Abstract
diffusion 모델은 획기적인 생성 성능과 vision applicaion에서 인기를 얻고 있다.
하지만, model size가 크고 iterative generation을 하기 때문에, high storage와 computation이 요구된다. 따라서 mobile device에서 사용되기 힘들다는 한계가 있다.
현존하는 quantization technique들은 8-bit precision에서 조차도 성능을 유지하는데 애를 먹고 있다. 그 이유는 diffusion 모델이 갖는 unique한 property인 activation에서의 temporal variation 때문이다.
이 논문에서는 time step 정보를 기반으로 quantization interval을 dynamically하게 조정(adjust)하는 quantization 방법을 제시한다.
다른 전형적인 dynamic quantization technique들과는 다르게,
이 접근은 inference 도중에 computational overhead를 더하지 않고,
PTQ와 QAT 방법 모두와 호환 가능하다.
Introduction
Diffusion 모델의 단점
model size가 gigabytes 단위로 크기 때문에, single image generation을 위한 iterative inference에 엄청난 computation이 요구된다.
따라서, 현존하는 diffusion model들은 resource-limited mobile devices에 실질적으로 사용되기에는 어렵기 때문에,
현재 대부분의 application들은 expensive, high-performance server들에 구현된다.
현재까지의 연구들
diffusion model의 computational cost와 memory requirement를 줄이면서, generative performance를 유지하는 여러 연구들이 제안 되었다.
DDIM, Classifier-free diffusion guidance는 효율적인 sampling scheduler를 제시했고,
Progressive distillation for fast sampling of diffusion models,
On distillation of guided diffusion models는 number of sampling steps를 줄이기 위해 knowledge distillation을 사용하는 연구를 제시했다.
결과적으로, high-fidelity image가 더 적은 sampling step들로 생성될 수 있었고,
diffusion model들을 더 affordable하고 feasible하게 사용할 수 있었다.
하지만 여전히 diffusion model들의 denoising process는 상당한 computational cost가 필요했다.
따라서 추가적인 성능 향상과 model compressiondl 필요하다.
현재까지 연구들과 다른 접근이 필요하다
대부분의 이전 연구들은 number of sampling steps를 줄여서 denoising process를 accelerate하는데에 집중했다.
하지만, 각각의 denoising step들을 가볍게 만드는 것 역시 중요하다.
각 denoising step은 다양한 model compression 기술이 사용될 수 있는 전형적인 딥러닝 모델의 inference로 볼 수 있기 때문이다.
전형적인 CNN과 language model들에 연구됐던 연구들은 diffusion model에 적용했을 때 상당한 성능 하락을 야기한다.
이는 diffusion model이 갖는 특성 때문인데,
iterative inference 과정에서 activation distribution이 크게 변하기 때문에
activation bit-width가 줄어들면 output이 매우 왜곡(distorted)되기 때문이다.
QAT와 PTQ를 포함한 현존하는 quantization 기술들은 현존하는 DNN들의 특정한 distribution을 다루기 위해 고안되었기 때문에,
diffusion model들의 time-variant activation distribution을 다루지 못한다.
본 논문의 연구 방향(TDQ)
위와 같은 diffusion model quantization이 갖는 unique한 challenge를 해결하기 위해,
본 논문은 TDQ(Temporal Dynamic Quantization) 모듈을 제시한다.
TDQ 모듈은 activation quantization error들을 최소화하는 time-dependent한 최적의 quantization configuration을 생성한다.
TDQ 모듈의 장점은 현존하는 QAT와 PTQ 알고리즘의 seamless한 integration이다.
위 알고리즘들을 확장해서 activation quantization error들을 최소화하는 time-dependent한 optimial quantization configuration을 생성하는 것이다.
특히, inference 과정에서 추가적인 computational overhead를 생성하지 않고,
현존하는 acceleration 프레임워크들과 추가적인 변형없이 호환이 가능하다.
TDQ 모듈은 각 time step마다 최적의 quantization parameter들을 생성하여,
quantization의 장점을 유지하면서 기존의 quantization의 quality를 뛰어넘는다.
Backgrounds and Related Works
Quantization
최종적인 quanlity는 quantization interval 또는 zero offset같은 quantization hyperparameters tuning에 따라 크게 달라진다.
low-precision에서 output의 quality를 유지하기 위해선,
model parameters뿐만 아니라, target task의 specific features와 requirements를 고려하여 quantization parameters를 update하는 것이 중요하다.
QAT & PTQ
-
QAT는 quantization operator 도입 이후에 추가적인 training을 하는 방법이다.
quantization operators의 영향을 고려한 final loss value를 최소화하도록
network parameters를 update한다.
PTQ는 quantization 이후에 end-to-end forward/backward propagation을 적용하지 않는다.
대신, quantization으로 야기된 block-wise reconstruction errors를 줄이는데 집중한다.
보통 QAT가 low-precison에서 PTQ보다 더 좋은 성능을 보이긴 하지만,
dataset deficiency나 training pipelines, resource constraints 같은 요인으로 인해 항상 그렇지는 않다.
실질적인 사용성(practical usefulness) 때문에, PTQ가 최근 많이 연구되고 있다.
diffusion model에서의 quantization 연구에서는
Post-training quantization on diffusion models 연구가 8-bit PTQ 연구를 제시하여, high-fidelity image generation 성능을 증명했다. -
대부분의 QAT와 PTQ 알고리즘은 static quantizaion에 집중돼있지만,
최근 연구는 input-depedent dynamic quantization을 highlight하고 있다.
Dynamic dual trainable bounds for ultra-low precision super-resolution networks
Insta-bnn: Binary neural network with instance-aware threshold
Content-aware dynamic quantization for image super-resolution
Instance-aware dynamic neural network quantization
Dynamic quantization은 activations의 다양한 input-dependent distribution을 기반으로
quantization intervals를 조정(adjustment)할 수 있다.
