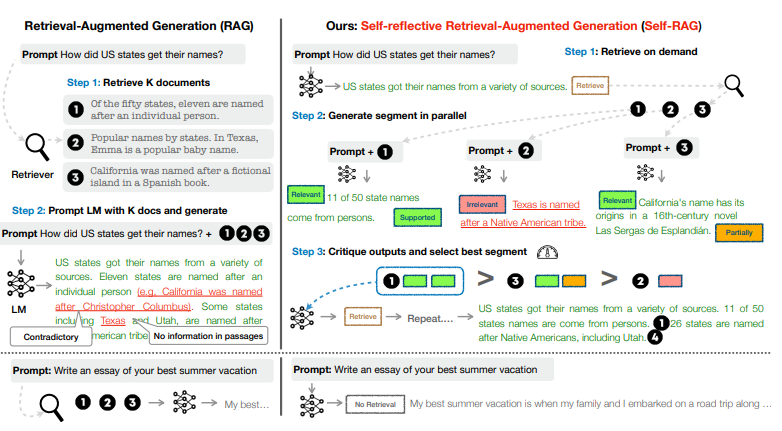
Problem Definition
- RAG는 LLM의 사실성 문제(e.g. hallucination)과 같은 문제를 해결할 수 있는 방법론
- 하지만, 기존 RAG의 무차별적 검색은 오히려 LLM의 다재다능함을 악화시킴
- 검색이 필요 없는 경우에도 고정적으로 k개의 문서를 검색해오기 때문에 query와 관련이 없는 문서가 검색될 수 있음
- 또한, RAG의 output이 일관성이 보장되지 않는다는 문제가 있음
- 즉, generation quality를 일관적으로 어떻다라고 말할 수가 없음
- 하지만, 기존 RAG의 무차별적 검색은 오히려 LLM의 다재다능함을 악화시킴
SELF-RAG
- on-demand retrieval + self-relection
: 반영 토큰(reflection token)으로 검색 여부를 결정하고 생성된 응답을 평가할 수 있음
→ 반영 토큰에는 검색 토큰(retrieve token), 비평 토큰(critique token)이 있음
→ 비평 토큰에는 Table1에서와 같이 IsREL, IsSUP, IsUSE 토큰이 있음
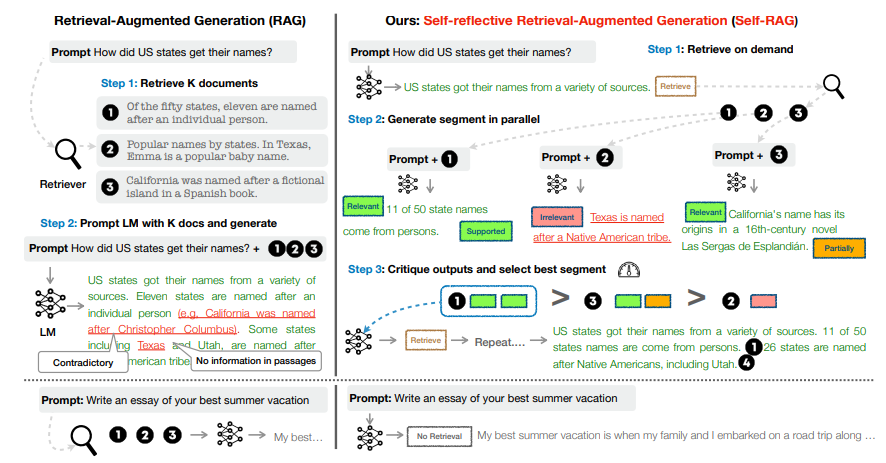

Training Overview

Training Critic Model
반영 토큰을 생성하도록 훈련
반영 토큰을 삽입한 훈련 데이터셋을 오프라인으로 업데이트
(Supervised) Data Collection
- 무작위로 원본 데이터를 추출
- GPT-4에 반영 토큰별로 각기 다른 instruction을 줘서 결과 생성
- 각 반영 토큰별 4k~20k의 훈련 데이터를 만들고 합침
- 합쳐진 훈련 데이터를 바탕으로 비평 모델 학습
Critic Learning
- 비평 모델은 사전 학습된 LM이기만 하면 됨. 저자는 generator LM과 동일한 Llama2-7B 사용
- 위 과정에서 만든 학습 데이터로 conditional language modeling objective()과 같이 반영 토큰의 likelihood가 최대화되도록 학습
- 즉, 조건을 기반으로 반영 토큰 예측
- 입력(조건)이 별도로 주어짐
- 위 과정에서 만든 학습 데이터로 conditional language modeling objective()과 같이 반영 토큰의 likelihood가 최대화되도록 학습
Training Generator Model
임의의 언어 모델이 반영 토큰과 함께 텍스트를 생성할 수 있도록 함
확장된 데이터셋(원래 데이터셋 + 반영 토큰)을 사용하여 다음 토큰 예측
Data Collection
- 비평 모델 학습 시 만들었던 데이터를 바탕으로 학습
Generator Learning
- critic model을 학습하는 방법과 똑같다. 단지, critic model과 달리, generator 모델이기 때문에 task에 대한 출력 및 반영 토큰을 예측하도록 학습
- Next Token Prediction Objective(=GPT에서 흔히 사용되는 Autoregressive Modeling, )과 같이 마찬가지로 likelihood가 최대화되도록 학습
- 이전 토큰을 기반으로 다음 토큰 예측
- 입력이 곧 조건, 출력은 다음 토큰
- loss 계산의 경우 검색된 텍스트는 마스킹
- generator가 입력과 reflection token을 기반으로 출력하게끔 유도
Inference Overview

