🚀 Motivations
- Most researcher transform Point Cloud data to regular 3D voxle grids or collections of images to perform weight sharing and kernerl optimizations due to Point cloud's irregular format.
However, rendering data unnecessarily voluminous and cuases issues.
⭐ Methods
- PointNet is the neural network for point clouds which is able to process(synthesize, genrate) point cloud data.
- It is an Effective Architecture to process an unordered set of points for semantic feature extraction.
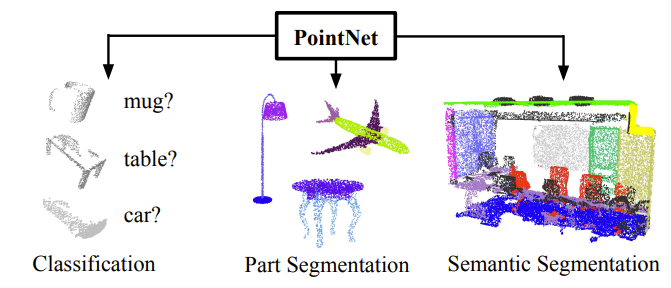
-
PointNet directly takes point clouds as input and outputs as class labels for the entire input or per point segment/part labels for each point of the input.
-
Provides unified architecture for object classification, part segmentation, scene semantic parsing.
Basic Idea of PointNet
- Making Permutation Invariance of points by
1) operating on each point independently and
2) subsequently applying a symmetric function to accumulate features.
Being able to process any set of point cloud data without concerning order of points.
For this idea, it uses Symmetric Function that can basically aggregate all the information coming from different points without using any order information.
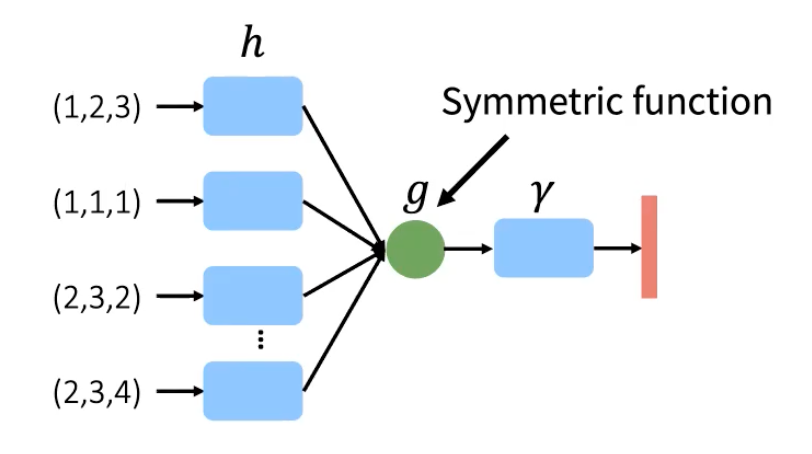
h is the pre-processor (in here, MLP)
and g is symmetric function (Max Pooling) that aggregates features
and r is the post-processor which is another MLP, processing output of aggregation function(symmetric function).