그리고 이를 통해 quantization error를 줄일 수도 있다.
하지만, 구현에 있어서 activations에서 statistical information을 추출하는 데에 추가적인 costs가 발생하여, 실전에서의 성능 향상을 이루는데에는 challenge가 있다.
이전의 연구들에서 diffusion model들의 sampling process를 acclerate하기 위해 다양한 방법들이 제시되었지만,
diffusion model의 dynamic nature를 exploit하기 위한 연구는 제한적이었다.
이 논문에서는, diffusion model의 time step information을 기반으로 적합한 quantization interval을 생성하여,
activation quantization error를 최소화하는 quantization scheme을 제안한다.
Temporal Dynamic Quantization(TDQ)
Quantization Methods
이 연구에서 사용된 quantization function은 다음과 같이 정의한다.
본 연구에서는 possible quantization levels들이 evenly spaced된 bit linear quantization에 focus한다.
Linear quantization은 두 가지 key hyperparameters를 가진다.
1) quantization interval
2) zero offset
full-precision data 가 주어졌을 때,
quantized data 는 다음과 같이 연산된다.
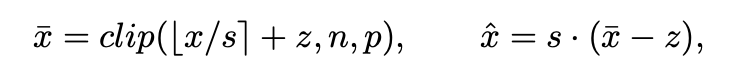
여기서 는 smallest(largest) quantization index,
은 clippin function
은 rounding function을 의미한다.
실질적인 accerlation을 목적으로, weights에는 symmetric quantizaion를 사용했다.
(where, and )
반면, activation quantization에는, 35에 흔히 채택되는
asymmetric quantization을 가정했다.
(where )
Challenges of Diffusion Model Quantization
-
diffusion modele들을 quantizing하는데 가장 큰 challenge는
quantization error를 최소화하는 activation을 위한
최적의 quantization parameters(와 )를 찾는 것이다. -
아래 Fig 2에서 볼 수 있듯,
diffusion model의 activation distribution은
iterative denoising process로 인해서
layer index에 무관하게 distribution이 time step 에 의존해 굉장히 다양한(highly varies) unique property를 갖고 있다.
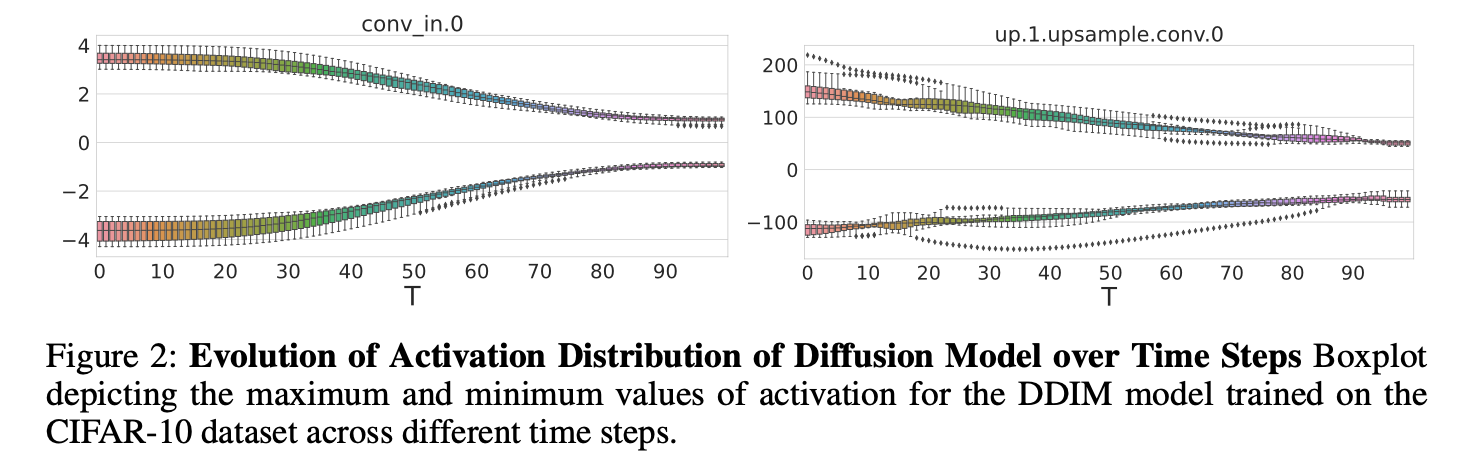
따라서, quantization parameters로 static values를 사용한다면,
Fig 3처럼 각기 다른 time steps에서 중대한 quantizawtion error를 야기할 수 있다.
