sequential frameworks do when aggregating observations as a single prompt(ReAct) -
Upon completion of the task, the final result are forwarded as input to the tasks dependent on them.
-
-
User input: “How much does Microsoft’s market cap need to increase to ex- ceed Apple’s market cap?”
-
LLM first needs to conduct web searches for both companies’ market caps, followed by a division operation.
-
existing frameworks(including ReAct)
perform these tasks sequentially. -
LLMCompiler
perform these tasks in parallel.
-
-
-
key question
how to automatically determine which tasks are parallelizable and which are interdependent.
so we can orchestrate the execution of the different tasks accordingly.
➡️ three components로 achieve. -
Dynamic Replanning
-
intermediate results에 따라서, execution graph를 수정해야 할 필요가 있다.
-
programming에서 branching 하듯이, LLM function calling에서도, dynamic execution이 가능하다.
-
simple branching의 경우 (e.g., if-else statements)
- statically compile the execution flow
and choose the right dynamically
based on the intermediate results.
- statically compile the execution flow
-
하지만, complex branching의 경우
- recompilation 또는
- intermediate result를 토대로 replanning이 나을 수 있음.
-
Experiment
-
LLMs: GPT-3.5-turbo, LLaMA-2
-
비교 대상(baseline): ReAct
-
Benchmark
Dependency ❌- HotpotQA
- 1.80x speedup, 3.37x cost reduction
- contains 1.5k questions comparing two different entities, thus exhibiting a 2-way embarrassingly parallel execution pattern.
- Movie Recommendation
- 3.74x speedup, 6.73x cost reduction
- 500 examples that asks to identify the most similar movie out of four options to another set of four movies, exhibiting an 8-way embarrassingly parallel pattern
- HotpotQA
Dependency ⭕, dependency graph (static)
- ParallelQA
- complex pattern에서 performance test위한 new benchmark 도입
- 2.27x speedup, 4.65x cost reduction, 9% improved accuracy
- 113 examples that involve mathematical questions on factual attributes of various en- tities.
**Dependency O, dependency graph (dynamically)
-
Game of 24(Yao et al. 2023b)
-
for evaluating capability in dynamic re-planning
which is achieved through a feedback loop from the Executor back to our Function Calling Planner. -
task to generate 24 using a set of four numbers and basic arithmetic operations.
-
Game of 24 requires repeated replanning based on the intermediate results
-
2× speedup compared to Tree-of-Thoughts
-
-
WebShop
- for evaluating interactive decision-making environment efficiently.
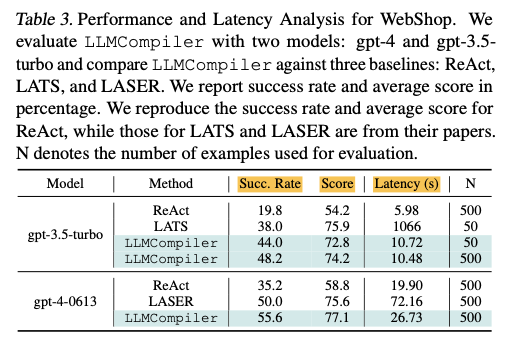
- 101.7× speedup and 25.7% improved success rate compared to ReAC
5.1 Parallel Function Calling w/o Dependencies
-
가장 간단한 시나리오.
using a tool repeatedly for independent tasks
such as conducting parallel searches or analyses to gather information on different topics -
embarrassingly parallel patterns
- where all tasks can be executed in parallel
without any dependencies between them, - Fig 3(a)
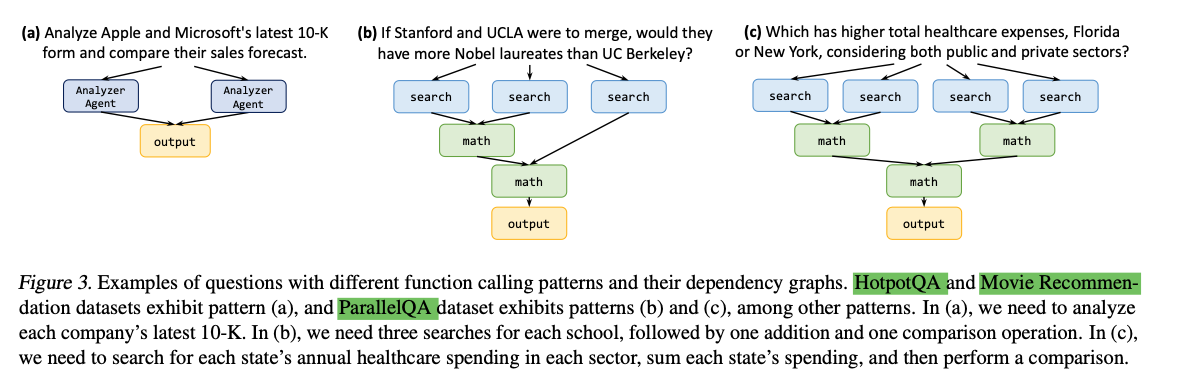
- where all tasks can be executed in parallel
-
Dataset: HotpotQA, Movie Recommendation
-
ReACT는 suquential하게 실행할 수 밖에 없음.
- latency
- token consumption
-
Experimental setups
- Wikipedia search tool (ReAct와 동일)
that LLMs can use to search for information. - optimized the prompt and in- context examples for both ReAct and LLMCompiler to the best of our abilities.