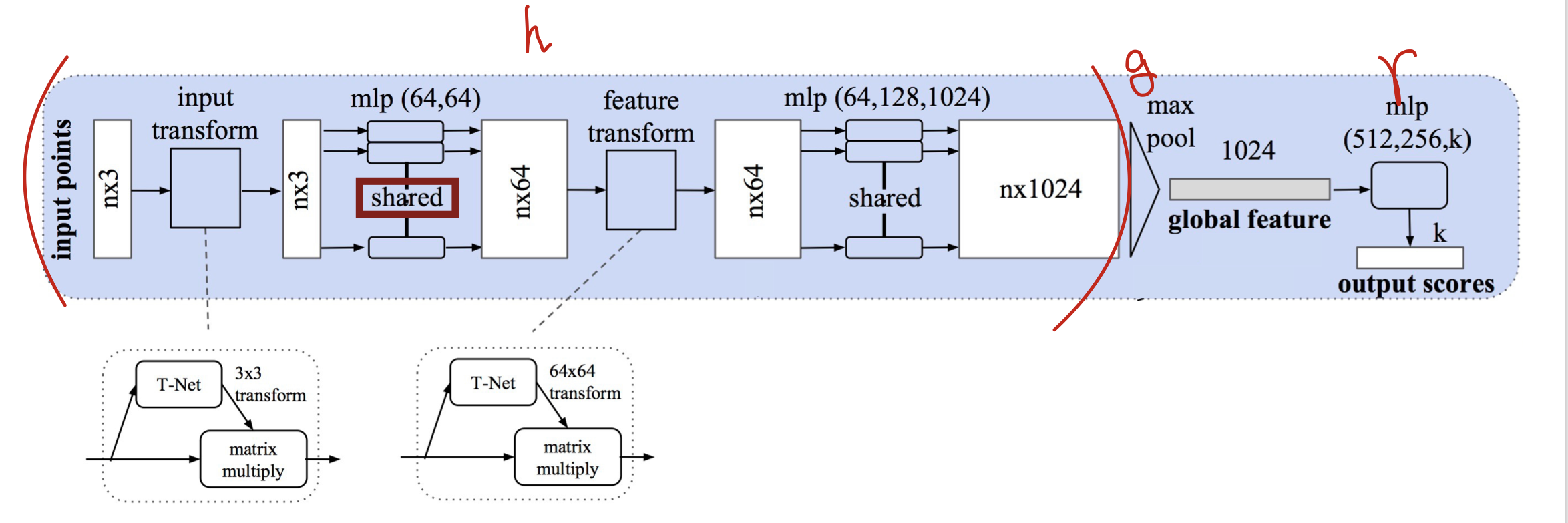
PointNet Architecture
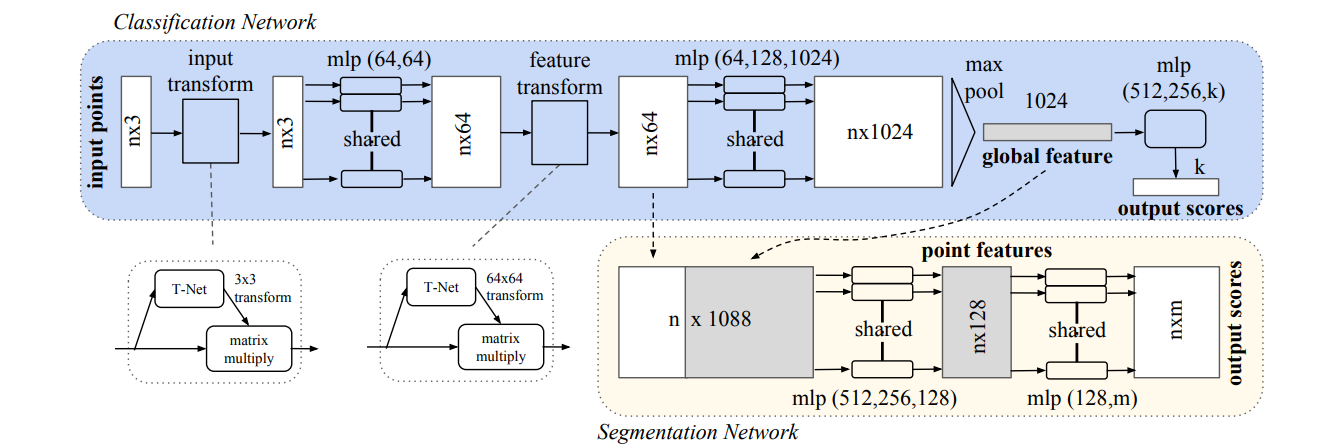
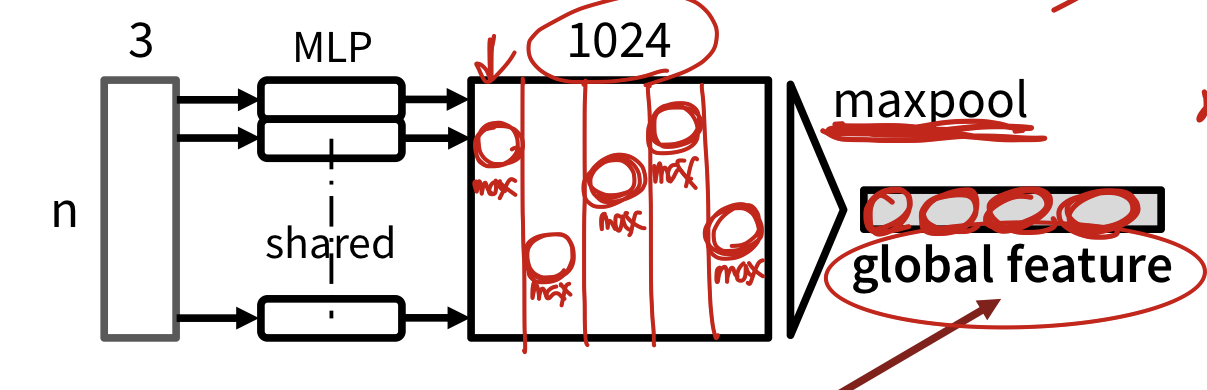
Classification Network
- takes n points as input
- applies input and feature transformation
- aggregate point features by max pooling
- output: classification scores for k classes
Segmentation Network
(extensions to the classification net)
1. concatenate global and local features
2. outputs per point scores
Key to PointNet Approach
-
use of a single symmetric function, maxpooling.