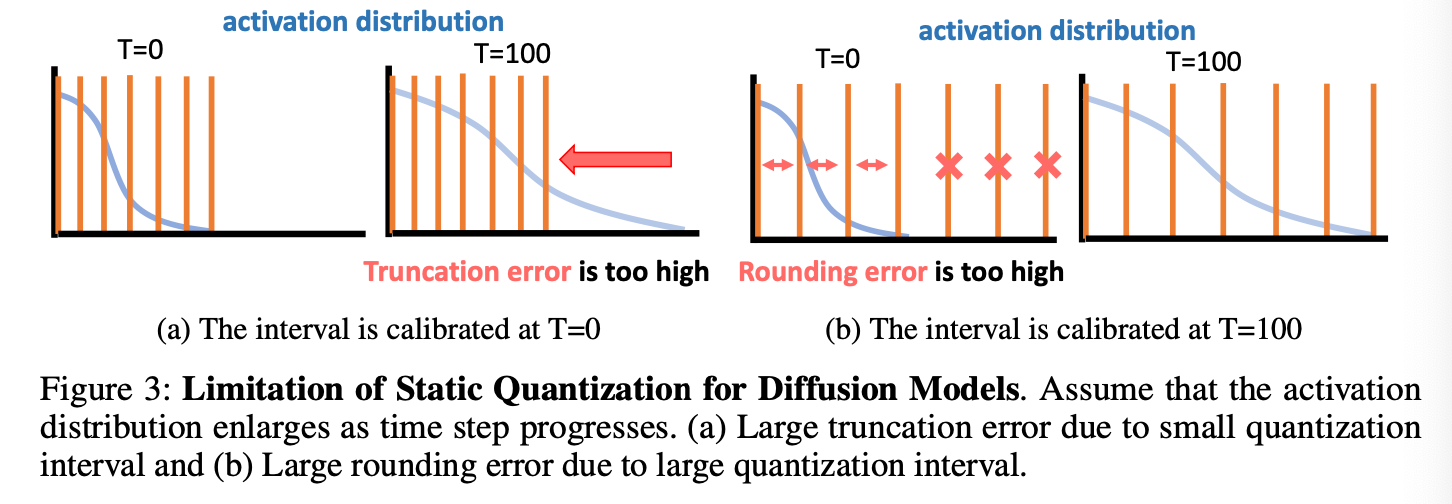
-
이전의 연구
Q-diffusion: Quantizing diffusion models(2023)
Post-training quantization on diffusion models(2023)
역시 diffusion model들의 activations의 dynamic한 property에 대해 보고했고,
모든 time frames에서 calibration dataset을 sampling하여 이 문제를 해결하기 위해 접근했다.
하지만, 이러한 연구들은 static parameters에 의존했고,
sub-optimal한 convergene of minimizing quantization error 결과를 보였다.
이러한 문제를 근본적으로 다루기 위해,
input activation distribution의 dynamics를 고려하여,
quantization parameters를 update하는 것이 중요하다.
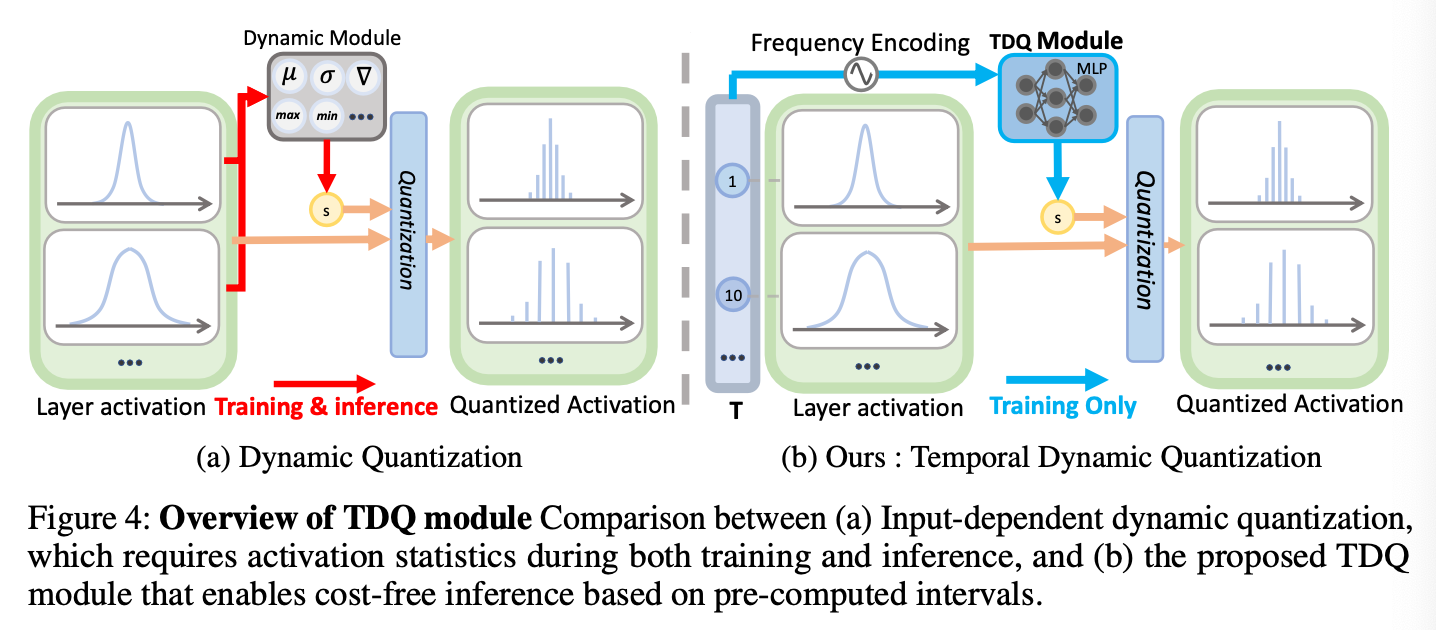
Implementation of TDQ Module
-
input activation의 급격한 변화를 다루기 위해서,
가장 쉽게 생각할 수 있는 방법은 input-dependent dynamic quantization이다.-
이전 연구들이 input features(minimum, maximum, avearge values)를 기반으로 quantization parameters를 생성하는 quantization module을 포함하는 것은
특정 applications에서의 accuracy를 크게 향상시킬 수 있음을 증명했다. -
본 연구의 supplementay material에서 제시되기도 한 실험에서는, 본 연구의 input-dependent dynamic quantization 구현은 눈에 띄는 quality 향상을 이뤘다.
하지만, 주어진 activation의 statistics를 모으는 과정은 복잡한 구현과 눈에 띄는 overhead를 갖는 문제가 있었다.
quality 향상 가능성이 있지만, 이 접근은 매력적인 해결책은 아닐 것이다.
