Quantization[논문핵심]
1.[핵심][20.04]AdaRound

기존$$\\underset{V}{\\text{argmin}} | \\bold{Wx} - \\bold{\\tilde{W}x}|^2_F $$AdaRound"optimize할 보조 변수 $\\bold{V}$를 도입"$$\\underset{V}{\\text{argmin}} |
2.[핵심][22.06]ZeroQuant

weight: group-wise, activation: token-wise, layer-wise Q + KD
3.[핵심] [22.08]Optimal Brain Quantizer

핵심 아이디어quantization 했을 때 , 전체 Loss에 최소로 영향을 주는 weight를 quantization하고, 나머지 weight들을 update 한다. (greedy하게 각 row 별로)위 과정을 각 row의 weight가 모두 quantization
4.[핵심][22.08]LLM.int8()

INT8 Matrix Multiplication for feed-forward and attention projection layers in Transformers(175B parameter).
5.[핵심][22.11]SmoothQuant

per-channel activation Q 대신, input activation을 per-channel smoothing factor $\\bold{s} \\in \\mathbb{R}^{C_i}$로 나누어 "smooth"하는 방법을 제안한다.
6.[핵심][23.03] GPTQ

OBQ: Qreedy하게 weight quantization, GPTQ: 그렇게 할 필요 없어~ 모든 row 동일하게 & 임의의 순서로 해도 돼~
7.[핵심][23.06]OWQ

activation outlier와 대응되는 weight는 Q하지 않고, 나머지 weight는 extreme Q.
8.[24.08]The Impact of Quantization on Retrieval-Augmented Generation: An Analysis of Small LLMs

LLMs LLaMA 3 - 8BZephyrOpenChatStarlingTasks & Datasets LaMP-3 "Personalized Product Rating"LaMP-5 "Personalized Scholarly Title Generation"Evaluation
9.[핵심]QLLM
mathematical equivalence를 이용해서 activation의 outlier magnitude를 weight로 transition하려는 이전 연구들의 시도의 한계다른 outlier보다 50배 이상 큰 activation outlier들의 경우, 이전 연구
10.[핵심][24.ICLR] RETHINKING CHANNEL DIMENSIONS TO ISOLATE OUTLIERS FOR LOW-BIT WEIGHT QUANTIZATION OF LARGE LANGUAGE MODELS
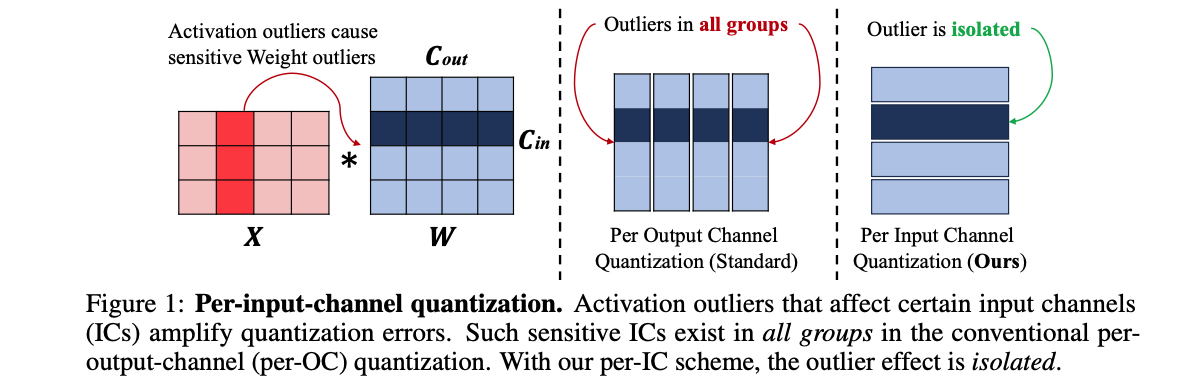
"activation outlier들을 다루는 방법으로, 기존의 output-channel(OC) 방향 대신, input-channel(IC) 방향으로 weight를 grouping해서, outlier들을 효과적으로 isolation 할 수 있다."observation
11.QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
W4A8KV4