🥗 SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
ML For 3D Data
Author: Juil Koo, Seungwoo Yoo, Minh Hieu Nguyen, Minhyuk Sung
(Project Page: https://salad3d.github.io/)
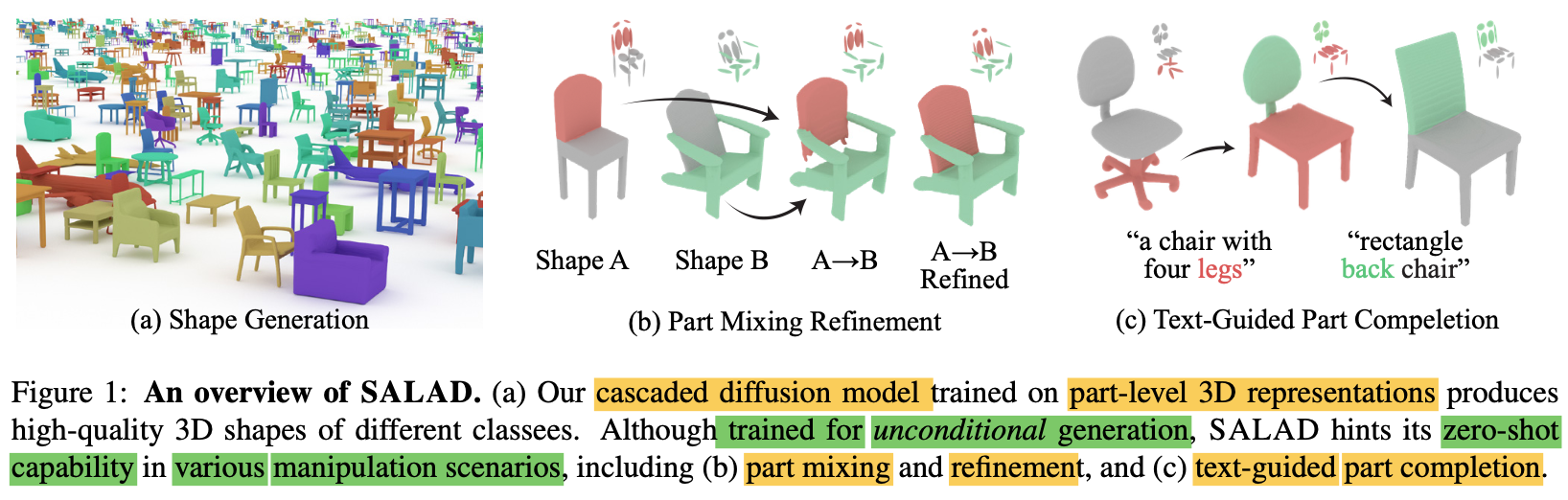
🖼️ Background
👑 Diffusion model is coming
-
Diffusion models have quickly replaced
existing generative models -
Key advantage of diffusion model: zero-shot capability
in completion & editing -
Recent research has shown that
diffusion models trained without any conditions
can be applied to completion & editing tasks
by starting the reverse process from partial data & properly guiding the process.
🥊 Challenge in applying Diffusion to 3D
-
"Finding an appropriate representation of 3D data"
-
To take full advantage of diffusion models,
both producing realistic data & being leveraged to editing and manipulation,
"careful design of 3D data representation" is needed. -
Implicit representation has been proven to be the best
to capture fine details
in 3D generation & reconstruction.
🔥 However, diffusion in a latent space
can't be used for "guided reverse process"
(e.g. filling a missing part of a shape while preserving the others)
thus, can't be used for manipultation tasks.
⭕ Author chose "Part-level" Disentangled implicit representation
-
✅ Authors present SALAD inspired by recent work
introducing disentangled implicit representations into parts
(specifically based on 🍝 SPAGHETTI (Amir et al)) -
👍🏻 Advantages of "part level" disentangled representation are
1) effectively allocating the memory capacity of the latent code to multiple parts
2) Locality allowing each part to be edited independently
👨🏻🏫 Thus, best fitted to authors purpose. -
Each part is described with
an independent embedding vector
describing the extrinsics and intrinsics of the part.
🔽
Thus, parts that need to be edited or replaced
can be easily chosen. -
It is a crucial difference from 'latent diffusion'
where latent codes do not explicitly express
any spatial and structural information & voxel diffusion
(where region to be modified can only be specified in the 3D space, not in the shape)
🚀 Motivations
-
Recent research on 3D diffusion models
has focuesd on improving their generation capabilities
with various data representation,
🔥 while the absence of structural information
has limited their capability in completion and editing tasks. -
Thus, Authors propose diffusion model
using a part-level implicit representation. -
To effectively learn diffusions
with "high-dimensional" embediing vectors of parts,
Authors propose a cascaded framework,
1) Firstly, Learning diffusion first
on a "low-dimensional" subspace encoding extrinsic parameters of parts
2) And then, on the ohter "high-dimenstional" subspace encoding intrinsic attributes.
🔑 Key Contributions
-
Present a cascaded diffusion model
based on a part-level implicit 3D representation. -
Achieves SOTA generation quality
and enables part-level shape editing and manipulation
without any additional training
in conditional setup.
👨🏻💻 Technical Contributions
-
Diffusion neural network
designed to properly handle
the characteristics of the "part-level implicit representation",
which is a set of high dimensional embedding vectors. -
1️⃣ Authors employ Transformer & condition each self-attention block with the timestep in the diffusion process.
to cope with the set data
and acheive permutation invariance
while allowing global communications across the parts. -
2️⃣ Authors introduce a two-phase cascaded diffusion model
To deal with challenge in learning diffusion in the high-dimensional embedding space,
which is known to be hard to train. -
Leverage the fact that
'part embedding vector' is split into
a small set of extrinsic parameters
approximating the shape of a part
&
a high-dimensional intrinsic latent
supplementing the detailed geometry information. -
Hence, paper's cascaded pipeline learns two diffusions,
one: generating extrinsic parameters first
and the other: producing an intinsic latent (conditioned on the extrinsics)
🔽
Effectively improving the generation quality
Future works
- Authors plan to investigate the diffusion models
on part-lever representations
with different primitives and parametrization for parts

That’s a good observation — the representation of 3D data really defines how effective diffusion models can be. Beyond the algorithms, the way characters and assets are structured plays a huge role in quality and adaptability. This is why collaboration with professionals who understand topology, rigging, and visual style is so valuable. A character design studio, for example, can provide models optimized not just for visuals but also for animation and integration, making them more suitable for both experimentation and production