-
-
대신, 본 연구는 input activation이 아닌
temporal information을 활용하는 dynamic quantization을 제시한다.-
input data를 기반으로 activation distribuion이 변화하더라도,
전체적인(overall) trends는 동일한 time frame 안에서는 유사하다.(Fig2)
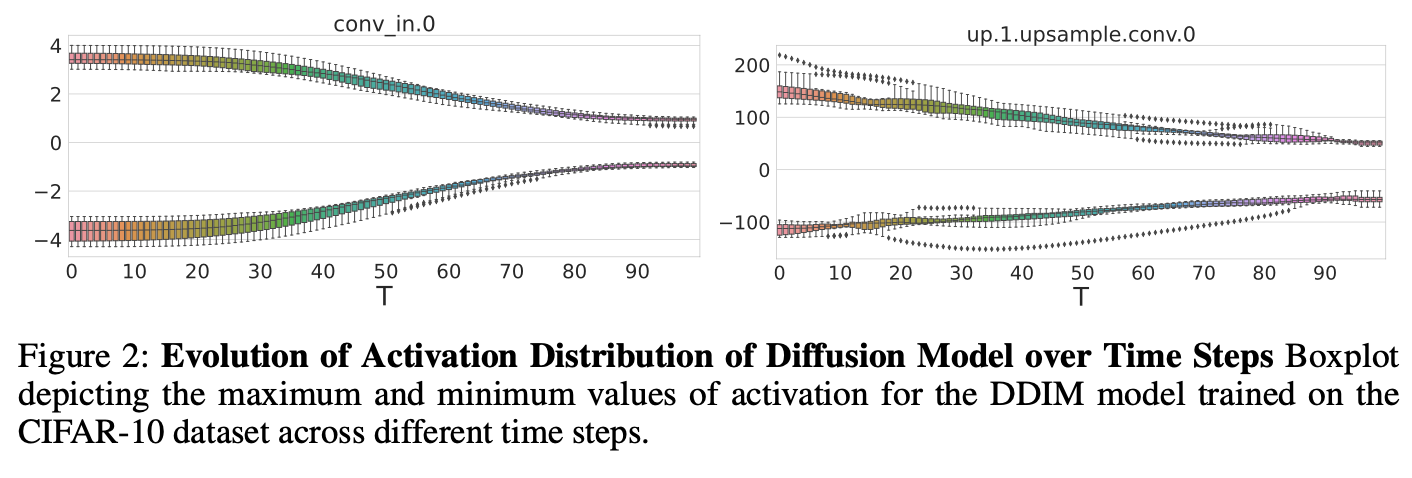
-
따라서, 각기 다른 time steps에 기반한 최적의 interval를 그릴 수 있고(depict),
이는 더 reliable하고 robust한 quantization 결과를 만든다.
-
-
상세한 구현은 Fig 4(b)에 제시되어 있다.
TDQ 모듈에서, dynamic interval 는 다음 수식과 같이 time step 에 기반해 생성된다.
where,
: encoding function of the time step (Section 3.4)
: encoded feature
: signifies the generator module function
-
본 연구에서 TDQ 모듈은 각 quantization operator에 attached되고,
주어진 time step에 기반해서 independnet한 dynamic quantization interval이 생성된다.
Fig 4에서 표현돼있듯, generator는 multiple linear layers + softplus funcion을 단순히 stacking하여 구현되며,
data range가 non-negative value가 되도록 constrain한다. -
generator의 모든 구성요소들은 미분 가능하다는 점을 주목하자.
결과적으로, PTQ 또는 QAT 과정 중에,
gradient descent를 사용해 quantization error를 최소화하도록
interval이 update될 수 있다.
예를 들어, LSQ(29)와 같이 잘 알려진 QAT 알고리즘을 사용한다고 할 때,
static interval은 TDQ 모듈의 output으로 대체할 수 있다.
그러면 Eq.5의 quantization function은 다음과 Eq.7과 같이 변형된다.
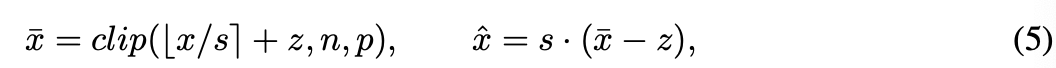
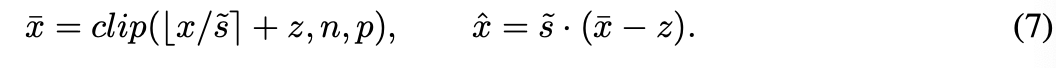
STE(straight-through estimator)를 사용할 때,
gradient는 generator의 learnable parameter들을 통해 propagate 가능하다.
이러한 parameter들은 final task loss를 최소화하며, iterative gradient descent를 통해 updated된다.
이 동일한 파이프라인이 local gradient를 활용해 reconstrubtion error를 최소화하는 PTQ 알고리즘에 적용될 수 있다.
Up or down? adaptive rounding for post-training quantization
Brecq: Pushing the limit of post-training quantization by block reconstruction
결과적으로, TDQ 모듈은 QAT와 PTQ schemes에 모두 쉽게 적용이 가능하다. -
하지만, input-dependent dynamic quantization과는 다르게,
TDQ 모듈은 cost-free inference를 가능케한다.
PTQ 또는 QAT 과정 이후에, time-dependent interval은 offline으로 pre-computed 가능하고,
inference 중에, 우리는 pre-computed value를 활용할 수 있다.
추가로, pre-computed interval은 현존하는 frameworks에 변형없이 TDQ 모듈을 integration할 수 있도록 하는 장점을 갖게 한다.
Engineering Details
-
본 논문은 TDQ 모듈의 안정성과 효율성을 높이기 위한 일련의 실험을 진행했다.
