QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
Quantization[논문핵심]
문제 정의
-
INT4 quantization 기술은 low-batch 환경의 edge LLM inference에서만 가속화를 제공하며, large-batch 기반의 cloud-based LLM serving에서는 성능 이점을 제공하지 못하고 있음.
-
기존 INT4 quantization 방법은 GPU에서 weight 또는 partial sum의 dequantization 과정에서 상당한 runtime overhead(20–90%)를 초래하는 중요한 문제를 발견함.
Insight
QoQ (QoQ는 4-bit weight, 8-bit activation, 그리고 4-bit KV cache로 quantize)
-
QoQ의 핵심 insight는 GPU에서 LLM serving의 효율성이 low-throughput CUDA core에서의 연산에 의해 크게 영향을 받는다는 점.
-
이 insight를 바탕으로, QoQ 알고리즘에서는 W4A8 GEMM에서 dequantization overhead를 줄일 수 있는 progressive quantization을 도입.
-
또한, 4-bit KV quantization으로 인한 accuracy degradation을 효과적으로 완화하기 위해 SmoothAttention을 개발
QServe (W4A8KV4 quantization을 위한 효율적인 system support를 제공)
-
QServe 시스템에서는 compute-aware weight reordering을 수행하며, register-level parallelism을 활용하여 dequantization 지연 시간을 줄임.
-
또한, fused attention을 memory-bound로 만들어 KV4 quantization이 가져오는 성능 향상을 극대화
얻어갈 Background 지식
-
SoTA integer quantization algorithms는 세 가지 category로 나눌 수 있다.
-
1) W8A8 (per-group) quantization,
2) W4A16 (per-channel weight + per-token activation) quantization,
3) W4A4 (per-group)d quantization. -
1)과 2)는 accuracy 측면에선 거의 Lossless에 가깝다.
-
반면, W4A4 quantization은 high-throughput 4-bit tensor core에 연산을 mapping 하여 더 높은 throughput을 제공할 것으로 기대되긴 하지만, 상당한 accuracy degradation을 초래한다.
-
그러나, W4A4에 기대했던 성능 향상이 현재 GPU 플랫폼 전반에서 일관되게 관찰되지 않았다.
예를 들어, SoTA W4A4 serving system인 Atom은 A100 GPU에서 Llama-2-7B [34] 모델을 실행할 때, TensorRT-LLM의 W4A16 및 W8A8 대비 20-25% 낮은 성능을 보였다. -
즉, 아직 research community에서 efficient cloud LLM serving을 위한 W4A16 및 W8A8보다 우수한 precision combination은 찾지 못했다
-
-
논문에서 제시하는 중요한 observation.
-
현재의 4-bit integer quantization methods는 최신 GPU에서 weight 또는 partial sum의 dequantization 과정에서 20%에서 90%에 이르는 상당한 overhead를 갖는다.
-
예를 들어,W4A16 quantization은 FP16 tensor core에서 연산을 수행하지만, weight는 INT4 형태로 저장되므로 GEMM kernel에서 weight dequantization이 필요하다.
-
반면, W4A4 quantization은 reasonable한 accuracy를 달성하기 위해 weight와 activation 모두에 per-group quantization을 적용하며,
sub-channel 단위로 FP16 scaling factor를 공유한다.
(💡 per-group quantization vs per-tensor quantization
per-tensor quantization: tensor의 모든 데이터에 동일한 scale과 zero-point를 적용.
per-group quantization: 데이터의 일부 group(예: sub-channel)에 대해 각각 고유한 scale과 zero-point를 적용하는 방식으로, 더 세밀한 조정 가능)
-
예를 들어, SoTA W4A4 quantization 방법인 QuaRot는 per-group quantization에서 per-channel quantization으로 전환할 경우 0.2 perplexity의 상당한 accuracy degradation을 보고했다.
-
이러한 per-group quantization 설계는
INT4 tensor core에서 생성된 "INT32 partial sum을 처리하기 위해"
"integer를 floating-point로 변환하는 dequantization이 필요"하며,
이는 W4A4 GEMM의 sequential main loop 내에서 느린 CUDA core에서 작동한다. -
특히 데이터 센터 GPU(A100 등)에서는 CUDA core에서의 연산이 INT4 Tensor core에서의 연산보다 50배 정도 비용이 많이 든다.
