
핵심 아이디어
-
quantization 했을 때 , 전체 Loss에 최소로 영향을 주는 weight를 quantization하고, 나머지 weight들을 update 한다. (greedy하게 각 row 별로)
-
위 과정을 각 row의 weight가 모두 quantization 될 때 까지 반복한다.
핵심 수식
-
전체 Loss:
where, given a layer , weights , layer inputs , quantized weights
Hessian: -
각 row에서 quantization할 weight를 고른다.(quantization 시에 Loss에 최소 영향을 주는 weight 선택)
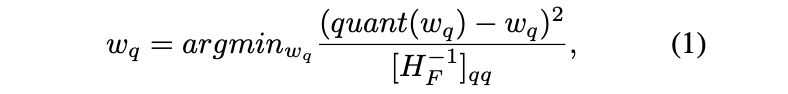
-
각 row에서 quantization되지 않은 나머지 weight를 update한다.
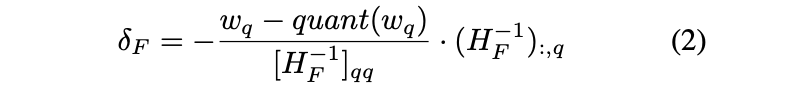
-
각 row에서 에서 -th row와 -th column을 제거(Hessian Update)한다.
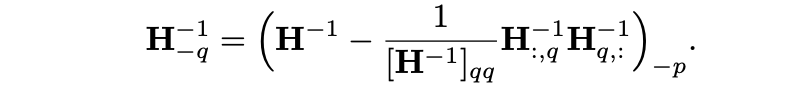
- 전체적인 작동 알고리즘

code 구현 시각화 (Visualization)
🟨 아래의 layer를 quantization한다고 가정하자.
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) - 위 Conv2d layer의 weight 와 Hessian inverse 구하기

-
여러 row를 parallel하게
(parallel = 32)연산한다.- weight quantization 및 quantization error 나머지 weight update
- , diagonal 계산 (이후 사용 위함)


-
Loss에 가장 영향을 적게 미치는 weight를 quantization할 로 선택
score = err/diag # score를 계산하고 (Loss에 미치는 영향 계산)
j = torch.argmin(scores, 1) # 각 row에서 quantize할 column index 하나씩 결정. # (32,) 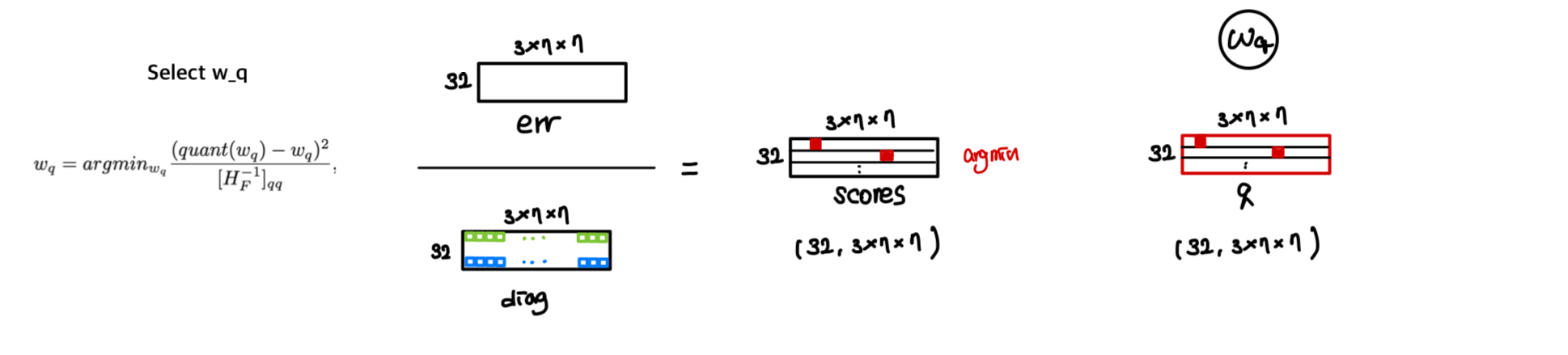
- quantization한 weight 이외의 나머지 weight들을 update

-
update 에서 -th row와 -th column을 제거
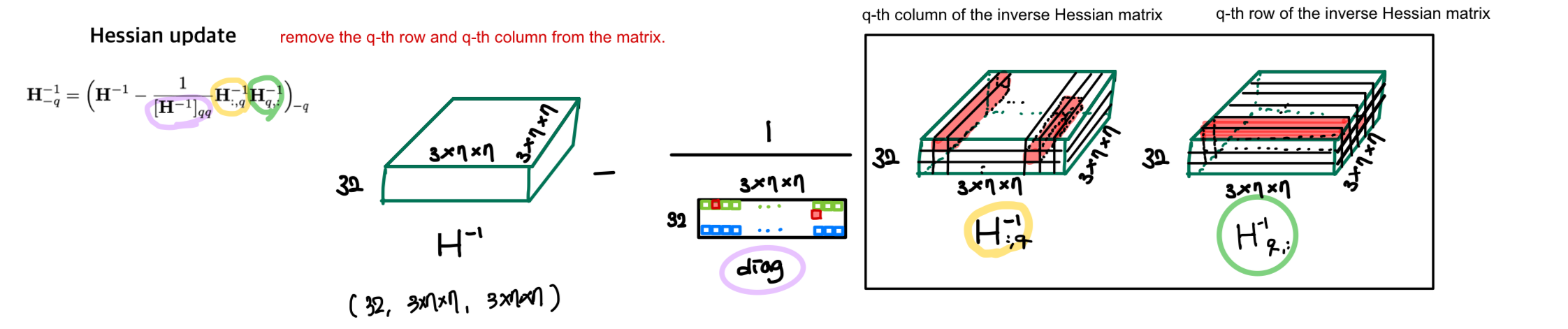
-
위 과정을 각 row의 모든 column들이 quantization 될 때까지 반복
한 parallel당 연산 소요.
코드를 보면, 모든 row에서 0을 갖는 column의 경우 연산에서 제외. (가중치가 0이면 quantization 영향이 없기 때문이다.)
