ML For 3D Data
1.PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
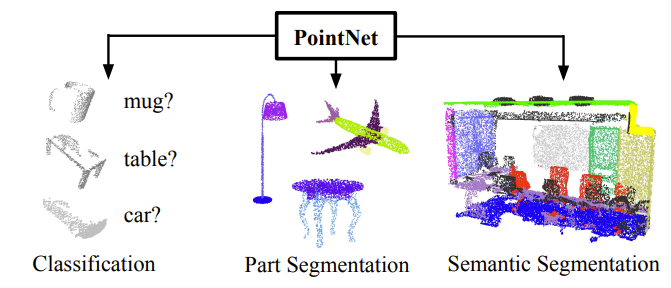
Most researcher transform Point Cloud data to regular 3D voxle grids or collections of images to perform weight sharing and kernerl optimizations due
2.PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
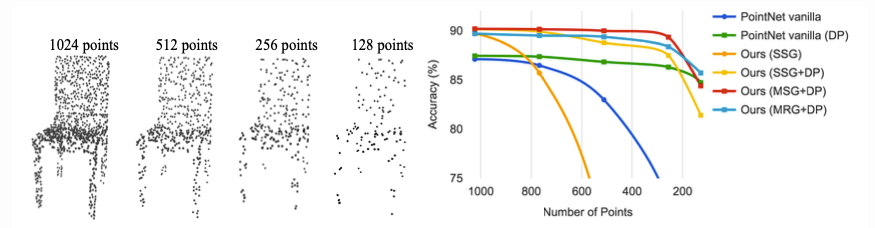
🚀 Motivations PointNet does not capture local structures induced by the metric space points live in, limiting its ability to recognize fine-grained p
3.Dynamic Graph CNN for Learning on Point Clouds
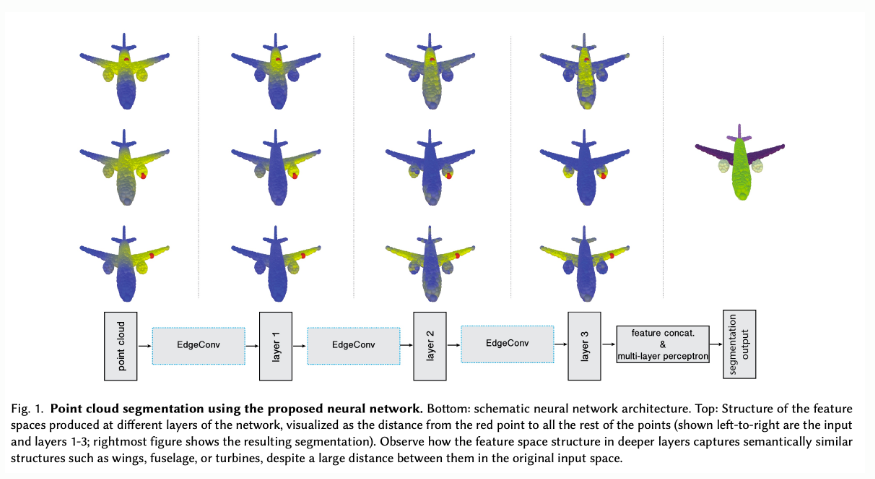
State-of-the-art deep neural networks are designed specifically to handle the irregularity of point clouds, directly manipulating raw point cloud data
4.A Point Set Generation Network for 3D Object Reconstruction from a Single Image