그리고 여러 enginerring 개선이 reliable한 결과를 달성하는데 핵심적인 역할을 함을 발견했다. -
Frequency Encoding of Time Step
time stepa을 directly하게 generator에 feed하는 것은
inferior convergence quality를 초래했다.
이 문제는 잘 알려진 신경망의 low-frequency inductive bias 때문이다.
On the spectral bias of neural networks
Fourier features let networks learn high frequency functions in low dimensional domains
만약 time step이 generator에 directly하게 input으로 들어가면,
time step과 무관하게 변하지 않는 interval을 생성한다.
이 low-frequency bias를 다루기 위해,
다음과 같이 Eq.6의 time step을 위한 geometric Fourier encoding을 사용했다.
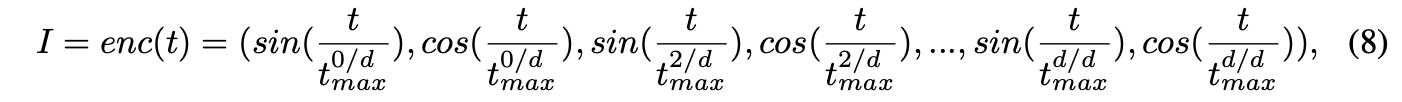
여기서
는 현재 time step,
는 encoding vector의 dimension,
는 encoded vector
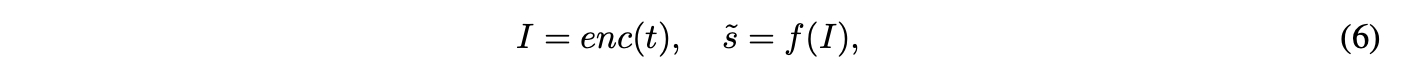
이러한 encoding 접근은 TDQ 모듈이 time step의 high-frequency dynamics를 고려할 수 있게 해준다.
본 논문에서는, 를 10000으로 경험적으로 설정했다. -
Initializaion of TDQ Module
quantizaion interval의 적절한 initialization은 중요하다.
부적절한 initialization은 QAT 또는 PTQ 과정을 불안정하게 만들 수 있기 때문이다.
현존하는 quantization 기술들은 오직 static step value를 초기화하면 되지만,
본 연구에서는 TDQ 모듈의 output을 desired value로 초기화해야 한다.
이를 위해서, weights에 He initialization(42)를 활용했고,
TDQ module(MLP)의 마지막 linear layer의 bias를 desired value로 설정했다.
MLP의 input(geometric Fourier encoding)이 mean of 0을 가진 확률 변수로 다뤄질 수 있음을 고려했을 때,
He-initialized MLP의 ouput 역시 mean of 0을 가질 것이다.
따라서, 우리는 MLP output의 mean을 bias adjustment를 통해 desired value로 조정할 수 있다.
모든 time step에서 1000개의 샘플들을 추출한 이후,
우리는 overall error를 초기화하고, 각 time step에 적용하기 위한 update를 수행하기 위하여,
quantization interval을 초기화한다.
Experimental Setup
-
TDQ의 superior performance를 증명하기 위해,
두 가지 모델을 이용해 tests를 진행했다.
1) DDIM: a pixel space diffusion model
2) LDM: a latent space diffusion model -
DDIM 실험에선 CIFAR-10 데이터셋(32x32)를 활용했고,
LDM 실험에선 LSUN Churches dataset(256x256)을 활용했다. -
PTQ와 QAT를 두 모델에 모두 적용했다.
하지만, latent diffusion model은 VAE와 diffusion model로 구성되어 있는데,
이 연구에선 diffusion model을 quantizing하는 것에 focus했고,
VAE component에는 quantization을 수행하지 않았다. -
diffusion model에서의 QAT 연구가 이전에 존재하지 않아서,
잘 알려진 static quantization 연구인 PACT. LSQ(+), NIPQ를 baseline으로 삼아 연구를 진행했다.
이 연구의 아이디어는 static interval을 TDQ 모듈의 output으로 대체하는 방식으로 LSQ의 top에 integrated되었다. -
per-layer quantization은 attention layer의 activation을 포함해서,
모든 convolutioal layers와 linear layers의 activations와 weights에 적용되었다. -
모델들은 CIFAR-10와 LSUN-churches에 200K iterations로 trained 되었고,
CIFAR-10은 batch size 128,
LSUN-churches는 batch size 32이다.
learning rate schedule은 full precision model과 같다. -
PTQ 실험에서는, SoTA 연구인 PTQ4DM을 baseline으로 사용했다.
공정한 비교를 위해서, PTQ4DM의 실험 세팅을 따랐지만,
dynamic quantization interval generation을 위해 activation quantization operator를 TDQ module로 변형했다.
PTQ4DM과 같이, weight에는 per-channel asymmetric quantization을 사용했고
activation에는 per-tensor asymmetric quantization을 사용했다.
weight quantization range는 per-channel minimum/maximum values에 의해 결정되고,
activation quantization range는 BRECQ와 같이 blockwise reconstruction loss를 최소화하기 위한 gradient descent를 통해 trained된다.
Quantization은 모든 layer들에 적용되었지만,
LDM PTQ experiment에서는, attrition matrix의 activation의 경우 quantized되지 않았다.
PTQ4DM의 접근을 따라, 본 연구에선 PTQ를 위해서,
256개의 이미지들에 대한 각각 20개의 random time step들로 구성된 5120개의 샘플들의 calibration set을 사용했다. -
모델의 성능을 측정하기 위해,
CIFAR-10에 대해서
FID(Frechet Inception Distance)와
IS(Inception Score)를 사용했다.
그리고
LSUN-churches에 대해선 FID를 사용했다. -
Evaluation을 위해서,
DDIM 200 step sampling와 QAT를 사용해 50,000개의 이미지를 생성했고,
DDIM 100 steps와 PTQ를 사용해 50,000갸의 images를 생성했다.