- LLM
- gpt-3.5-turbo(HotpotQA), gpt-4-turbo(ParallelQA), gpt-4(Game of 24)
- GPT를 사용하는 경우, OpenAI’s parallel function calling capability를 추가적으로 Report함. (이 연구와 concurrent하게 발표됨)
- LLaMa-2 70B model (2 A100-80GB GPUs, using the vLLM framework)
- gpt-3.5-turbo(HotpotQA), gpt-4-turbo(ParallelQA), gpt-4(Game of 24)
- measurement
- accuracy
- end-to-end latency
- input and output token usage
- Wikipedia search tool (ReAct와 동일)
-
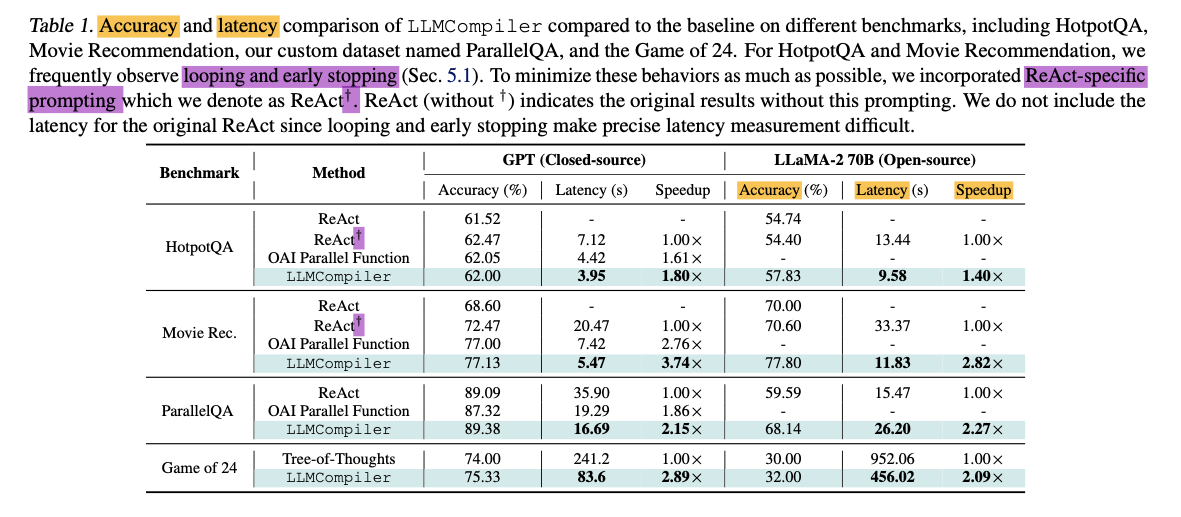
Accuracy and Latency
-
Observation 1) ReAct consistently achieves lower accuracy compared to OpenAI parallel function calling and LLMCompiler.
- identify two main failure modes in ReAct
- tendency for re- dundant generation of prior function calls
a point also noted in the original ReAct paper (Yao et al., 2022); - pre-mature early stopping based on the incomplete intermediate results.
- tendency for re- dundant generation of prior function calls
- LLMCompiler, leading to an accuracy enhancement of up to 7 – 8%
- ReAct-specific prompt 모델도 original보단 낫지만, LLMCompiler보단 accuracy 낮음.
- prompting does not serve as a perfect solution to completely avoiding the erroneous behavior of ReAct.
- identify two main failure modes in ReAct
-
React^십자가 와 비교해서, LLMCompiler가
- Hotpot QA
- 1.80X speedup (with GPT)
- 1.40X sppedup (with LLaMA)
- Movie Recommendation
- 3.74x speedup
- 2.82x speedup
- Hotpot QA
-
Cost
- ReAct와 OpenAI parallel functino calling보다 저렴.
- 이는 LLMCompiler의 planning phase가
openAI parallel function calling보다
prompt length efficient하고,
Planner의 in-context examples가 상대적으로 short하고, observation이 아닌 plans만을 포함하기 때문.
-
5.2 Parallel Function Calling with Dependencies
-
조금 더 복잡한 task.
Fig 3 (b)와 (c)
-
completing the task requires using two tools
(i.e., search and math tools),
with the second tool’s argument depending on the result of the first tool’s output. -
dependency graphs can be determined statically.
-
Dataset: ParallelQA
ex) “If Texas and Florida were to merge and become one state, as well as California and Michigan, what would be the largest population density among these 2 new states?” -
Accuracy and Latency
-
Tab.1.
-
LLMCompiler의 Failure Case
- Appendix B,
here we note minimal Planner failures, high- lighting LLMCompiler’s effectiveness in breaking down problems into complex multi-task dependencies.
- Appendix B,
-
-
Cost
-
Tab 2.
-
this efficiency stems from LLMCompiler's reduced frequency of LLM invocations,
- which is also the case with OpenAI’s parallel function calling,
which is limited to planning out immediate parallelizable tasks,
not the entire dependency graph. - For example, in Fig. 3 (c),
OpenAI’s method would necessitate three distinct LLM calls for initial search tasks, following math tasks, and the final math task.
In contrast, LLMCompiler achieves this with a single LLM call, planning all tasks concurrently.
- which is also the case with OpenAI’s parallel function calling,
-
5.3 Parallel Function Calling with Replanning
- dependency graphs need to be con- structed dynamically depending on intermediate observa- tions.
Success Rate and Latency
5.4 Application: LLMCompiler in Interactive Decision Making Tasks