🚀 Motivations🔑 Key Contribution🤔 Problem Statement⭐ MethodsThis paper suggests each 3 version of PointOutNet.✅ Conclusion
5.Learning Representations and Generative Models for 3D Point Clouds

Recents attempts to encode 3D geometry for use in deep learning include view-based projections, volumetric grids and graphs.➡️ This paper focuses on t
6.DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
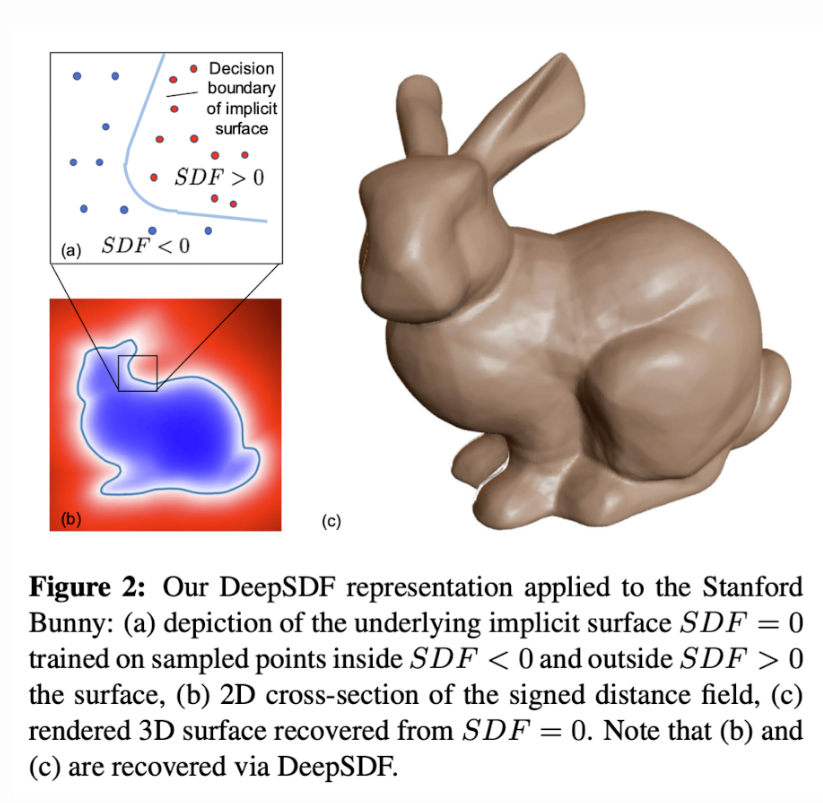
Classical and compact surface representations such as triangle or quad meshes pose problems in training beacause possible needs to deal with an unknow
7.Learning Implicit Fields for Generative Shape Modeling

In generative modeling of 3D shapes, the shapes produced by SOTA methods still fall far short in terms of visual quality.This is reflected by a combin