QAT의 경우, 가장 낮은 validation loss를 갖는 5개의 chechpoint를 선택했고,
best performing models로부터 score를 report했다. -
4개의 A100 GPU와 8개의 GTX 3090 GPU with PyTorch 2.0 framework 로 구성된 고성능 서버를 이용해 진행됐다.
source code는 review process 이후 공개될 예정이다.
한편, 실험 결과를 표현함에 있어 WxAy 표기를 사용했는데,
이는 x-bit weight & y-bit activation quantization을 의미한다.
Results
Quality Analysis after QAT and PTQ
-
Table 1은 TDQ 모듈을 현존하는 static quantization methods들과 비교한다.
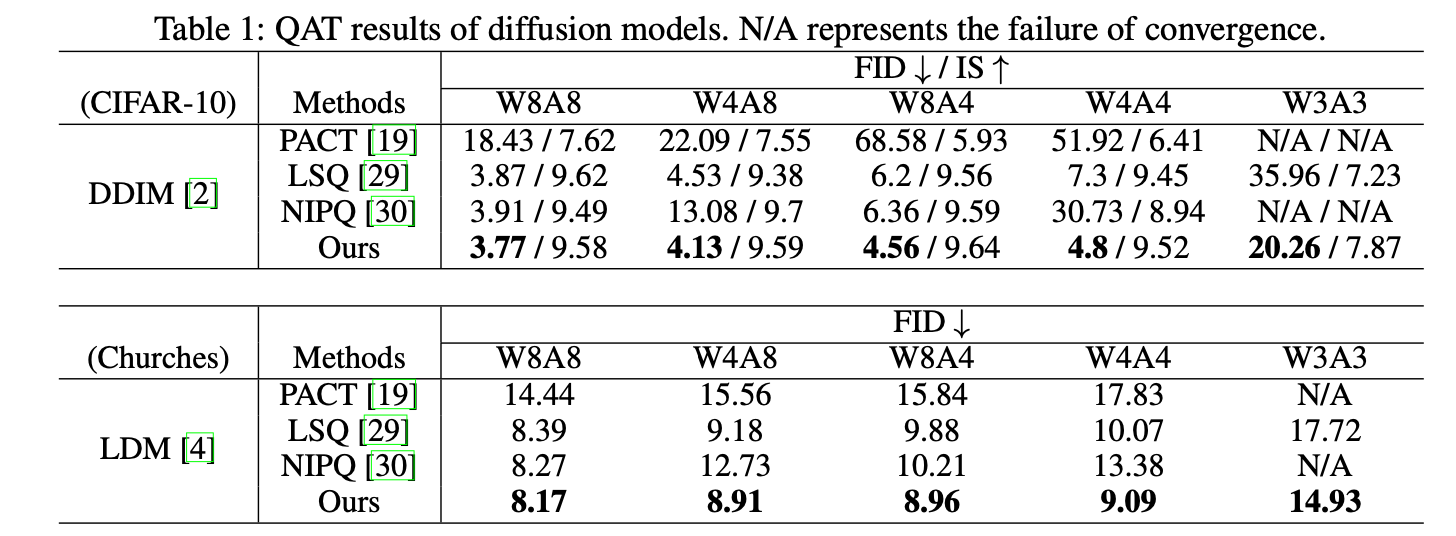
activation bit가 줄어들수록, 모든 static quantization method들은 inferior quality를 보였다.
하지만, Ours는 일관적인 output을 보였다.
TDQ 모듈은 심지어 8-bit에서도 상당한 quality 향상을 보였고,
4-bit precision에서는 그 장점이 더 컸다.
이는 full-precision output에 비해 quality degradation이 거의 무시할 정도임을 보인 것이다.
TDQ는 이러한 benefit을 한정된 activation quantization levels에 효율적인 할당을 통해 이루어냈다. -
이외에도, NIPQ는 artificial noise를 기반으로 한 pseudo quantization을 적용해 STE의 불안정함을 다루기 위해 도입했다.
하지만, NIPQ의 noise는 input noise와 구별할 수 없었고, diffusion model의 convergence를 방해했다.
diffusion model을 위한 PQN-based QAT의 benefit을 exploit하기 위해선 추가적인 effort가 필요하다.
- Table 2 는 TDQ 모듈과 현존하는 static PTQ schemes의 PTQ 비교를 보여준다.
여기서 Min-Max method는 range가 target tensor의 minimum과 maximum values에 의해 정해지는
naive linear quantization approach를 나타낸다.
