Backgrounds
-
Retrieval-Augmented Geneartion(RAG)
- 외부 지식 소스에서 질문과 관련된 정보를 검색하여 맥락으로 사용
→ LLM이 이전에 보지 못한 질문에 답변할 수 있게 만듦 - 지역적(local)인 데이터 분석에는 강점이 있으나, 전역적(global)인 데이터 분석에는 취약함
- "What is the main theme of this dataset?
- 외부 지식 소스에서 질문과 관련된 정보를 검색하여 맥락으로 사용
-
Query-Focused Summarization(QFS)
- 어떤 텍스트의 단순 요약이 아닌, 질문에 대한 답변을 포함하는 요약을 생성하는 태스크
- 단순히 원문에서 문장을 발췌할 수도 있지만, 질문에 맞춰 추상적으로 요약하여 자연스러운 답변을 생성할 수도 있음 (abstractive summarization)
- QFS의 경우, 대규모 데이터를 처리하는 확장성이 부족함
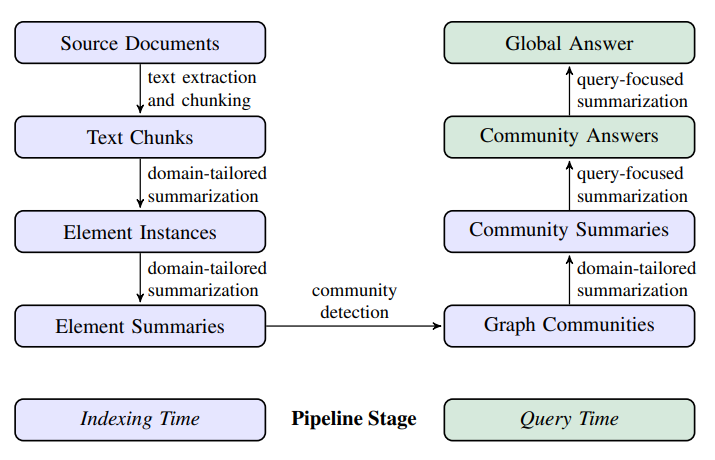
GraphRAG
- 핵심
- LLM을 사용하여 그래프 기반 텍스트 인덱스를 생성
- 소스 문서에서 엔티티 지식 그래프를 도출
- 밀접하게 관련된 엔티티들을 하나의 커뮤니티로 묶고, 커뮤니티에 대한 요약 생성
- 질문이 주어지면 커뮤니티 요약을 바탕으로 부분 응답을 생성 및 평가
- 이후 모든 부분 응답이 다시 요약되어 사용자에게 최종 응답으로 제공
- LLM을 사용하여 그래프 기반 텍스트 인덱스를 생성
1. Source Documents → Text Chunks
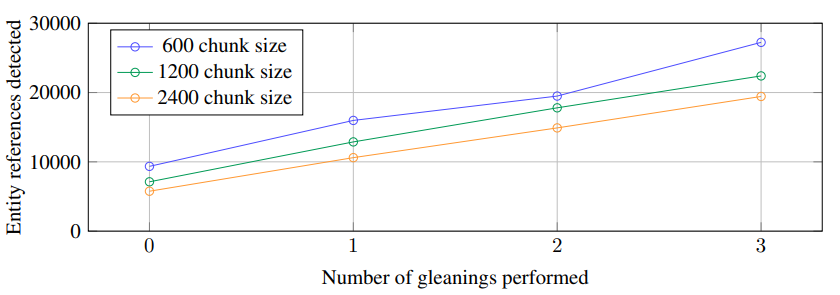
텍스트를 길게 자를 경우, 엔티티 추출을 위한 LLM 호출 수는 줄어들지만, 추출되는 엔티티의 수도 줄어듦
→ 적절한 크기의 chunk를 사용하여 recall과 precision의 균형을 맞춰야함
2. Text Chunks → Element Instances
-
LLM을 바탕으로 entity, relation, claim 추출하는 단계
- entity 추출
- name, type, description