8.Occupancy Networks: Learning 3D Reconstruction in Function Space
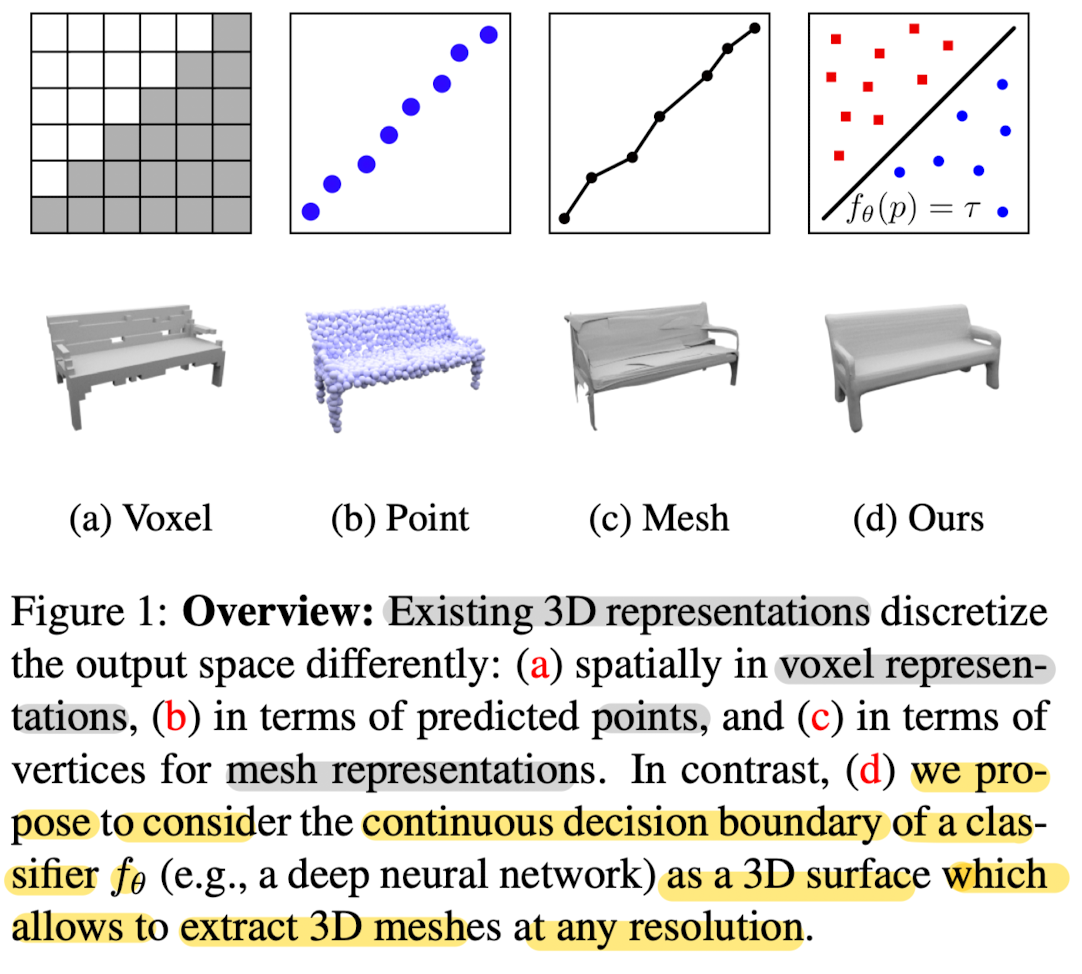
Unlike for images, in 3D there is no canonical representation which is both computationally and memory efficient yet allows for representing high-reso
9.Deep Meta Functionals for Shape Representation
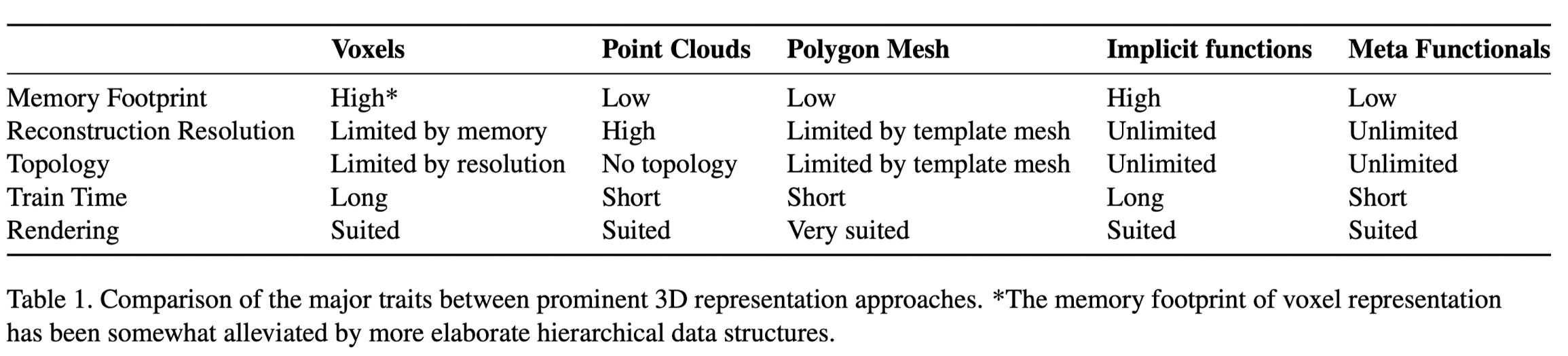
Existing categories for 3D representations (voxel, polygon meshes, point clouds) all suffer from different drawbacks and present differenet disadvanta
10.PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitzation
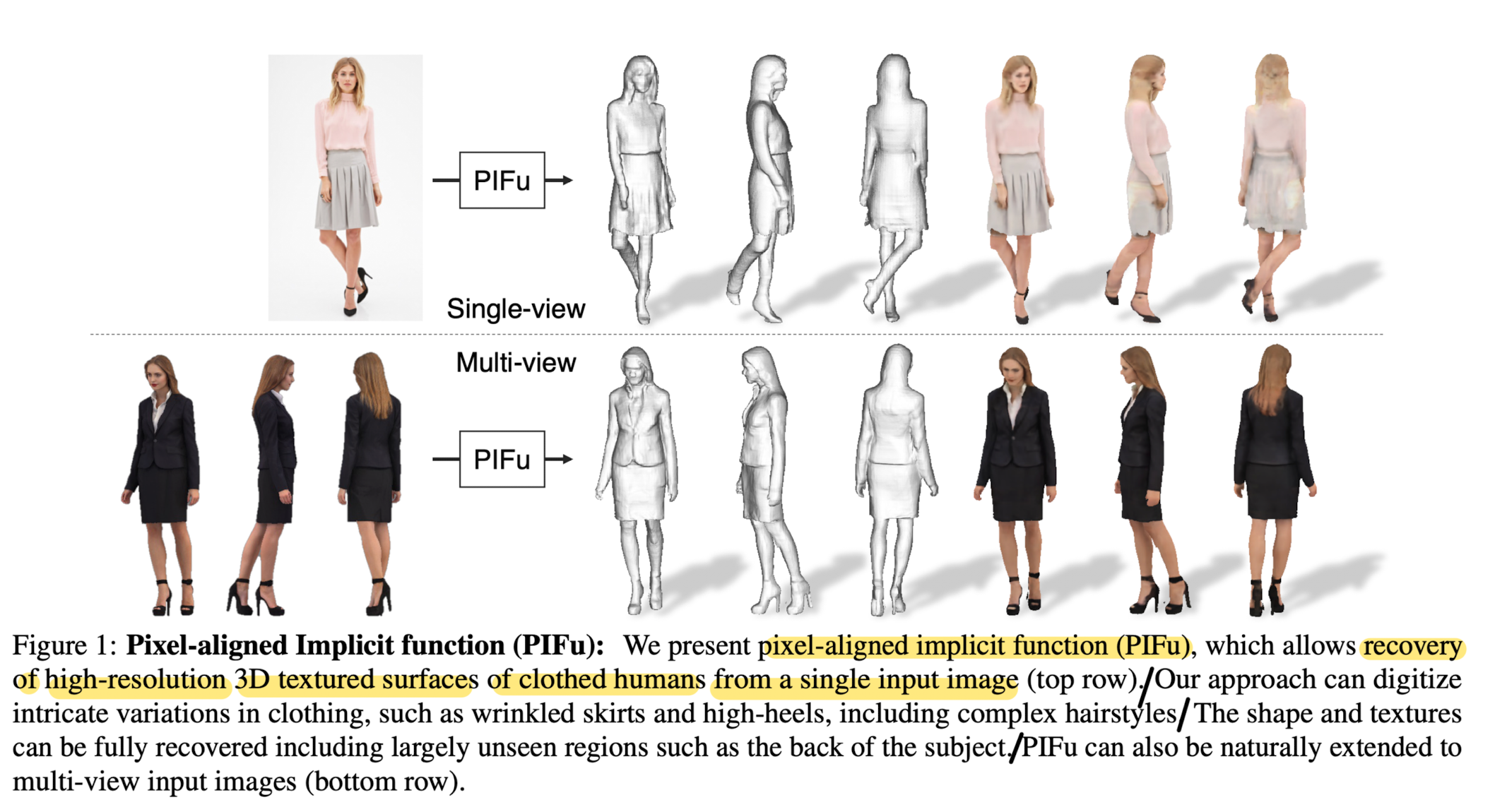
Recent 3D deep learning methods infer general shapes from very few images, even a single input. However, the resulting resolutions and accuracy are li
11.DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction

