원본 데이터를 쓸모있게 가공하기 위해 전처리(Preprocessing) 단계를 해 볼 것이다.
해당 과정의 기준들은 1편의 Exploring Data 단계에서 설정하였다.
Data Preprocessing
Drop Null data
일단 전체 data에서 어느 column에, 얼만큼 Null 값이 있는지 확인해보자
retail.isnull().sum()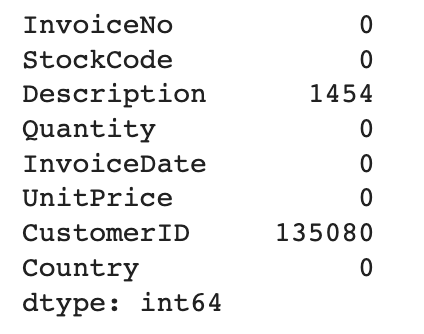
Description에 1,454개 CustomerID에 135,080개가 있다.
(구매자 정보가 없는 구매 데이터가 이렇게 많다니 아무리 가상 데이터라지만..)
이제 retail data에서 Null인 행은 Drop 할 것이다.
즉, Null이 아닌 행만 살리면 되는 것이다.
# Drop null CustomerID
print("Before DROP: ", len(retail))
retail = retail[pd.notnull(retail['CustomerID'])]
print("After DROP: ", len(retail))
제거하고 보니 406,829개가 남았다. 135,080개가 Drop 된 것이다.
잘 제거됐는지 확인해보자.
retail.info()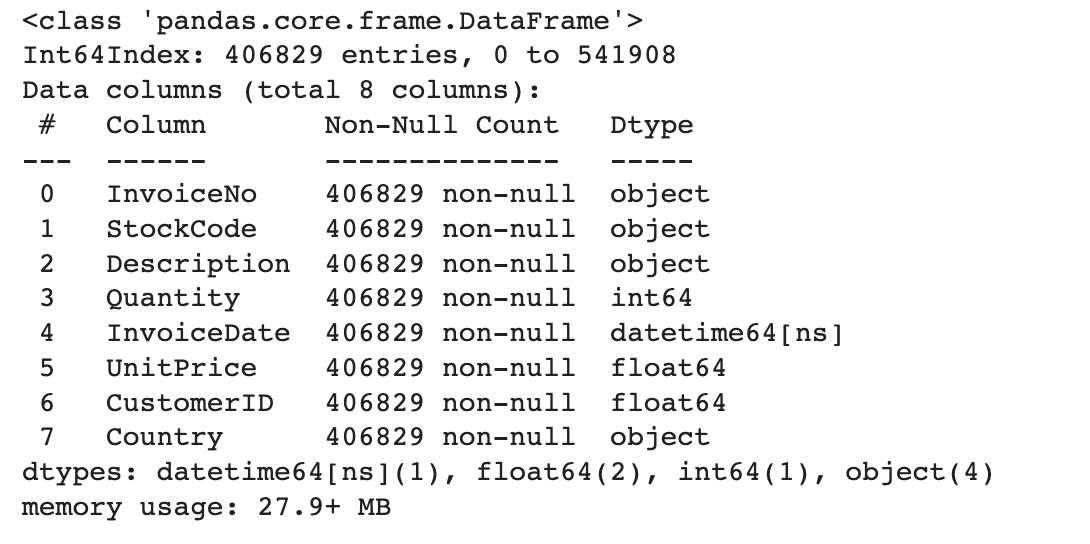
모든 column의 Non-Null의 개수가 전체 개수인 406,829와 동일하므로 잘 제거되었다.
Drop data
Quantity(수량)과 UnitPrice(가격)의 data 중 음수인 값이 있었다.
비지니스 로직으로 두 값이 음수일 수는 없으므로 Drop 해주자.
# Drop minus Quantity and UnitPrice
print("Before DROP: ", len(retail))
retail = retail[(retail['Quantity'] > 0) & (retail['UnitPrice'] > 0)]
print("After DROP: ", len(retail))
8,945개가 Drop 되고 397,884개가 남았다.