따라서, CUDA core에서의 overhead를 줄이는 것이 LLM serving에서 최적의 throughput을 달성하기 위해 중요합니다. -
💡 참고) CUDA core와 INT4 Tensor core의 차이
-
Tensor cores란 NVIDIA에서 개발한 Matrix Multiplication을 가속하는 처리 장치.
-
INT4 Tensor Core와 CUDA Core는 SM 내부에 존재하며,
각자 다른 hardware unit으로 구현됨. -
CUDA Core는 1 Core Clock에 하나의 FP32 연산을 수행하는 반면,
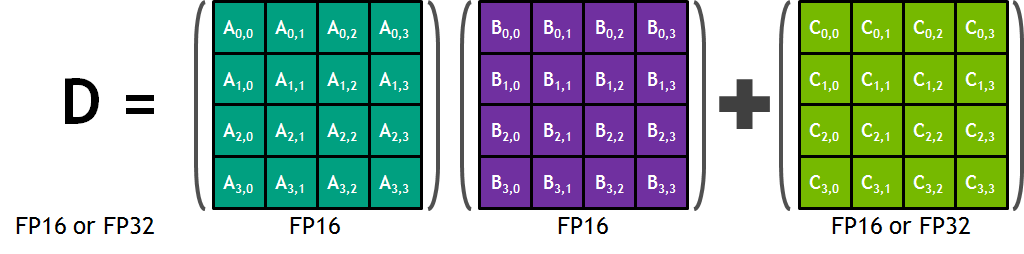
Tensor Core는 1 Core Clock에 4 x 4 크기의 FP16 matrix 두 개를 Multiply하고, 그 결과를 4 x 4 FP32 matrix에 add하는 Matrix multiply-accumulate 연산(A와 B를 곱하고 C를 더하는 과정을 하나의 연산으로 수행)을 수행.
-
CUDA core
- GPU의 범용(general-purpose) 연산 unit
- FP(FP32/FP64) 연산 및 INT(INT32) 연산 등을 처리.
- 일반적인 floaing-point 연산(FP32/FP64)에서 높은 성능,
low-bit integer 연산(INT4, INT8)에는 최적화되지 않음.
-
INT4 tensor core
- low-bit INT 및 matrix multiplication 연산에 최적화.
- INT4, INT8, FP16 등 low-bit 연산에서 높은 throughput을 제공.
-
추가 참고 자료: CUDA Cores vs Tensor Cores
-
-
Methods
1) Algorithm: QoQ
-
progressive group quantization 도입.
-
먼저 weight를 per-channel FP16 scales를 사용하여 8-bit로 quantize한 후,
이러한 8-bit 중간 데이터를 다시 4-bit로 quantize.
이를 통해 모든 GEMM 연산이 INT8 tensor core에서 수행되도록 보장함. -
KV4 quantization으로 인한 accuracy loss를 완화(mitigate)하기 위해 SmoothAttention을 도입.
- activation quantization의 challenge를 keys에서 queries로 shifting.
- queries는 quantization을 적용하지 않기 때문에 accuracy degradation을 최소화 할 수 있음.
-
2) System: Qserve
-
progressive group quantization의 protective range 를 활용하여,
INT4에서 INT8로 dequantization하는 과정에서 full register-level parallelism을 가능하게 함.
이를 위해 "subtraction after multiplication" computation order를 사용함. -
W4A8 GEMM 연산 중 CUDA core에서 발생하는 pointer arithmetic overhead를 최소화하기 위해, compute-aware weight reordering을 제안.
Experiments
- GPUs: A100 및 L40S
- QServe를 사용하여 일곱 가지 널리 사용되는 LLMs를 평가
- 비교 대상(SoTA system): TensorRT-LLM(FP16, W8A8, W4A16), Atom(W4A4), QuaRot(W4A4)
- Metric: throughput