While many single-view 3D reconstruction methods that learn a shape embedding from a 2D image are able to capture the global shape properties, they ha
12.Implicit Neural Representations with Periodic Activation Functions

Current network architectures for such implicit neural representations are 1) incapable of modeling signals with fine dietail, 2) fail to represent a
13.Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
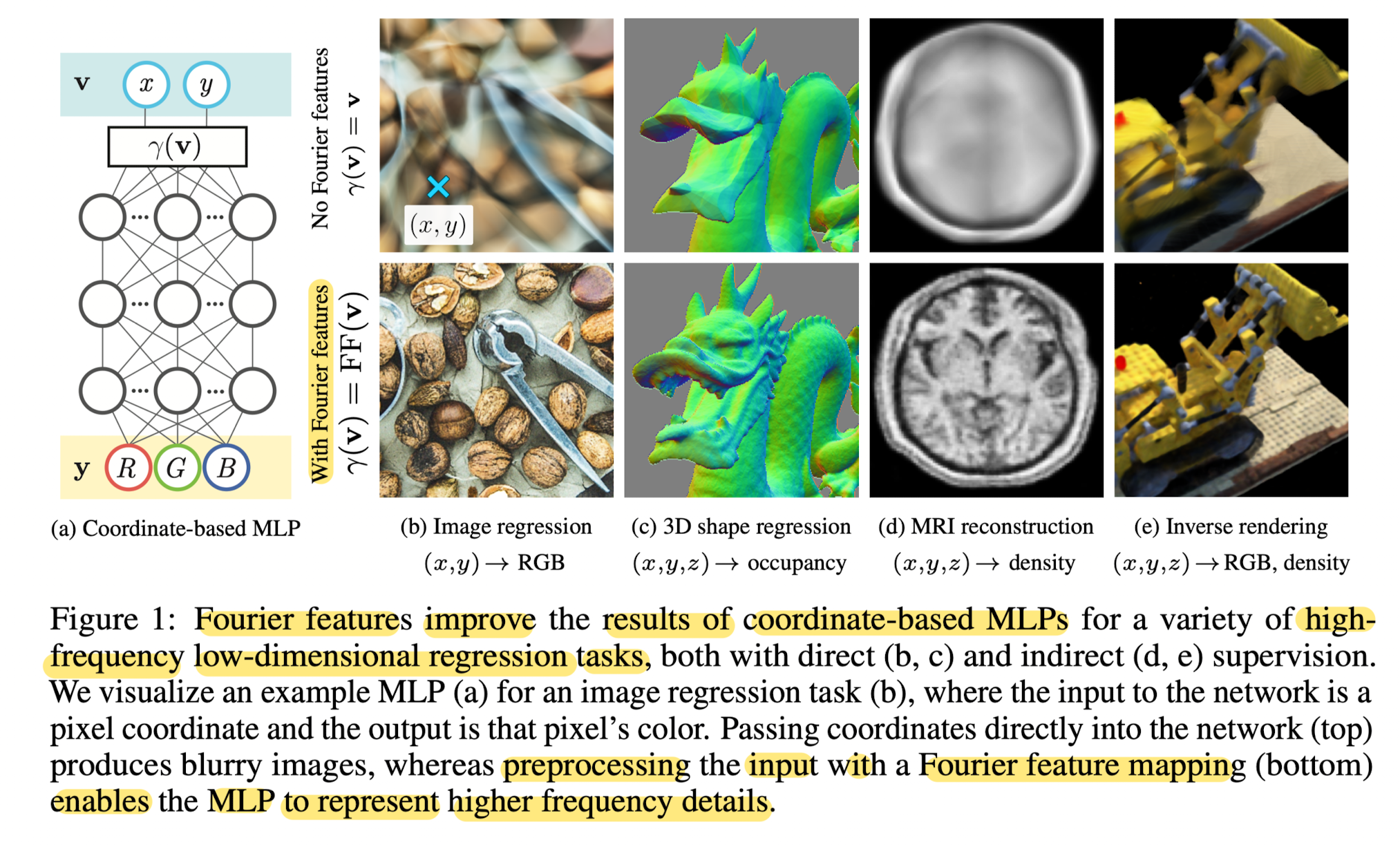
Motivations standard MLPs are poorly suited for low-dimensional coordinate-based vision and graphic tasks.MLPs have difficulty learning high frequency
14.DeepVoxels: Learning Persistent 3D Feature Embeddings
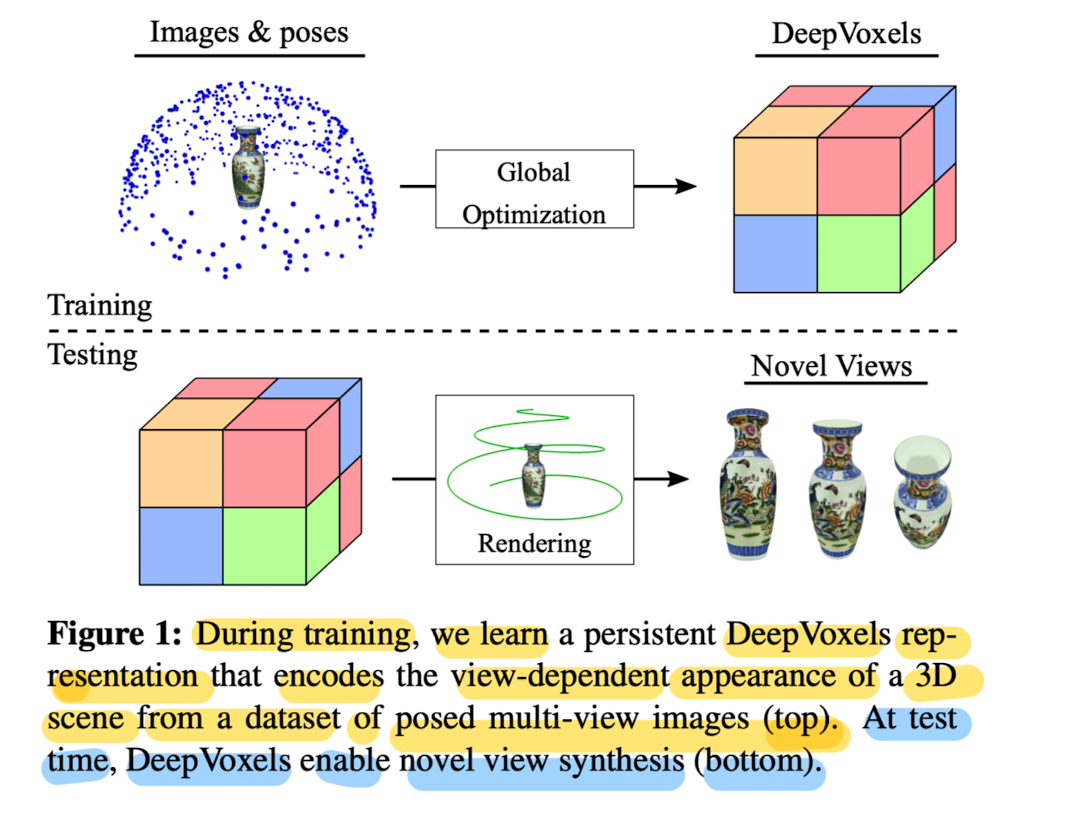
Lack of 3D understating of generative neural networks by introducing a persistent 3D feature embedding for view synthesis.While Techniques based on ex