- closely-related entity들의 relation을 식별
- source/target entity, description
- few-shot 예시를 제공하여, LLM이 특정 domain에 맞게 정보를 추출하도록 조정
- 보조적인 프롬프트를 바탕으로 entity와 관련된 추가적인 정보(covariate) 추출
- subject, object, type, description, source text span, start/end dates
- 놓친 엔티티가 없는지 보기 위해 여러 번의 재추출(gleaning)을 거치고, 누락된 엔티티가 있다면 추가 추출을 유도해 long text chunk에서도 품질을 유지할 수 있게 함
Gleanings
LLM에게 모든 entity가 추출됐는지 질문하여 예/아니오 중 결정하도록 설정
놓친 엔티티가 있다고 판단되면(즉, LLM의 답이 "아니오"일 경우) 다시 엔티티를 추출하는 과정을 거침 - entity 추출
3. Element Instances → Element Summaries
- LLM을 사용하여 소스 텍스트에서 entity, relation, claim에 대한 요약을 추출하는 단계
- 각 그래프의 요소에 대해 개별적으로 생성된 요약을 하나의 설명 텍스트 블록으로 통합하는 추가적인 단계
4. Element Summaries → Graph Communities
- (여러 커뮤니티 감지 알고리즘 중) Leiden 기법을 사용하여 커뮤니티의 계층적 클러스터링이 이루어지는 단계
- Leiden 기법의 경우 대규모 그래프의 계층적 커뮤니티 구조를 효율적으로 복구할 수 있음
- entity(노드)들은 relation(엣지)로 연결
- 노드 간의 탐지된 엣지의 정규화된 개수(degree)로 weight 부여
→ 연결이 강한 커뮤니티로 그래프를 분할
- 노드 간의 탐지된 엣지의 정규화된 개수(degree)로 weight 부여
5. Graph Communities → Community Summaries
- 각 커뮤니티에 대한 요약을 생성하는 단계
- 리프 수준 커뮤니티
- local한 질문들을 다루기 위한 과정인 듯