1-1) Effectiely the network learns a set of optimization functions that select interesting points of the point cloud.
1-2) encode the reason for selection. -
Final Fully Connected Layers
aggregate learnt optimal values into the global descriptor for the entire shape or are used to predcit per point labels.
PointNet Architecture's 3 key modules
1. A Universal Continuous Set Function Approximator
Max-Pooling layer as a symmetic function(r) to aggregate information from all the points for Unordered Input.
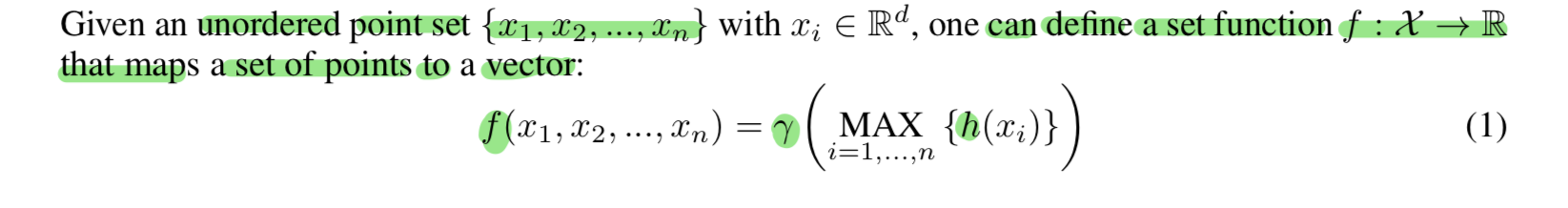
r and h are multi-layer perceptron(MLP) networks.
The set function F is invariant to input point permutations and can arbitrarily approximate any continuous set function.
Note that the response of h can be interpreted as the spatial encoding of a point.
Through a collection of h, we can learn a number of f 's to capture different properties of the set.
2. Local and Global information Aggregation
After computing the global point cloud feature vector, feed it back to per point features by concatenating the global feature with each of the point features.
Then extract new per point features based on the combined point features
(This time, the per point feature is aware of both the local and global info)
With this modification, PointNet is able to predict per point quantities that rely on both local geometry and global geometry.