15.Neural Volumes: Learning Dynamic Renderable Volumes from Image
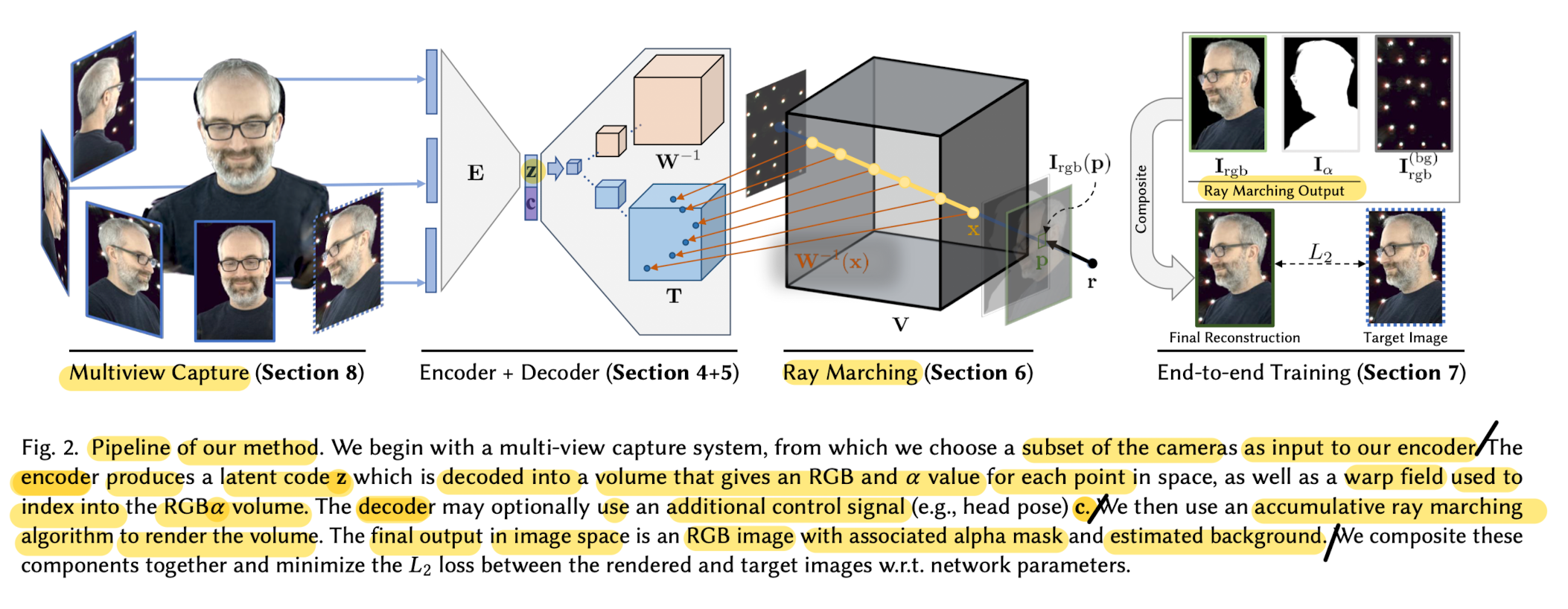
🔑 Key Contributions This paper presents an end-to-end pipeline for rendering images from novel views with only image supervision that leverages an in
16.NeRF: Representing Scene as Neural Radiance Fields for View Synthesis

This paper presents a method forsynthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene functionusing a spa
17.Deep Functional Dictionaries: Learning Consistent Semantic Structures on 3D Models from Functions
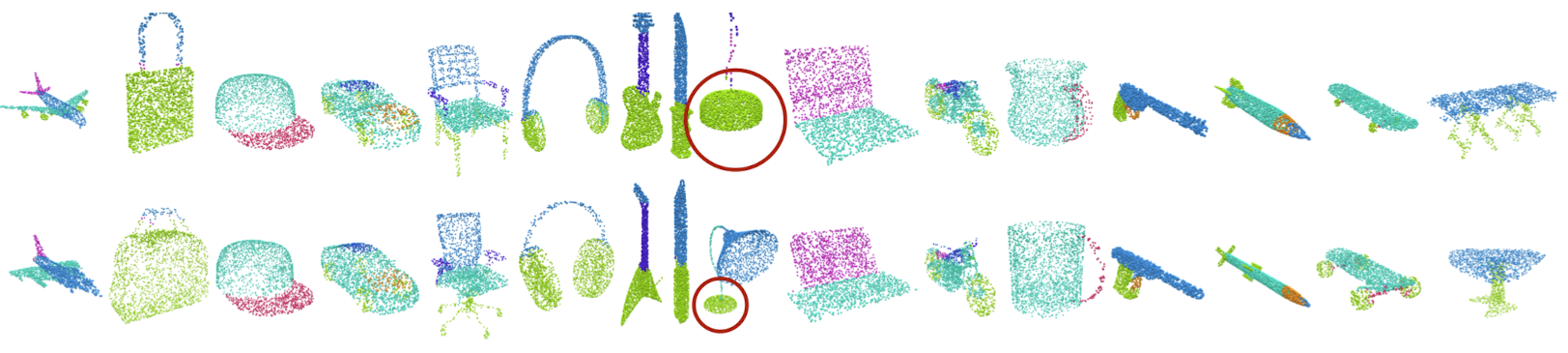
🚀 Motivations3D semantic attributes (such as segmentation masks, geometric features, keypoints, and materials) can be encoded as per-point probe func
18.AdaCoSeg: Adaptive Shape Co-Segmentation with Group Consistency Loss