이번에도 잘 제거됐는지 확인해보자.
retail.describe()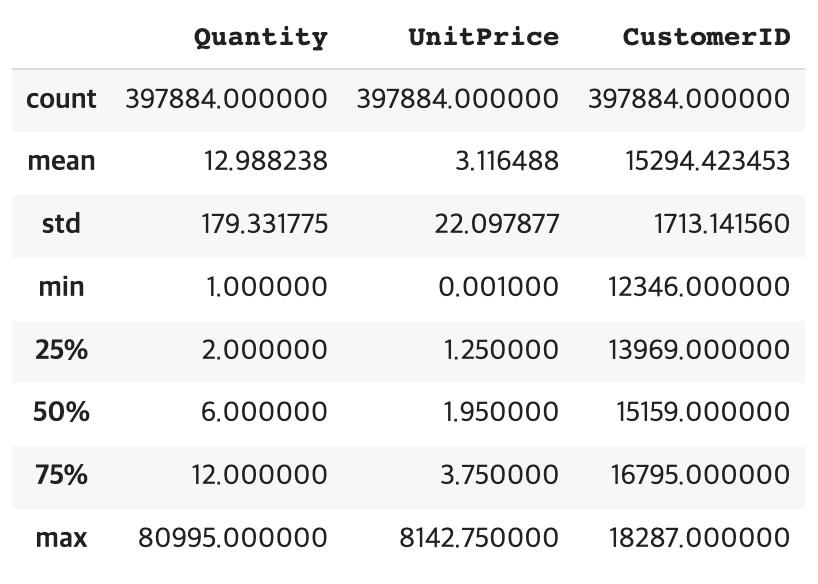
column의 최솟값인 min이 0 이상으로 출력되므로 잘 제거되었다.
Type conversion
CustomerID가 float여서 135.0 이런식으로 저장되어있다.
식별을 위한 index ID니까 int로 바꾸어주자.
# Type conversion
retail = retail.astype({'CustomerID':'int'})
retail.info()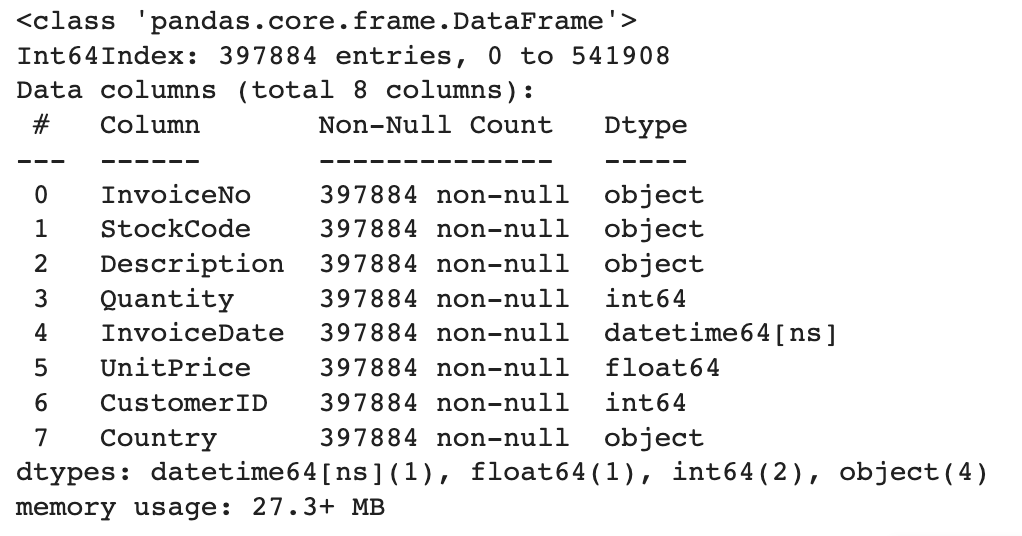
int로 잘 바뀌었다.
Add column
기존 data에는 Quantity와 UnitPrice가 있는데, 이 둘을 곱하여 CheckoutPrice(결제가격) column을 추가해보자.
retail['CheckoutPrice'] = retail['Quantity'] * retail['UnitPrice']
retail.head()
아까 converse한 CustomerID도 int로 잘 출력되고 CheckoutPrice도 생성 후 계산되었다.
Save Data
Save preprocessed data
전처리 과정을 끝낸 data를 csv로 저장해놓고 앞으로의 process에선 해당 파일을 사용할 것이다.
path는 이전 글에서 언급했듯이 Colab에서 작업하고 있으므로 MyDrive로 지정해놓았다.
retail.to_csv(path + 'OnlineRetail_cleaned.csv')이번 글에선 Preprocess 과정만 담았다.
본격적인 분석에 앞서 Raw data를 쓸모있게 만드는 과정이기에 정말 필요할지, 어떻게 조합할지 생각해보고 작성했다.
다음으론 매출을 기반으로 가장 많이 팔린 품목을 찾아볼 것이다.
