
Challenge
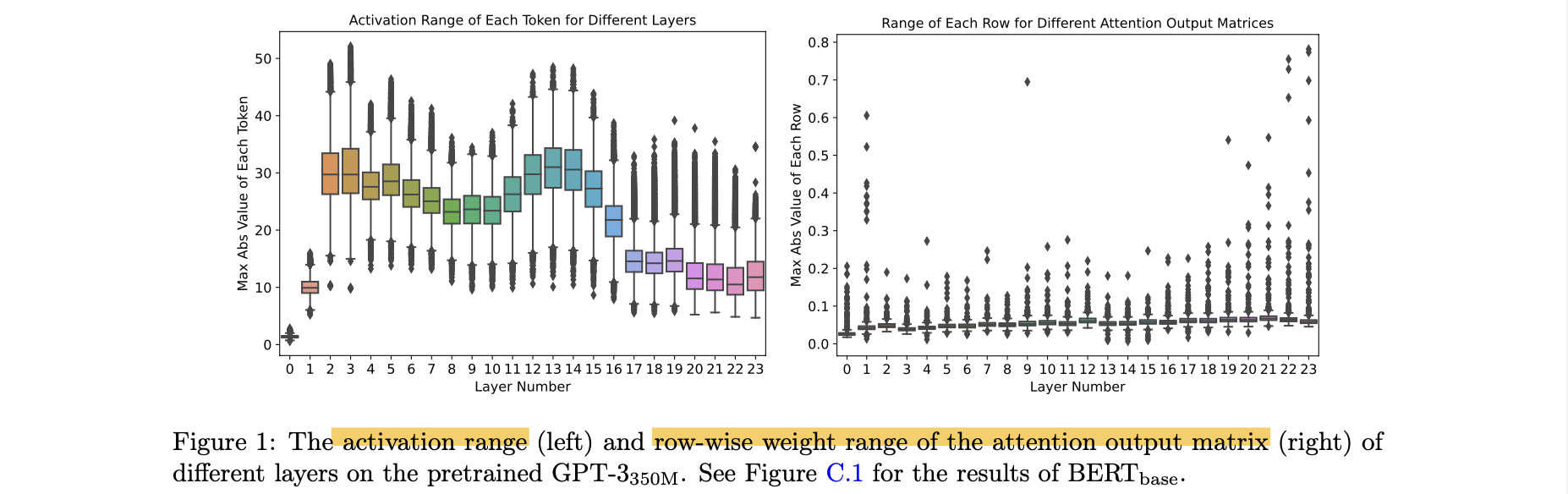
- INT8 representation은 range 차이를 모두 커버하지 못함.
- weight matrix의 각 row의 서로 다른 numerical range
- 각 activation token의 서로 다른 numerical range
Method
1. Quantization
-
weight matrix: group-wise Q
-
activation matrix: token-wise Q
- 각 token의 min/max range를 계산해서 Q error 감소.
2. Layer-by-Layer Knowldge Distillation(KD)
-
Layer-by-layer distilation(LKD)
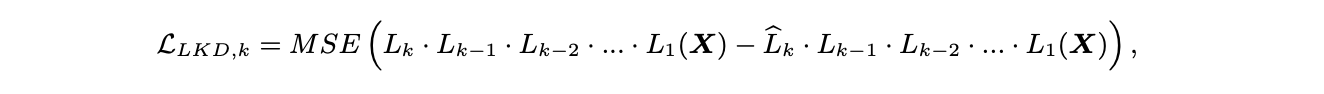
-
Given
transformer blocks ,
dataset input -
model을 layer-by-layer로 quantize하고, original(unquantized) version을 tecaher model로 사용한다.
-
layer 를 Q
- : quantized version
- 의 output을 와 의 input으로 사용해서 차이를 구하고, 를 update한다.
- MSE 대신 다른 loss로 사용 가능.
-
-
기존 KD의 limitation 극복
-
(1) training 때 teacher model과 student model을 갖고 있어야 하므로, memory와 compute cost 증가.
- LKD: 별도의 teacher model 필요 없음: 동일한 을 teacher/student model로 사용
-
(2) student model의 full training이 요구되므로, model update를 위해 gradient, first/second order momentum 등 weight parameter의 여러 복사본이 memory에 저장되어야 한다.
- LKD: 오직 layer 만 optimize하므로, memory overhead 크게 감소.
-
(3) 접근이 어려운 original training data가 요구됨.
- LKD: end-to-end model을 optimize하지 않으므로, label이 필요 없음.
-