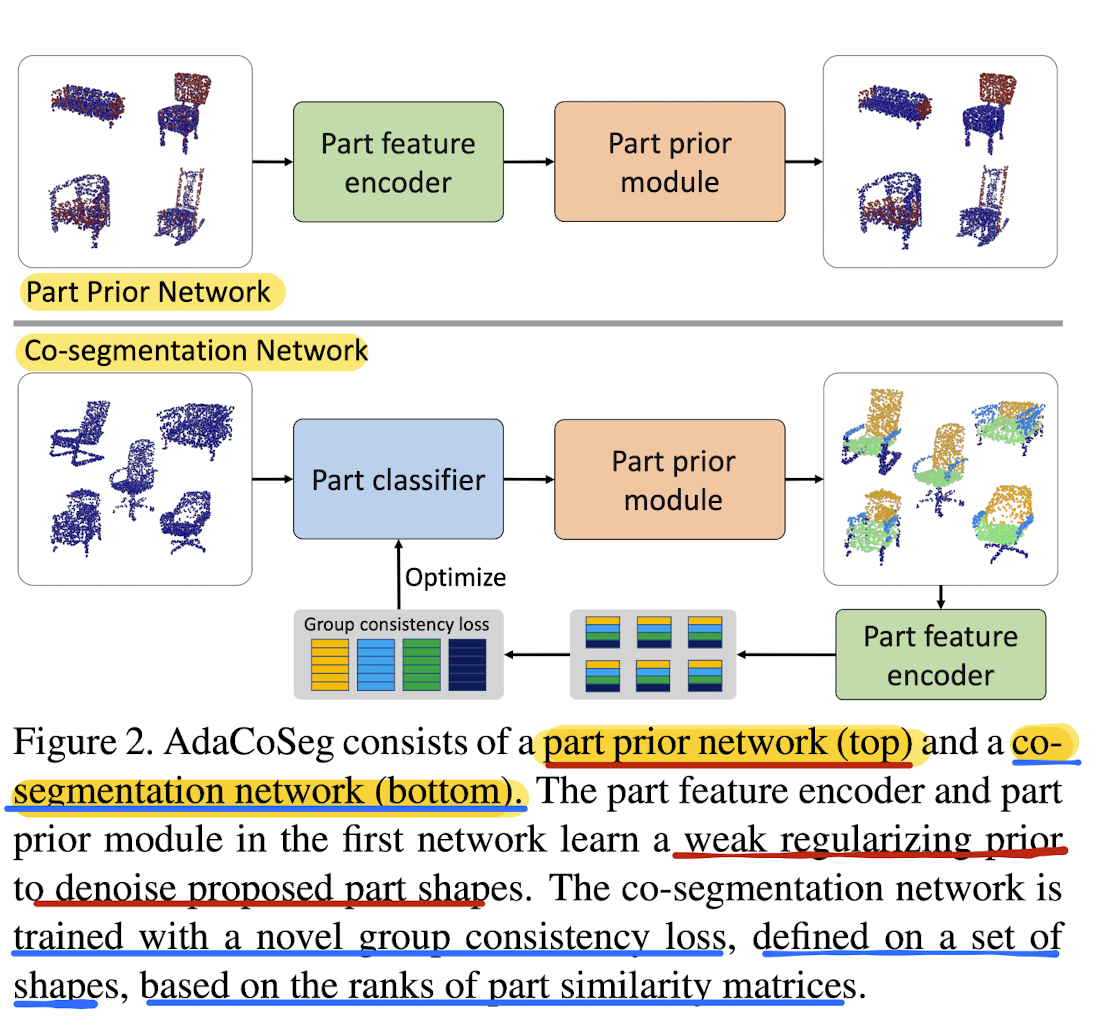
Co-segmentation is intrinsically contextual: how a shape is segmented can vary depending on the set it is in.➡️ Paper's network features an adaptive l
19.BAE-NET: Branched Autoencoder for Shape Co-Segmentation
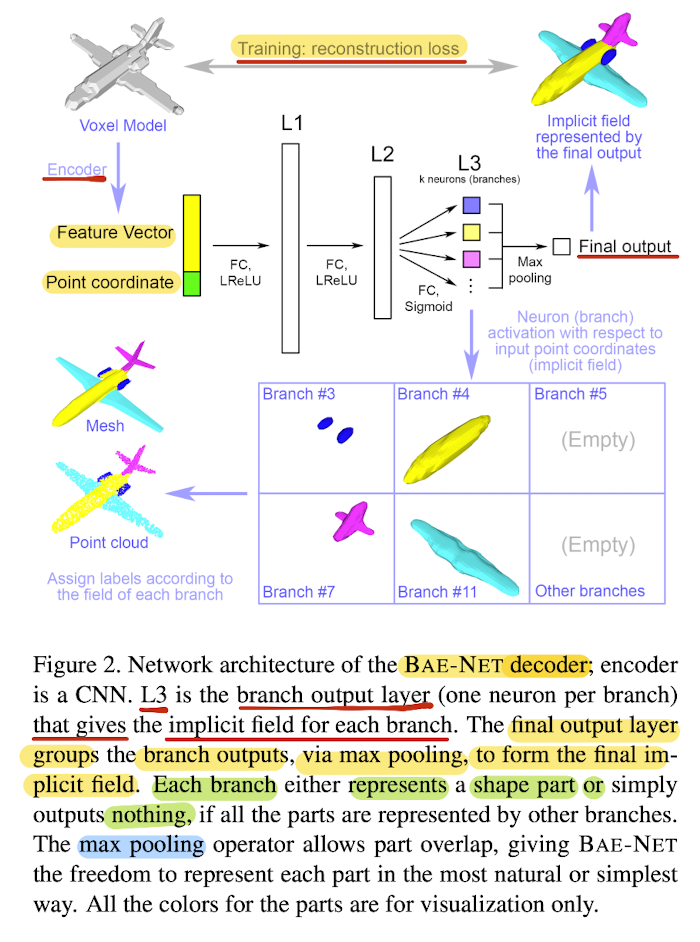
🚀 Motivations🛩️ Approach🔑 Key Contributions⭐ Methods👨🏻🔬 Experimental Results
20.Deep Hough Voting for 3D Object Detection in Point Clouds
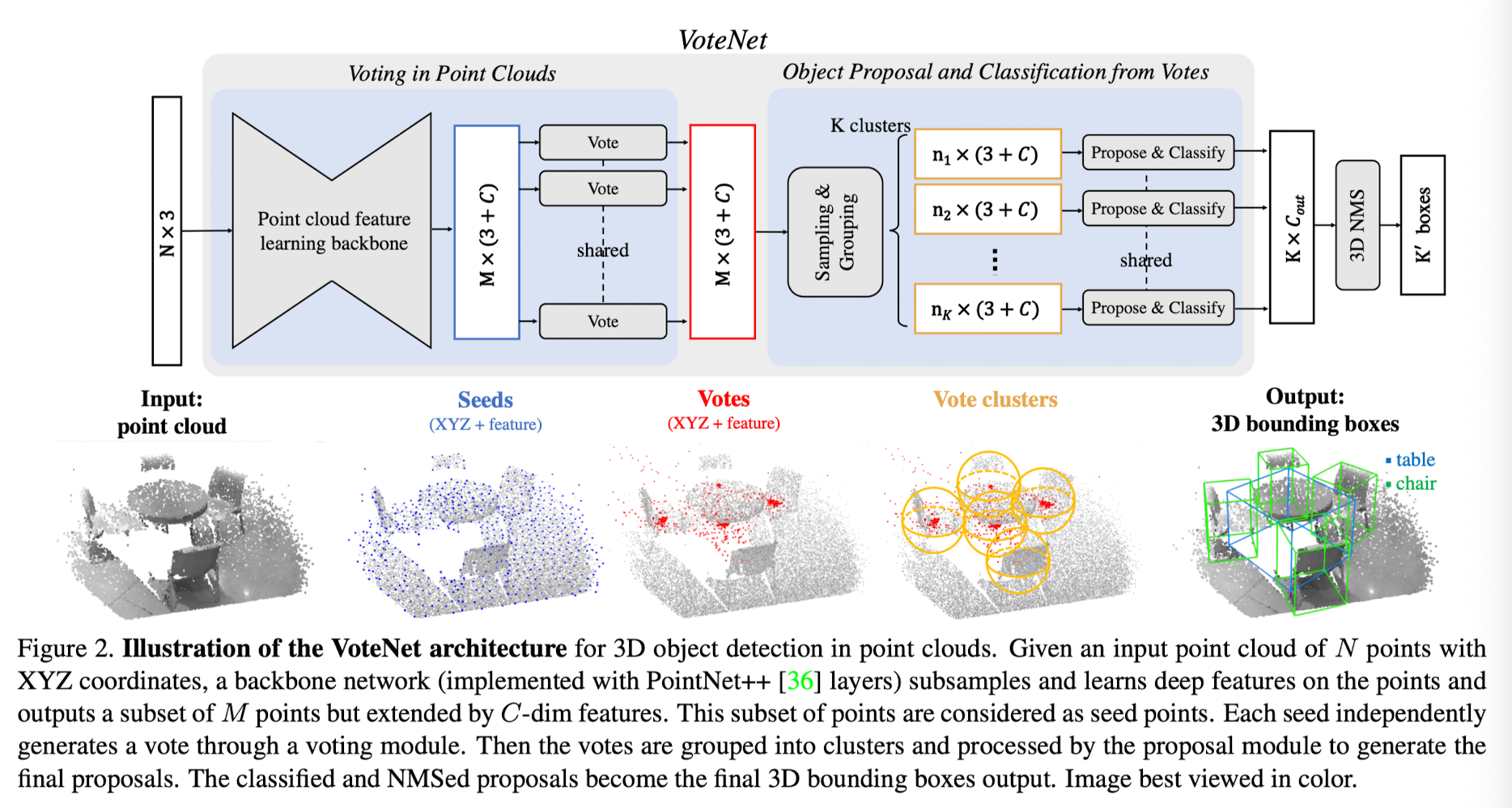
Current 3D object detection methods are heavily influenced by 2D detectors.In order to leverage architecture in 2D detectors, they often conver 3D poi
21.ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
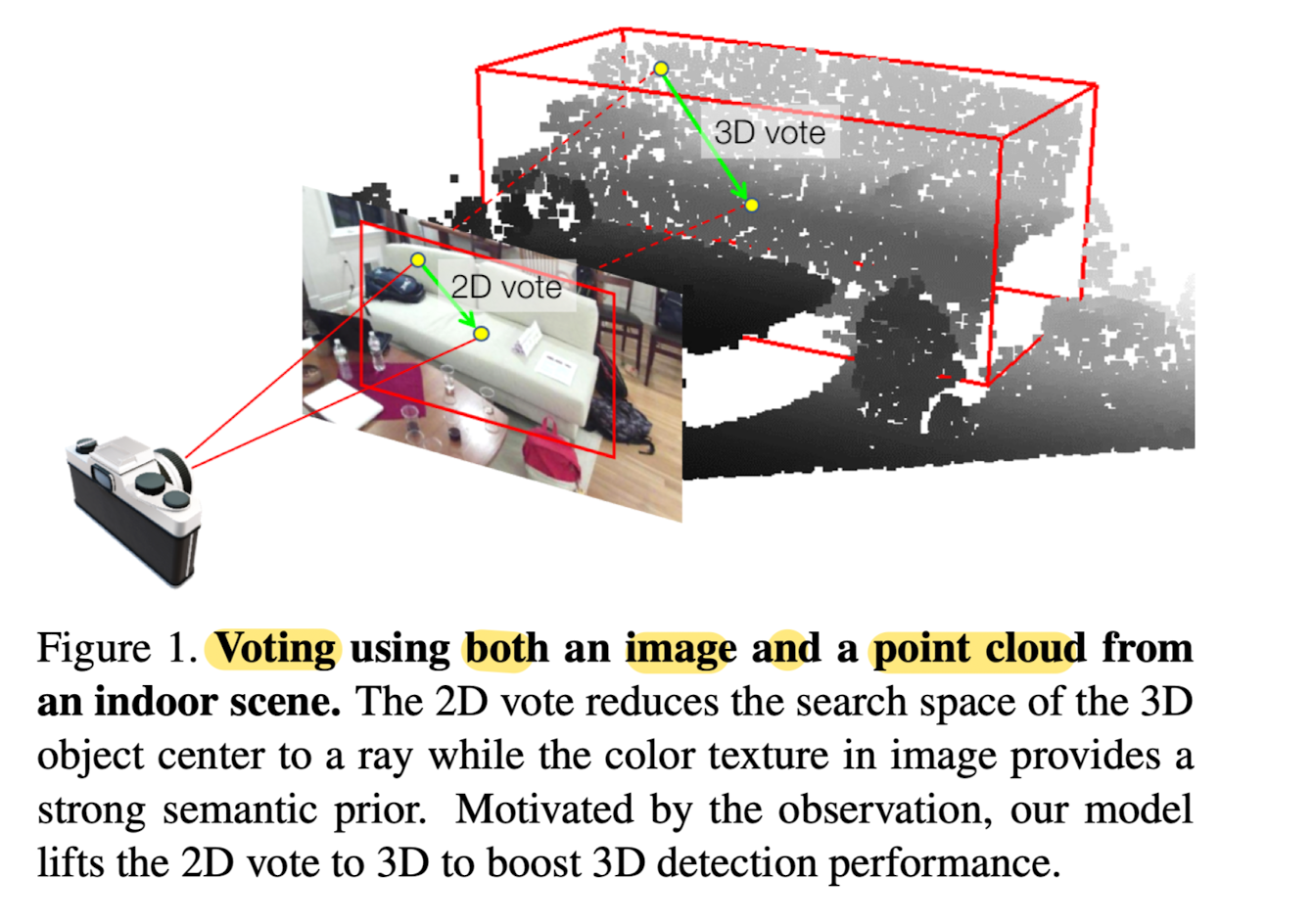