- 노드, 엣지, 공변량(covariate)에 대한 요약을 우선순위에 따라 토큰 한도에 다다를때까지 LLM의 context window에 반복적으로 추가
- 여기서 우선순위란 소스 노드와 타겟 노드의 degree를 합쳤을 때의 rank를 의미하는 듯
- 상위 수준 커뮤니티
- global한 질문을 다루기 위한 과정인 듯
- 각 리프 수준 커뮤니티에 대한 요약들을 합쳤을 때 max_context_length보다 적으면 괜찮지만, 이를 넘어서는 경우 짧은 요약들로 대체하여 더 많은 주제를 다룰 수 있게 함
- 리프 수준 커뮤니티
→ 해당 과정들을 통해 대규모 데이터셋에서 전체적인 구조와 의미를 파악하는 데 도움을 줄 수 있음
6. Community Summaries → Community Answers → Global Answer
- 커뮤니티 요약을 이용해 최종 답변을 생성하는 단계
- Prepare Community Summaries
- 위에서 생성했던 커뮤니티 요약을 무작위로 섞고 chunking
→ 관련 정보가 한쪽에 치우쳐지는 것이 아니라 여러 청크에 고르게 분포하도록 함
- 위에서 생성했던 커뮤니티 요약을 무작위로 섞고 chunking
- Map community answers
- 각 청크마다 중간 답변을 병렬로 생성
- LLM이 중간 답변에 대해 0~100의 점수를 매김
- 점수가 0이라면 제외
- Reduce to global answer
- 점수가 높은 순으로 중간 답변들을 정렬하고 max_context_length에 도달할 때까지 context window에 추가
- Prepare Community Summaries
Evaluation
- 질의 형성 방법
- LLM을 통해 자동으로 생성

- LLM에게 데이터셋에 대한 설명 제공
- LLM이 잠재적 사용자 N명 및 각 사용자별 잠재적 task N개 식별하여 global question에 대한 질문 N개 생성
→ N=5라면 5*5*5=125개의 테스트 데이터셋
- LLM을 통해 자동으로 생성
- Conditions
- CO : root-level 커뮤니티 요약 사용