- 입력에 대한 출력 먼저 생성
- 이후 검색 토큰을 생성함으로써 검색 필요 유무를 결정
- 검색이 필요하지 않은 경우
- 언어 모델은 다음 출력 세그먼트를 예측(=일반적인 언어 모델의 구조)
- 검색이 필요한 경우
- 관련 문서 검색
- 입력과 문서와의 관련성 평가(IsREL 토큰)
- 문서와 응답의 지지도 평가(IsSUP 토큰) + 전반적인 유용성 평가(IsUSE 토큰)
(여러 개의 세그먼트를 동시에 생성하기 위해, 여러 개의 문서를 병렬적으로 처리)
- 검색이 필요하지 않은 경우
Experiments
- 태스크/데이터셋
- closed-set tasks .. 분류 태스크?
- 사실 검증: PubHealth
- 다지선다 추론: ARC-Challenge
- 단문 생성: Pop-QA, TriviaQA-unfiltered
- 장문 생성
- 전기(biography) 생성: FActScore 참고
- QA: ALCE-ASQA
- closed-set tasks .. 분류 태스크?
- 평가지표
- closed-set task, 단문 생성
- accuracy(acc)
- 장문 생성
- FactScore(FS): 전기 생성 측정
- str-em(em), rouge(rg): MAUVE를 기반으로 correctness 측정
- MAUVE(mau): MAUVE를 기반으로 fluency 측정
- citation precision(pre), recall(rec): ASQA에서 사용
- closed-set task, 단문 생성
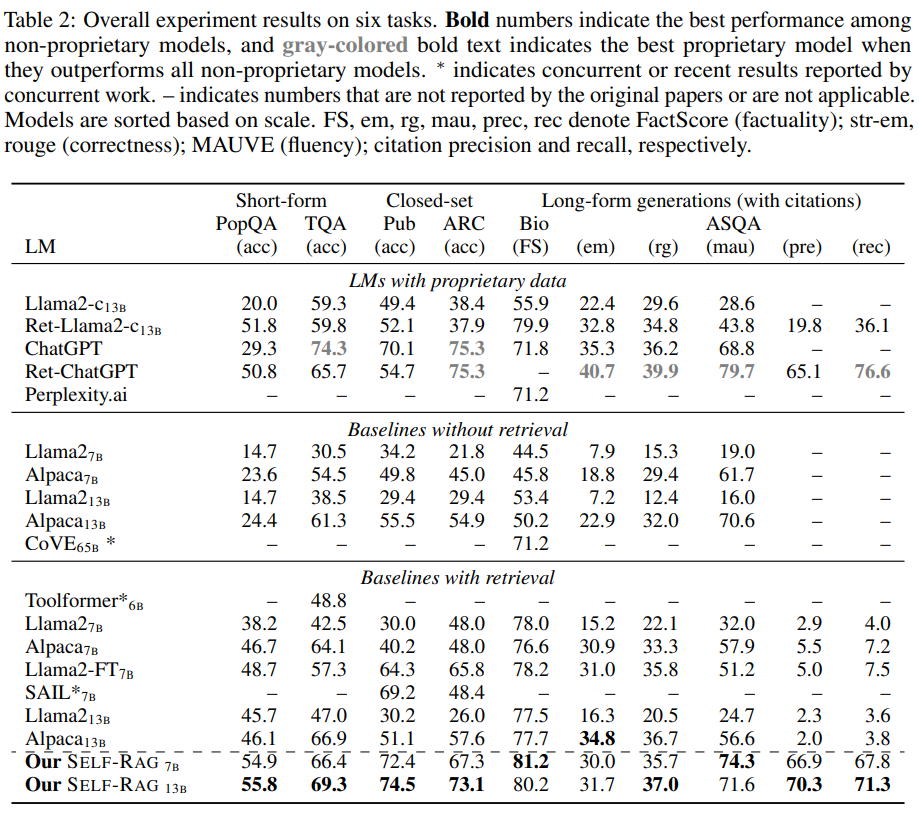
- 결과
- w/ retrieval baseline과의 비교
- SELF-RAG(7B, 13B)가 모든 부분에서 최고의 점수
- 심지어, PubHealth, PopQA, 전기 생성, ASQA에서는 ChatGPT 능가
- 전기 생성에서는 CoVE 능가
- w/o retrieval baseline과의 비교
- non-proprietary 언어 모델들보다 모든 부분에서 능가
- SELF-RAG는 ChatGPT를 제외한 모든 모델보다 높은 pre, rec 기록
- 심지어 rec에서는 ChatGPT 능가
- w/ retrieval baseline과의 비교

stick-to-it-iveness