🚀 Motivations 1️⃣ Few recent works have SOTA performance with just point clouds input (e.g. VOTENET) VOTENET showed remarkable improvement for indoor object recognition compared with previous works ...
22.PointGroup- Dual-Set Point Grouping for 3D Instance Segmentation
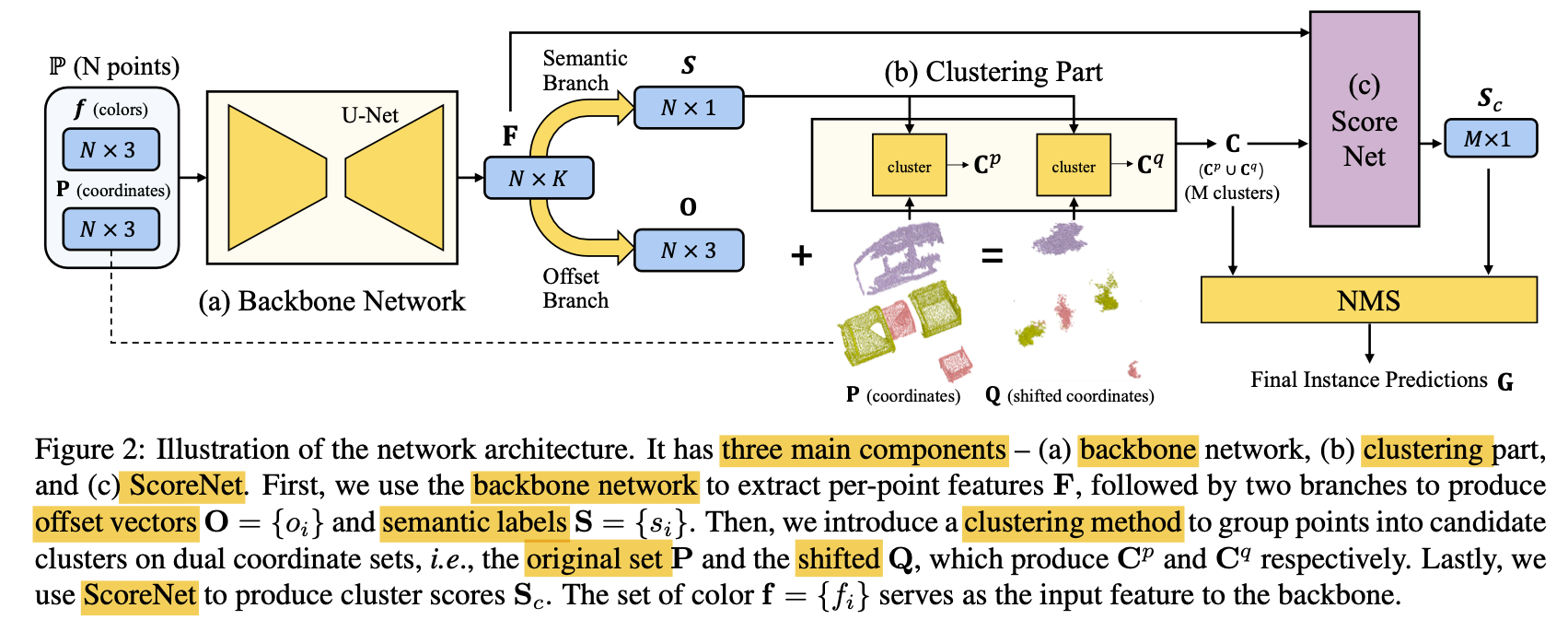
🚀 Motivations CNN has boosted the performance of 2D segmentation. However, given unordered and unstructured 3D point clouds, 2D methods cannot be dir
23.BSP-Net: Generating Compact Meshes via Binary Space Partitioning
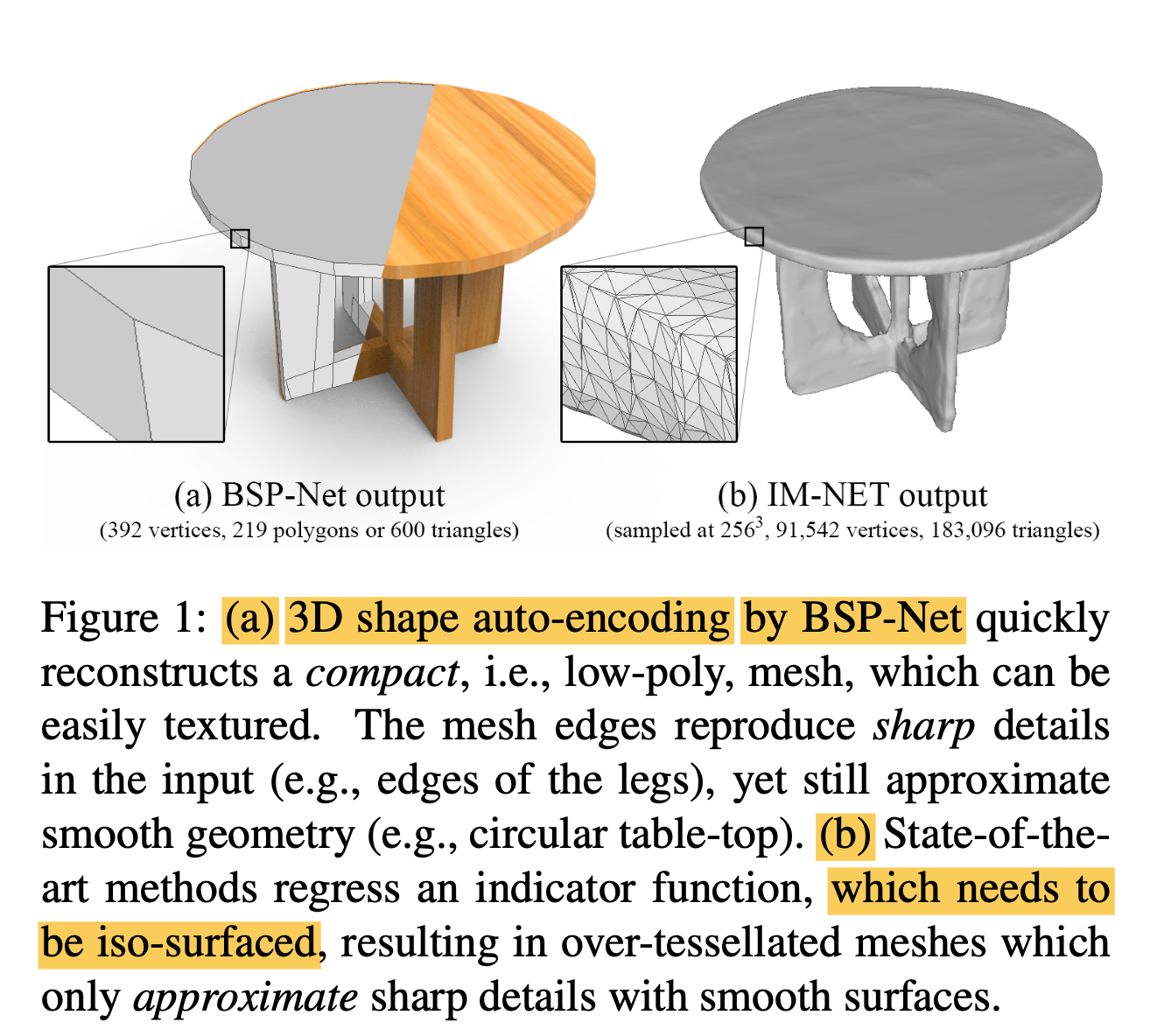
🚀 Motivations Polygonal meshes are ubiquious in the digital 3D domain, yet a minor role in deep learning revolution. Leading methods for learning ge
24.CvxNet: Learnable Convex Decomposition
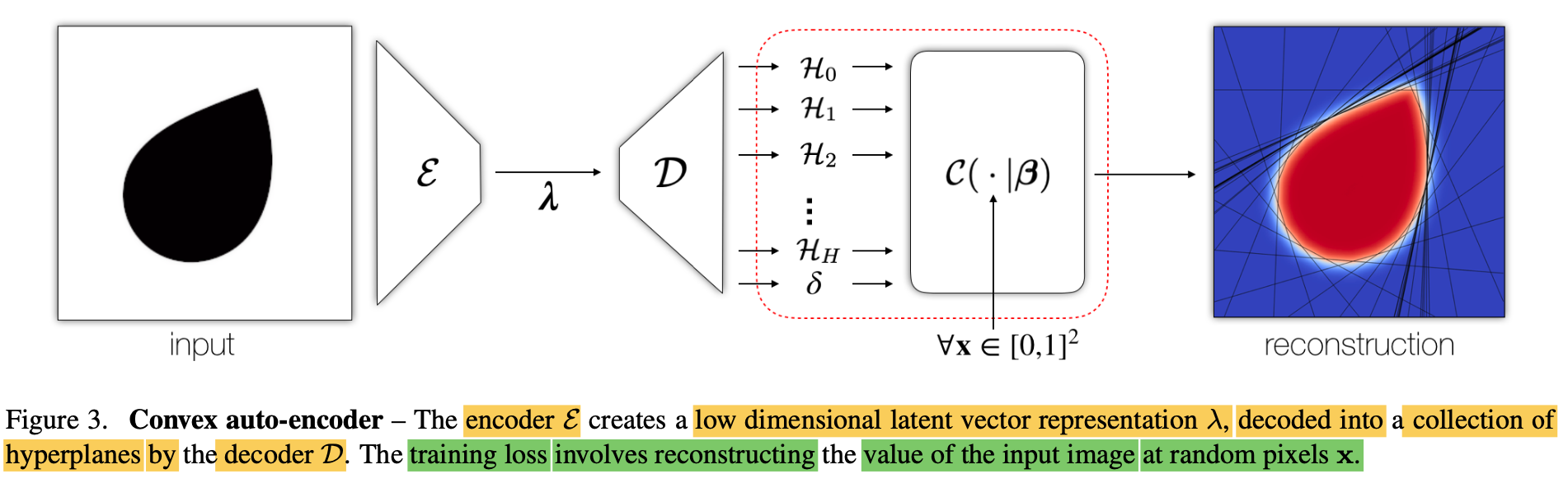
🚀 Motivations Any solid object can be decomposed into a collection of convex polytopes (in short, convexes). This decomposition is fundamental in co