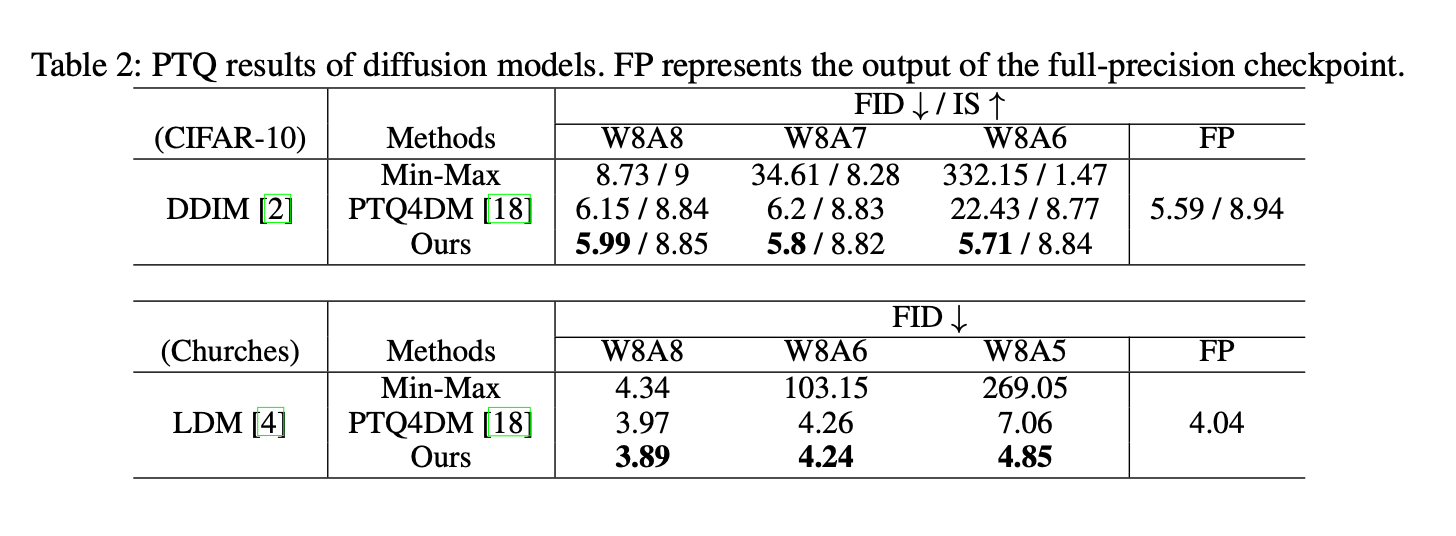
이 실험은 모든 baseline들이 activation bit가 high일 때에도 FID를 good level로 잘 유지하지만,
activation bit가 감소하면서 중대한 performance degradation이 발생함을 보여준다.
반면에, TDQ는 오직 slight level of FID degradation만 나타나며,
이는 TDQ 모듈이 QAT와 PTQ 시나리오들 모두에서 더 좋은 성능을 보이는 robust한 방법임을 가리킨다.
- Fig 5~7는 quantized diffusion model들이 생성한 image를 시각화했다.

ours는 동일한 bit-width configuration 안에서 consistent하게 다른 quantization 기술보다 high-fidelity 이미지들을 더 잘 생성함을 볼 수 있다.
Fig 5와 Fig 6는 전형적인 QAT와 PTQ는 blurred, unrecognizable image들을 생성하지만,
ours는 더 realistic한 image를 생성함을 보여준다.
activation quantization 안의 temporal information의 integration이
output의 perceptual quality를 유지하는데 있어 상당히 효율적임을 알 수 있다.
Generalization Performance of TDQ
-
fast-forward inference를 위한 TDQ 모듈의 성능을 증명하는 실험 결과를 보인다.
Training은 모든 time stpes 1부터 1000까지를 모두 수행하지만,
inference는 향상된 성능을 위해 더 적은 time steps(50~100 사이)로 수행될 수 있다.
이는 training/testing 도중의 time steps의 distribution을 변화시키므로,
TDQ 모듈의 생성은 일반화 능력이 요구된다. -
Fig.8은 W8A4와 W4A4 configurations로 LSQ 알고리즘으로 quantized된 DDIM 모델의 FID 측정 결과를 보인다.
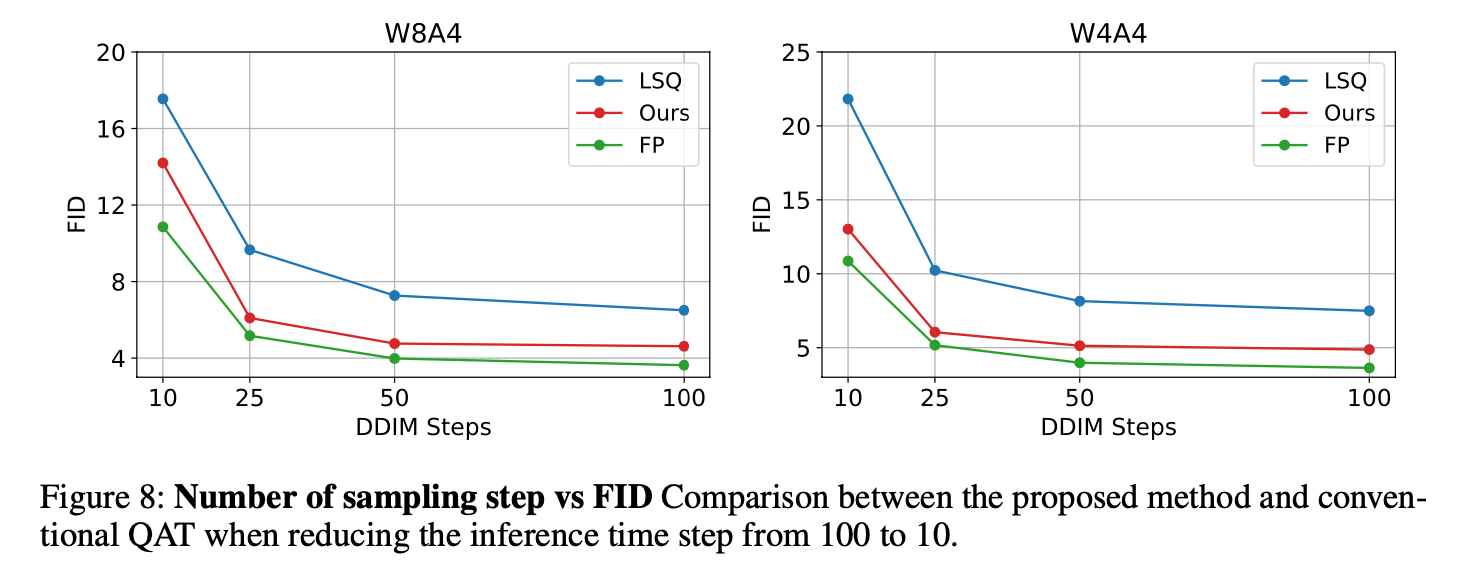
inference 과정에서 time step은 100부터 10까지 점진적으로 줄어든다.
