문제
문제 화면입니다. 파일의 이름은 Hello_SuNiNaTaS 입니다.
풀이
문제 화면을 통해 알 수 있는 사실은 PDF 형식이라는 것과 악성코드가 첨부되었다는 문장을 통해 스테가노그래피 기법을 이용한건가? 라고 생각하면서 접근할 수 있습니다.
문제 파일을 열면 다음과 같은 한 장의 페이지가 보이고 별 게 없다는 걸 알 수 있습니다.
저는 포렌식 문제를 풀 때 윈도우에서 파일 실행과 Hex Editor를 통해 열어본 후, kali로 옮겨 진행합니다.
많은 파일 분석 도구들이 있지만 이번 문제 풀이에서는 처음으로 peepdf 라는 도구를 사용해보았는데, pdf 분석 도구로 꽤나 자세하게 정보를 알려줍니다.

peepdf.py를 통해 실행을 시켜줬는데, python2여야지 열리는 것 같아 앞에 따로 버전을 명시해줬습니다.
python2 peepdf.py -i [분석할 pdf PATH] 를 입력해주면 위와 같은 화면을 통해 여러 정보들을 알 수 있습니다.
파일의 이름, 해시값, PDF 버전, 업데이트 횟수, 전체 객체 수, 스트림 수 등을 알려줍니다.
스트림이란 PDF 파일의 주요 데이터를 저장하는 영역을 말합니다.
저는 위의 화면에서 힌트가 될 만한 부분은 아래와 같다고 판단했습니다.
- Updates : 1번이라는 뜻은 파일 생성 이후 중간에 수정되었다는 의미
- Streams 에서 Encoded : 39번 객체가 인코딩됨
- Objects With JS code : Javascript 코드가 포함된 객체
- OpenAction : PDF가 열릴 때 자동으로 실행되는 동작을 하는 객체
따라서 저는 수상한 객체를 37, 39라고 생각했습니다.
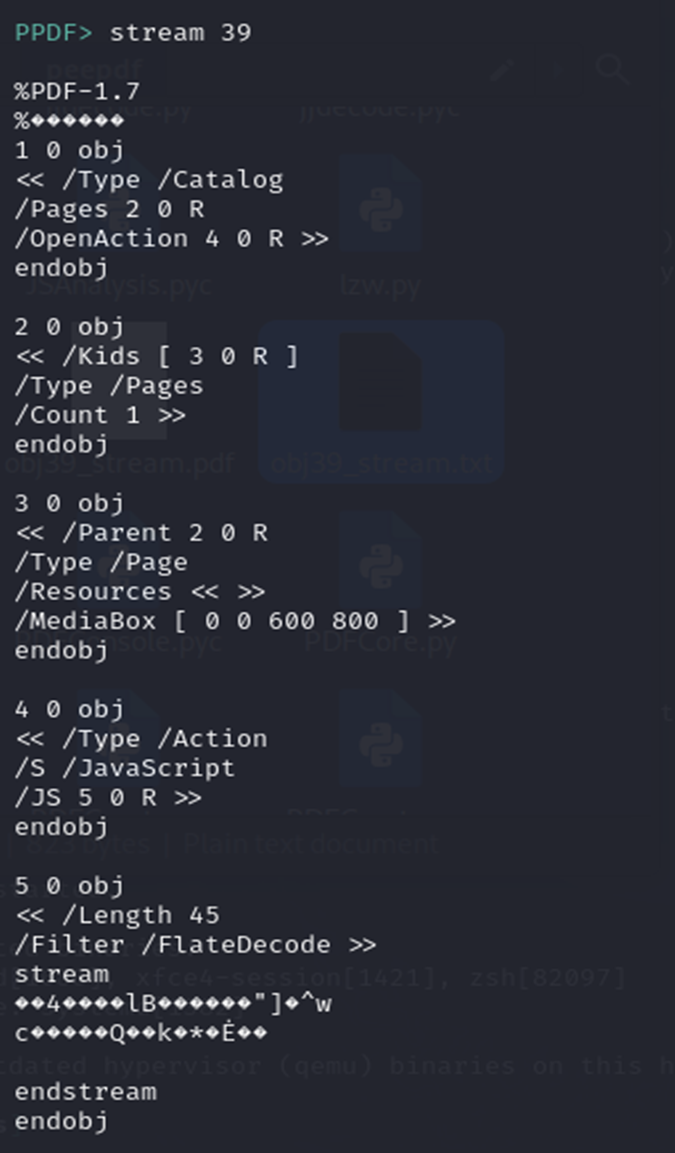
peepdf.py 실행 후,stream 39 라는 명령어를 이용하여 가장 수상했던 39번 객체의 데이터 정보를 알 수 있었습니다.
첫 번째 줄의 %PDF-1.7 는 PDF의 파일 시그니처 헤더를 의미합니다. 또한 1.7은 PDF 파일의 버전을 의미하게 됩니다.
파일 시그니처는 파일의 가장 처음에 위치하는 특정 바이트들로 파일 포맷을 구분하기 위해 사용됩니다.
확장자마다 고유의 파일 시그니처가 존재합니다.
Hello_SuNiNaTaS의 PDF 파일 시그니처가 아닌 전체 파일 안의 객체에서 PDF 파일 시그니처가 나왔다는 것은 또 다른 파일이 숨어있다고 추측해볼 수 있습니다.
두 번째로, Hello_SuNiNaTaS의 PDF 파일의 버전은 1.4였습니다. 이를 통해 다른 PDF 버전을 사용했으며, 숨겨진 파일이 있다는 것을 어느 정도 확신할 수 있습니다.