- C1 : high-level 커뮤니티 요약 사용. C0의 하위 커뮤니티
- C2 : intermediate-level 커뮤니티 요약 사용. C1의 하위 커뮤니티
- C3 : low-level 커뮤니티 요약 사용. C2의 하위 커뮤니티
- TS(Text Summarization) : 커뮤니티 요약 대신 소스 텍스트를 Map-Reduce 요약 단계에 적용
- SS(Semantic Search) : naive RAG 방식으로 텍스트 청크하여 context window에 추가 및 답변 생성
-
Metrics
- Comprehensiveness : 답변이 질문의 모든 측면과 세부 사항을 잘 다루는지
- Diversity : 답변이 다양한 관점과 통찰을 제공하는지
- Empowerment : 답변이 이해와 판단에 얼마나 도움이 되는지
- Directness : 답변이 얼마나 명확하고 구체적으로 답하는지
평가 detail
LLM을 evaluator로 설정하여 두 답변을 직접 비교하여 평가
(head-to-head 비교 방식)
- Configuration
- context window의 크기의 영향을 비교
- comprehensiveness 측면에서 8k, 16k, 32k, 64k를 비교한 결과 8k에서 가장 좋은 성능을 보였기 때문에 context window의 크기를 8k로 설정
- context window의 크기의 영향을 비교
- Results
표 해석법
행 조건이 열 조건과 비교했을 때 승률을 숫자로 나타냄
: 승률은 두 조건이 125개 질문에 대해 5번씩 반복 평가된 결과로 평균을 내어 산출
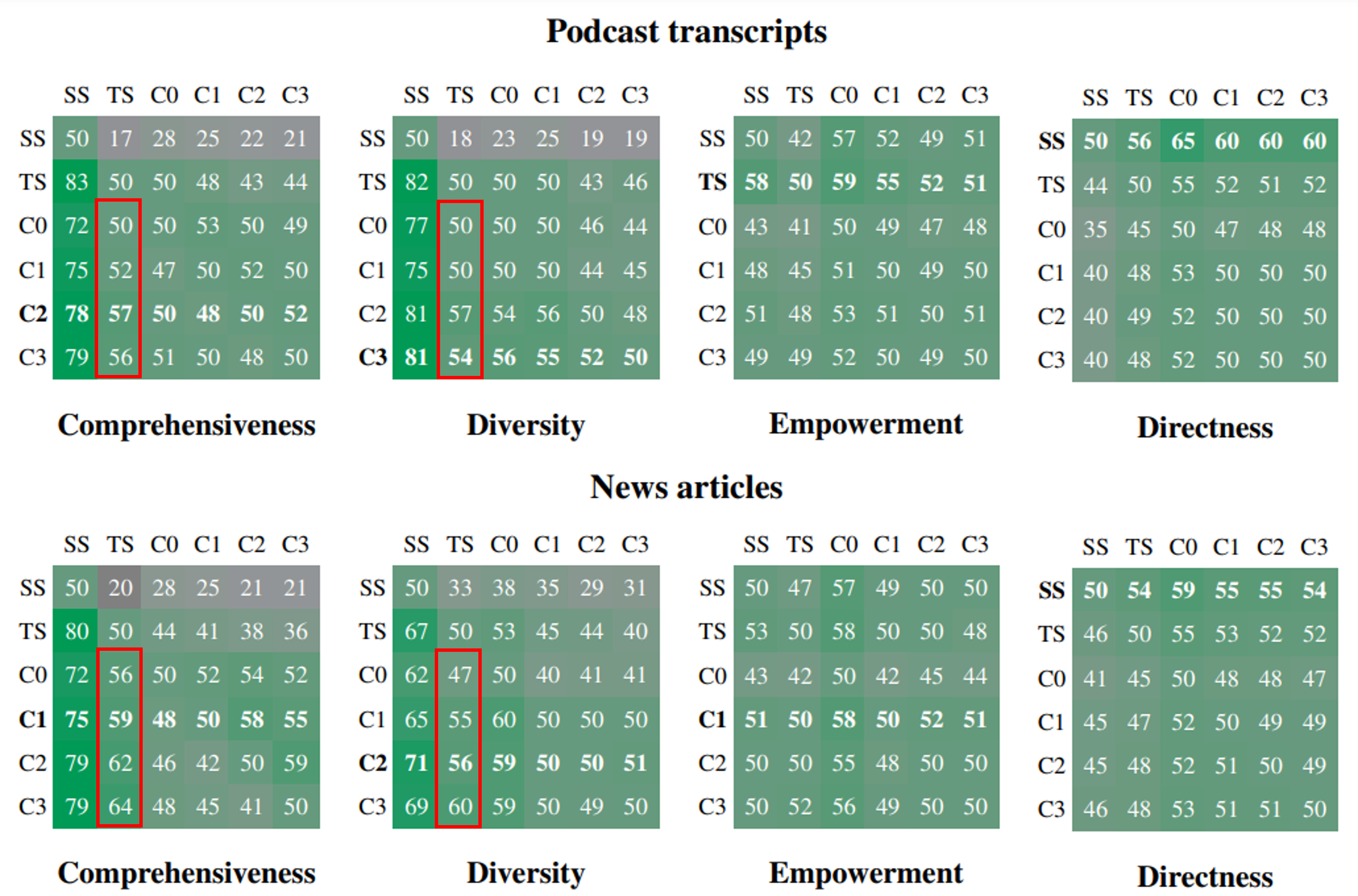
- global approach > naive RAG (Comprehensiveness, Diversity)
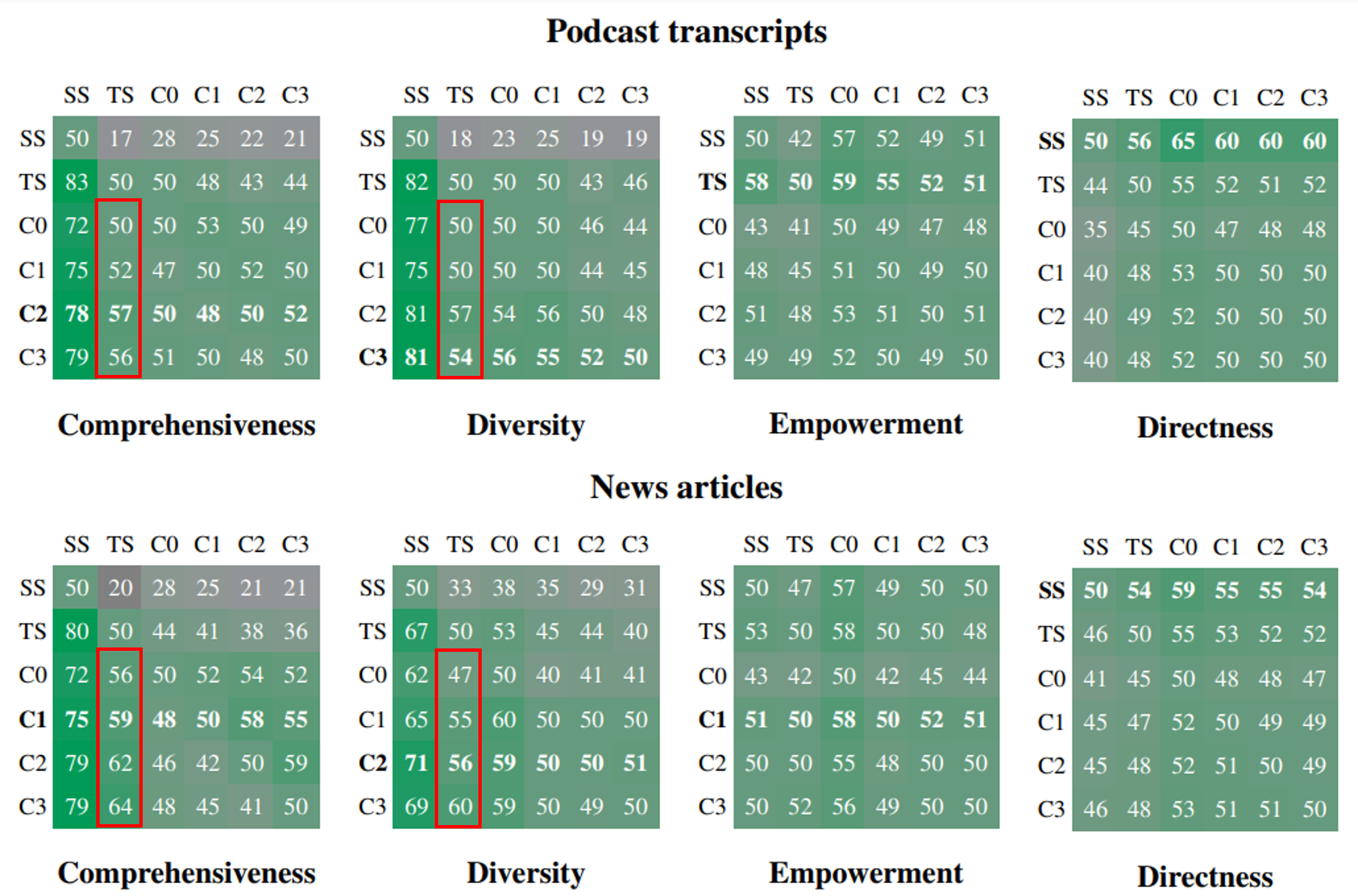
-
일반적으로 커뮤니티 요약(C0, C1, C2, C3) > 원본 텍스트(TS)
(Comprehensiveness, Diversity) -
Empowerment에서는 복합적인 양상

stick-to-it-iveness