25.UCSG-NET - Unsupervised Discovering of Constructive Solid Geometry Tree
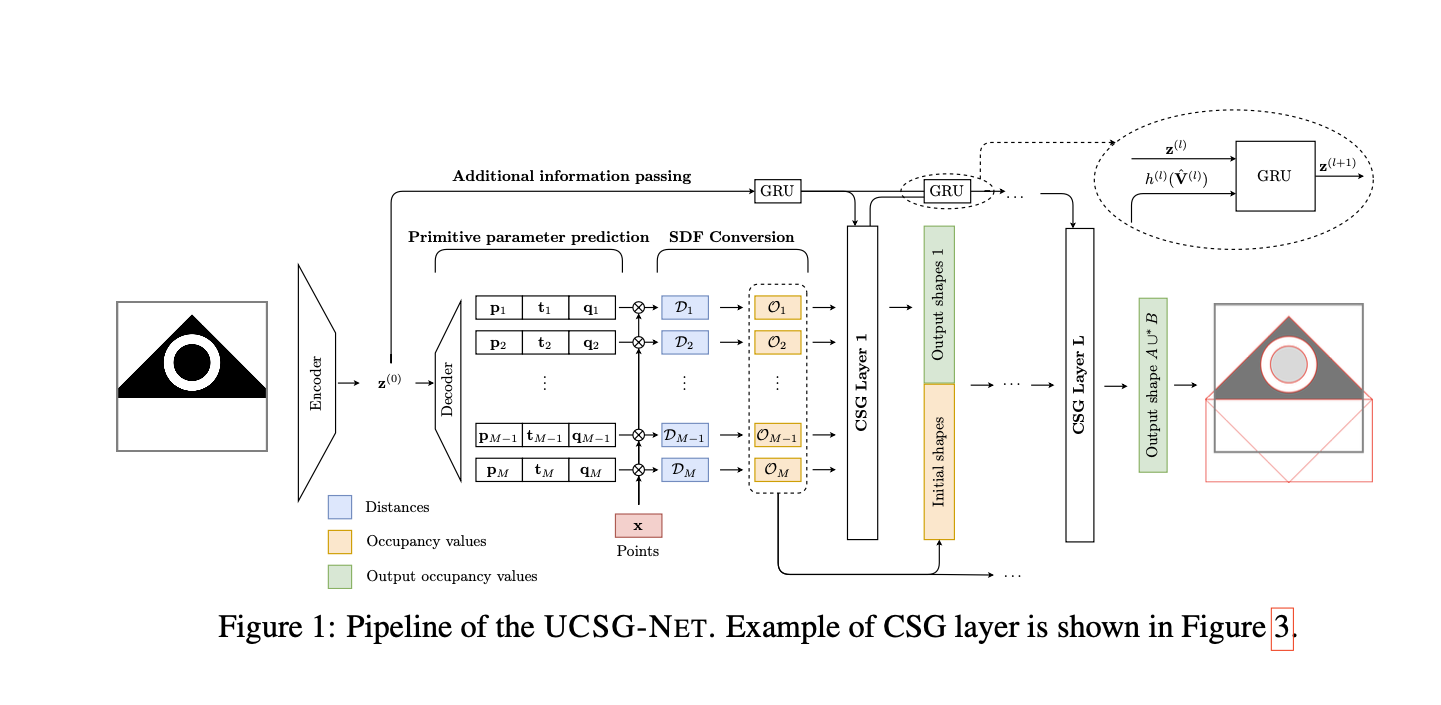
Methods based on SDF struggle to reconstruct non-convex shapes.One remedy is to incorporate a CSG(constructive solid geometry) frameworkthat represent
26.CSG-Stump: A Learning Friendly CSG-Like Representation for Interpretable Shape Parsing
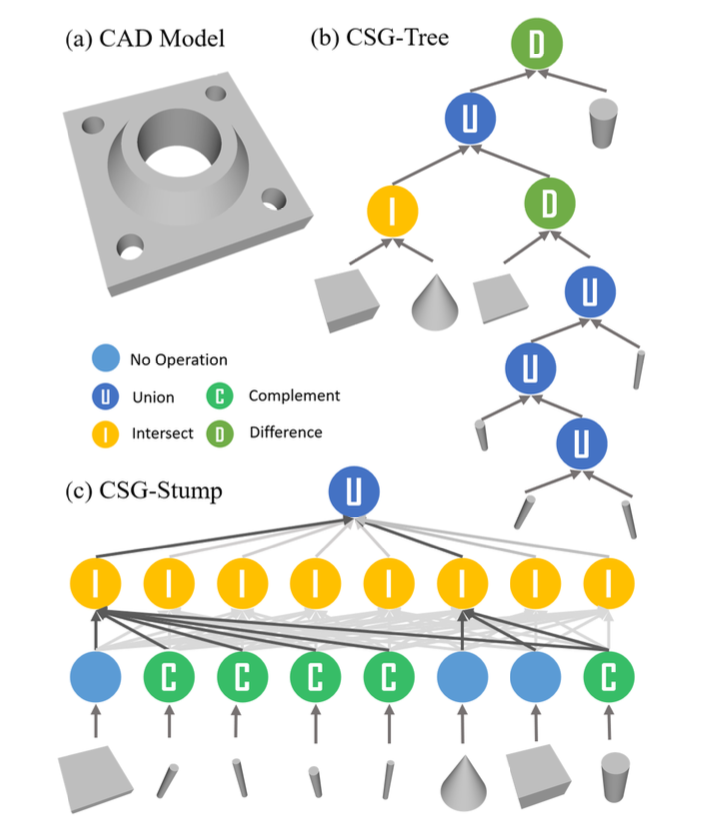
Generating an interpretable and compatrepresentation of 3D shapes from point cloudis an important and challenging problem.✅ This paper presents CSG-
27.🥗 SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
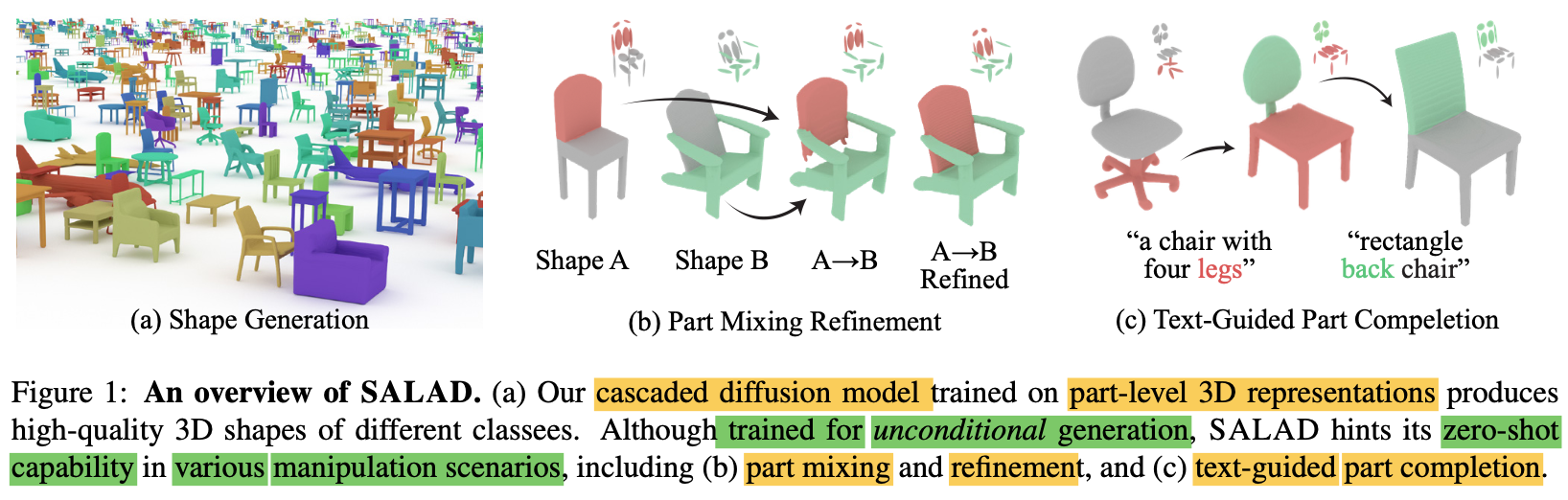
Author: Juil Koo, Seungwoo Yoo, Minh Hieu Nguyen, Minhyuk SungRecent research on 3D diffusion models has focuesd on improving their generation capabil