[Mask2Former] Masked-attention Mask Transformer for Universal Image Segmentation (CVPR 2022)
Author: Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
🚀 Motivations
-
Different types of segmentation tasks,
such as panoptic, instance or semantic segmentation. -
While these tasks differ only in semantics,
current methods develop specialized architectures
for each task. -
Such specialized architectures
lack the felxibility to generalize to other tasks. -
✅ Mask2Former
capable of addressing any image segmentation task
(panoptic, instance or semantic) -
Key components include "Masked-attention",
which extracts localized features
by constraining cross-attention
within predicted mask regions. -
Mask2Former is built upon a
simple meta architecture [14]
[14] Per-pixel classification is not all you need for semantic segmentation (Bowen et al.)
consisting of a backbone feature extractor [25, 36],
[25] Deep Residual Laerning for image recognition
[36] Swin transformer: Hierarchical vision transformer using shifted windows
a pixel decoder [33]
[33] Feature pyramid networks for object detection
and a Transformer decoder [51]
[51] Attention is all you need
🔑 Key Improvements
-
First,
used "masked attention" in the Transformer decoder
which resticts the attention to localized features
centered around predicted segments,
which can be either objects or regions depending on the specific semantic for grouping.Compare to the cross-attention used in a standard Transformer decoder
which attentds to all locations in an image,
maked attention leads to faster convergence & improved performance. -
Second,
use multi-scale high-resolution features
which help the model to segment small objects/regions. -
Third,
Propose optimization improvements
such as switching the order of self and cross-attention,
making query features learnable,
and removing dropout -
Finally,
save training memory
by calculating mask loss
on few randomly sampeld points.
Related Works
Specialized Semantic Segmentation Architectures
-
Treat the task as a "per-pixel classification" problem.
-
FCN-based architectures [37]
independently predict a category label
for every pixel. -
Follow-up methods find context
to play an important role
for precise per-pixel classification
- And focus on designing customized context modules [7,8,63]
or self-attention variantes[21, 26, 45, 55, 61, 64]
Specialized Instance Segmentation Architectures
-
Based upon "Mask Classification"
-
Predict a set of binary masks
each associated with a single class label -
Pioneering work, Mask R-CNN[24], generates masks
from detected bounding boxes.
Panoptic Segmentation
- Unify both semantic and instance segmentation tasks.
Univseral Architectures
-
Emerged with DETR[5]
-
And show that "Mask Classification" architectures
with an end-to-end set prediction objective are general enough
for any image segmentation task. -
MaskFormer [14] shows that
"Mask Classification" basd on DETR
not only performs well on panoptic segmentation,
but also achieves SOTA on semantic segmentation. -
Mask2Former is the first architecture
that outperforms SOTA specialized architectures
on all considered tasks and datasets.
⭐ Methods
Mask classification preliminaries
-
Mask Classification architectures
group pixels
into N segmentsby predicting N binary masks,
along with N corresponding category lables.
https://velog.io/@yeomjinseop/Mask-Classficiation
☕
-
However, 🚩 Challenge is
to find good representations for each segment. -
For example,
Mask R-CNN uses bounding boxes as representation
which limits its application to semantic segmentation. -
Inspired by DETR,
each segment
in an image
can be represented as a C-dimenstional fature vector("object query") -
And can be processed by a Transformer decoder,
trained with a set prediction objective.
☕
-
A simple meta architecture would
consist of three components. -
1) backbone
that extracts 'low-resolution features' from an image. -
2) pixel decoder
that gradually upsamples low-resolution features
from the output of the backbone
to generate 'high-resolution' per-pixel embeddings -
3) Transformer Decoder
that operates on image features
to process object queries. -
Final binary mask predictions
are decoded from 'per-pixel embeddings'
with object queries. -
One successful instantiation of such a meta architecture
is MaskFormer
Transformer decoder with masked attention
-
Mask2Former adopts the aforementioned meta architecture,
as MaskFormer[14],
with our proposed Transformer decoder (Fig2, right)
replacing the standard one. -
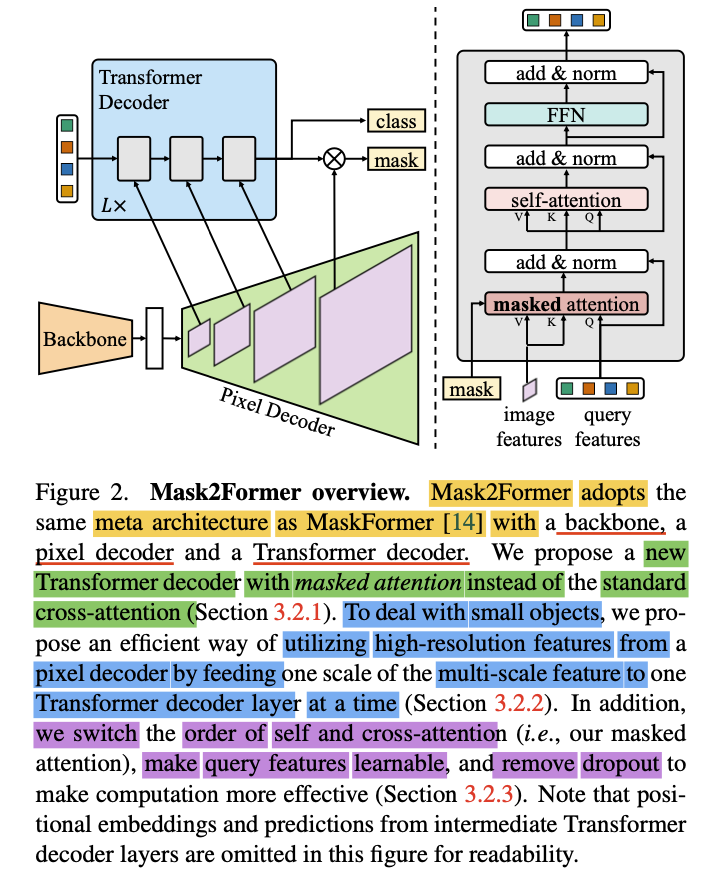
1️⃣ Masked Attention
-
Key components of our Transformer decoder include
a masked attention operator,
which extracts localized featrues
by constraining cross-attention to
within the foreground region of predicted mask for each query,instead of attending to the full feature map.