3. Joint Alignment Network
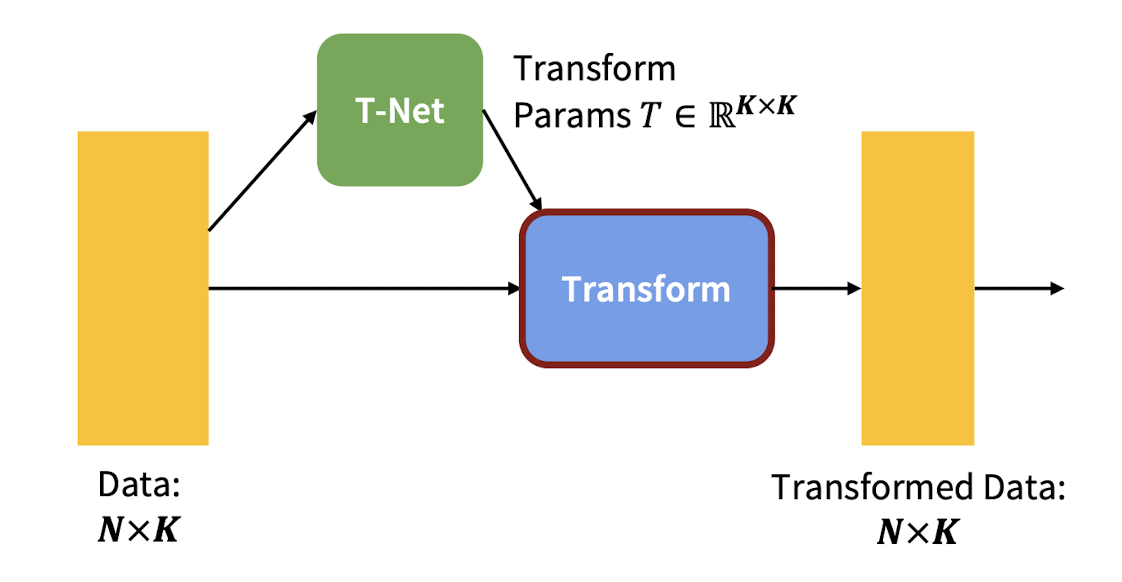
Extra neural network(T-Net) which is taking input data, it predicts transformation somehow align all the input data in way we can minimize variation of input. e.g, Slightly rotated images of traffic sign
T-Net trys to allign input images, predicting best transformation.
This T-Net helps rest of networks in pipeline to get better results (improves accuracy) by minimizing variance of input data.
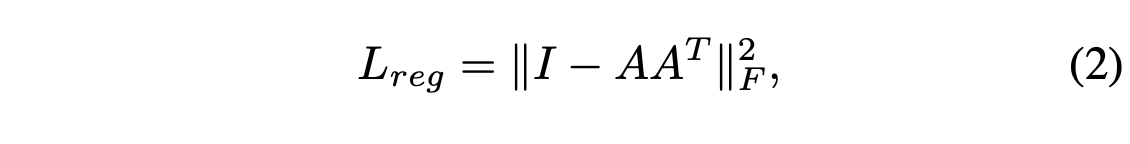 .
.
Regularization term to softmax training loss for dealing with greatly increasing the difficulty of optimization as transformation matrix in the feature space has higher dimension than spaicial transform maxtrix.
By adding regularization term,(Forcing output matrix A to satisfy ||I-AA^T||^2) the optimization becomes more stable, and achieves better performance.
A is the feature alignment matrix predicted by a T-net. An orthogonal transformation will not lose info in the input, thus is desired.
Robustnetss to Data Corruption
PointNet network picks max num (critical points) for each dimesion.
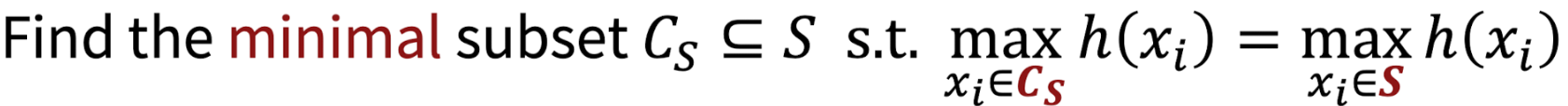
Therefore, points that are not in Critical Point Sets do not affect any change in output.

✏️ Limitations
Lack of the ability to capture local context at different scales.
PointNet has Only Two (Extreme) Layers!
one is learning features from single point (local feature)
and the other one is maxpooing, which learns from entire shape (global features)
In other words, PointNet uses a single max pooing operation to aggregate the whole point set.
However, in the case of CNN, it has multiple levels which gradually increases receptive field so that can learn features in multiple layers
➡️ Motivation of PointNet++
✅ Conclusion
- This paper proposes deep neural network PointNet that directly consumes point cloud.
- PointNet provides a unified approach to a number of 3D recognition tasks including object classification, part segmentation and semantice segmentation, while obtaining on par or better results than state of the arts on standard benchmarks.
- PointNet uses max-pool operations to extract global shape features, and the technique is widely used as an encoder for point generation networks.