묘사된것처럼, LSQ의 성능은 time step이 감소할 수록, 상당히 악화되는 반면에
ours는 full-precision baseline과 유사하게 성능이 감소하는 것을 볼 수 있다.
이 실험은 TDQ 모듈이 sampling time step이 다양할 때(varies)에도 효율적으로 동작함을 증명한다.
Ablation Studies of TDQ
-
TDQ 모듈의 output dynamics를 조사하기 위해,
본 논문은 time steps에 관한 dynamic interval의 updates를 시각화했다. (Fig.9)
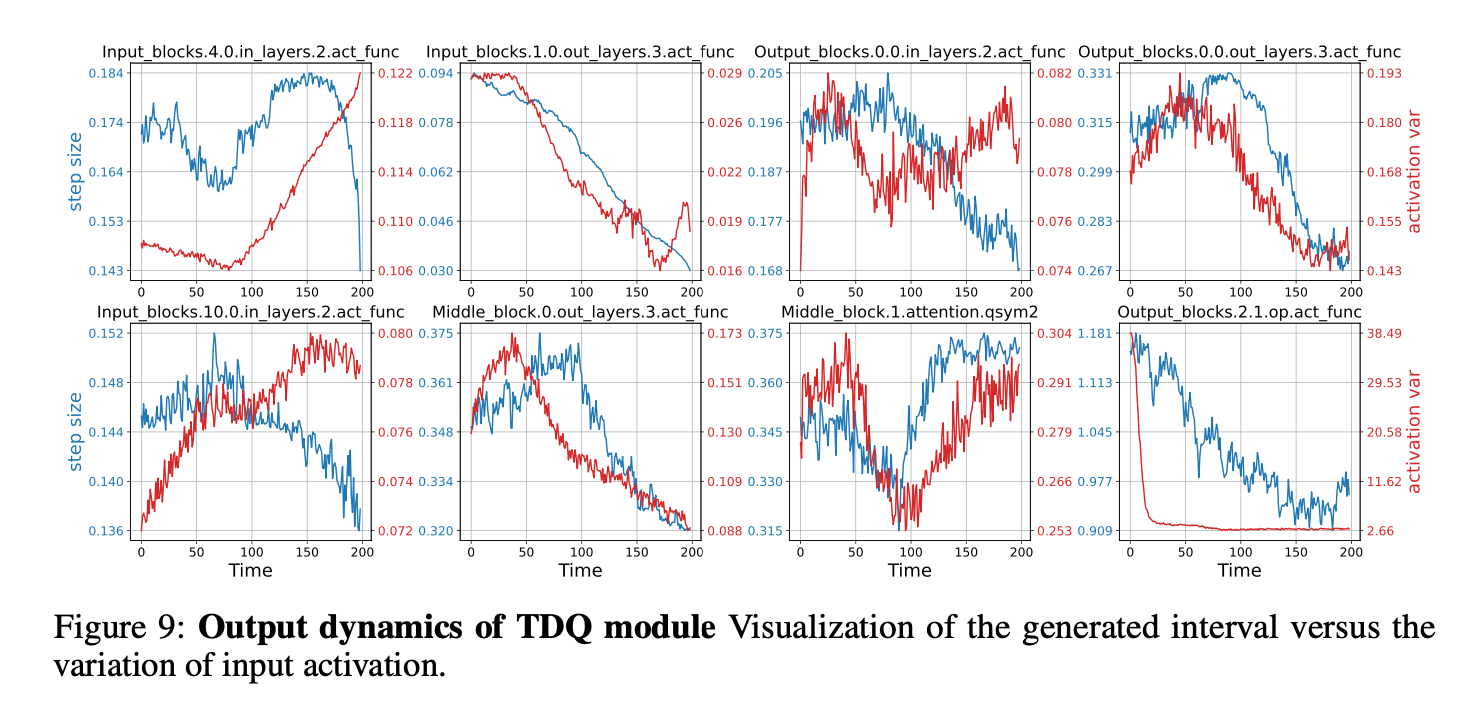
W4A4 LSQ를 DDIM에 사용해 trained된 interval은 activation variations와 함께 변화하는 경하을 보였다.
하지만, 이 패턴은 모든 layer들에서 관찰되진 않았다.
이러한 inconsistencies는
LSQ가 quantization interval을 그에 맞게 조정하면서
TDQ 모듈이 final loss value를 최소화하는 interval을 생성하기 위해 시도(attempting)함을 가리킬 수 있다(could potentially indicate) -
TDQ 모듈의 장점을 더 포괄적으로 분석해 제공하기 위해, 현존하는 Input-dependent dynamic quantization methods와 비교하는 실험을 진행했고,
TDQ 모듈의 temporal encoding scheme의 영향을 조사했다.
자세한 실험은 supplementary material에서 찾아볼 수 있다.
Conclusion
-
본 논문에선 diffusion model의 activation quantization의 challenge 특히, time steps 간의 dynamics of activation을 다루었다.
그리고 현존하는 static quantization methods들은 이 문제를 다루기엔 효율적이지 않음을 보였다. -
본 논문은 TDQ 모듈을 도입했는데, 이는 QAT와 PTQ를 결합한 방법이다.
dynamic quantization interval generation을 기반으로 output quality를 상당히 향상시킬 수 있었다. -
inference 과정에서 어떠한 overhead 없이 TDQ 모듈이 구현될 수 있기 때문에, low-bit diffusion model들이 mobile과 edge devices에서 quality를 유지하면서 performance를 향상시킬 수 있기를 기대한다.