위의 사실을 통해 stream 39 > obj39_stream.pdf 명령어로 추출을 해주었습니다.

추출한 파일을 위와 같은 명령어로 다시 한 번 데이터 정보를 확인했습니다.
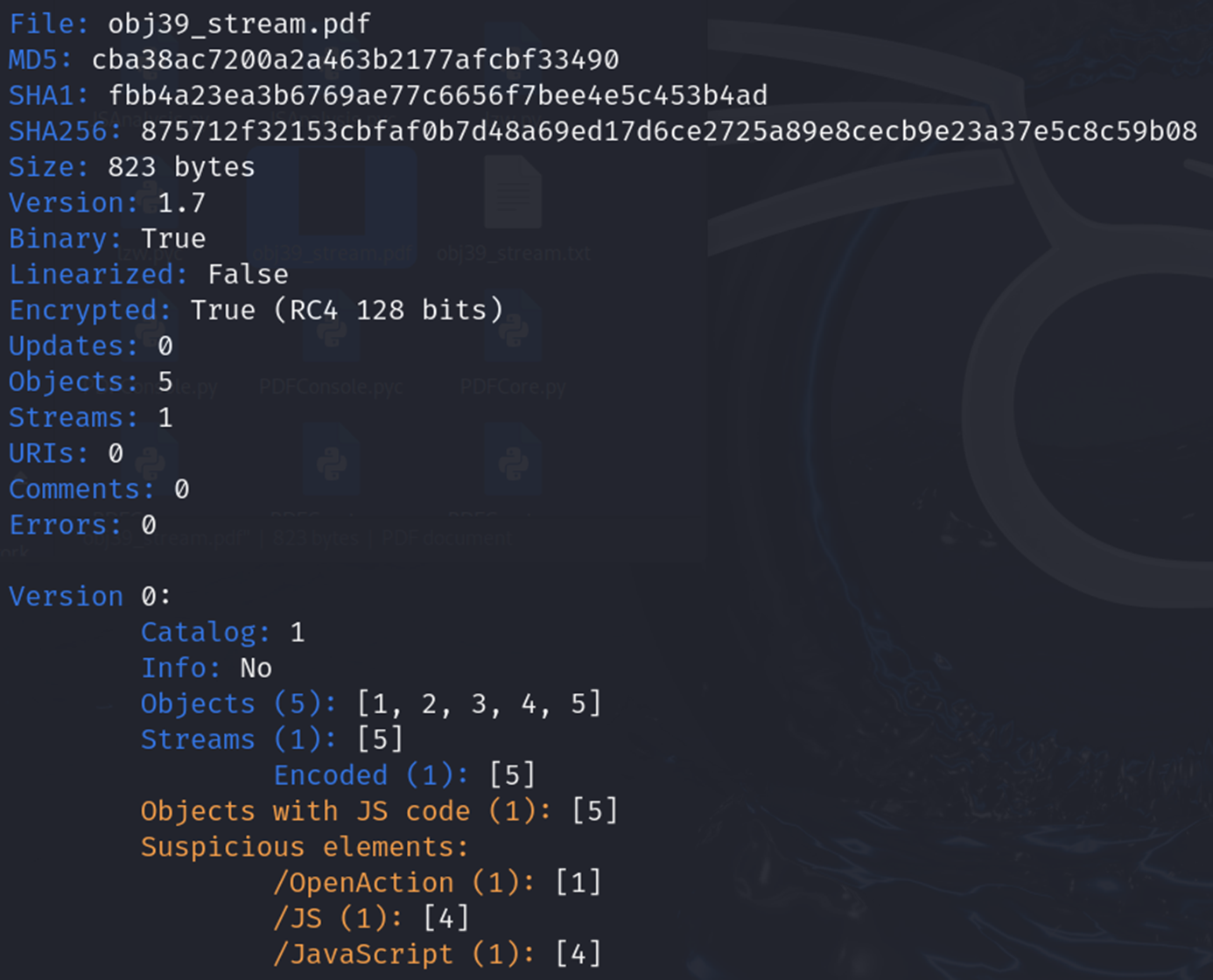
obj39_stream.pdf 파일의 데이터 정보를 위의 사진에서처럼 볼 수 있었는데, Streams에서 Encoded 된 5번 객체가 스트림 데이터로 압축되어 있음을 알 수 있었습니다.

5번 객체의 데이터 정보를 stream 5를 통해 입력하니 아래와 같이 Flag가 제공되었습니다.
이를 문제에서 제시한 인증키 형식인 MD5 해시값으로 바꿔준 후 입력하면, 성공입니다!
+
안티포렌식 기법 중 스테가노그래피 기법을 적용한 이미지 파일 문제는 몇 번 봤었는데 PDF 문제는 처음 접했던 것이라 새로웠고 재밌었습니다. 새로운 포렌식 도구를 알 수 있는 기회였습니다.
이 문제를 통해 세미나에서 발표할 때, 안티 포렌식이 사용된 문제 예시를 적절하게 들 수 있었습니다.