Details
🚀 Motivations
-
Context features
have been shown to be important
for image segmentation [7, 8, 63] -
However, recent studies [22, 46] suggest that
🔥 the slow convergence of Transformer-based models
is due to "global context" in the cross-attention layer, -
As it takes many training epochs
for cross-attention
to learn to attend to localized object regions.
✅ Solutions
-
We hypothesize that
1) Local features are enough
to update query features
&
2) Context information can be gathered
through self-attention. -
For this, we propose masked attention,
a varaiant of cross-attention
that only attends within the
foreground region of the predicted mask for each query.
👨🏻🔬 Formulations
-
Standard cross-attention (with residual path) computes
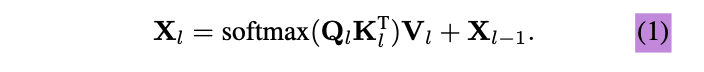
: layer index,
: query features (∈ ) @ layer
: input query features to the Transformer decoder.
: (∈ )
: image features under transformation (∈ )
: image features under transformation (∈ ): spatial resolution of image features
(that will be introduced in 2️⃣ High-resolution features)
: linear transformations. -
⭐Our masekd attention
modulates the attention matrix via
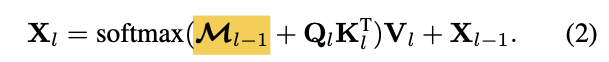
Moreover, attention mask
at feature location is
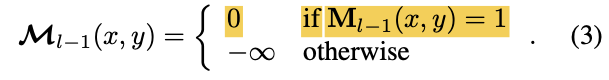
∈ : binarized output (thresholded at 0.50)
of the resized mask predction
of the previous -th Transformer decoder layer. -
is resized to the same resolution of
: binary mask prediction obtained from .
(i.e., before feeding query features into the Transformer decoder)
2️⃣ High-resolution features
-
To handle small objects,
we propose an efficient multi-scale strategy
to utilize high-resolution features. -
It feeds successive feature maps
from the pixel decoder's feature pyramid
into successive Transformer decoder layersin a round robin fashion.
Details
🚀 Motivations
-
High-resolution features
import model performance,
especially for small objects. -
🔥 However, this is computationally demanding.
✅ Solutions
-
Thus, we propoes an efficient
multi-scale strategy
to introduce high-reolusion featuers
while controlling the increase in computation. -
Instead of always using the high-resolution feature map,
we utilize a feature pyramid
which consists of both low- and high-resolution features
&
feed one resolution of the multi-scale feature
to one Transformer decoder layer
at a time.👨🏻🏫 Specification
-
We use the feature pyramid
produced by the pixel decoder
with resolution and
of the original image. -
For each resolution,
we add both a "sinusoidal positional embedding" & "learninable scale-level embedding" -
We use those,
from lowest-resolution to highest-resolution
for the corresponding Transformer decoder layers
(Fig 2 left) -
Repeat this 3-layer Transformer decoder
times.
➡️ Final Transformer decoder hence has layers. -
More sprecifically,
the first 3 layers receives a feature map of resolution
and
,
where are the original image resolution.
This pattern is repeated in a round robin fashion
for all following layers.
3️⃣ Optimization improvements
-
Standard Transformer decoder layer
consists of 3 modules
to process query features
in the following order:
a self-attention module, a cross-attention and a feed-forward network. -
Moreover,
1) query features are zero initialized
before being fed into the Transformer decoder
&
2) are associated with learnable positional embeddings.
&
3) Drpout is applied to both
residual connections and attention maps.
Paper's Improved Decoder Layer
-
To optimize the Transformer decoder design,
3 improvements are made. -
1) we switch order of "self-attention" and "cross-attention"(out new "masked attention")
to make computation more effective:query features to the first self-attention layer
are image-independent
&
do not have signals from the imge,thus applying self-attention is unlikely to enrich information
-
2) Make query features learnable as well.
(we still keep the learnable query positional embeddings),
&
learnable query features are directly supervised
before being used in the Transformer decoder
to predict masksWe find these learnable query features
function like a region proposal network
and
have tha ability to generate mask proposals. -
3) We completely remove dropout in our decoder.
as we find dropout is not necessary
and
ususally decreases performance.
