
리액트에서 리스트 형태로 컴포넌트를 렌더링 할때, key값을 넣어 달라는 console 에러가 자주 뜬다.
이 key값이 어떤 역할을 하는지 리액트 공식 문서에서 설명을 해주고 있지만, 내부적으로 컴포넌트를 어떻게 다시 그려주는지 모르고 있어서 이를 알기 위해서 블로그를 적어 본다.
리액트 공식 문서 key설명
- key는 엘리먼트 리스트를 만들 때 포함해야 하는 특수한 문자열 어트리뷰트입니다
- Key는 React가 어떤 항목을 변경, 추가 또는 삭제할지 식별하는 것을 돕습니다.
- key는 엘리먼트에 안정적인 고유성을 부여하기 위해 배열 내부의 엘리먼트에 지정해야 합니다.
- 항목의 순서가 바뀔 수 있는 경우 key에 인덱스를 사용하는 것은 권장하지 않습니다. 이로 인해 성능이 저하되거나 컴포넌트의 state와 관련된 문제가 발생할 수 있습니다. 만약 리스트 항목에 명시적으로 key를 지정하지 않으면 React는 기본적으로 인덱스를 key로 사용합니다.
위의 설명처럼 리액트에서 key는 컴포넌트 리스트를 렌더링 했을 때 어떤 원소에 변동이 있었는지 알아내기 위해 사용한다. 유동적인 데이터를 다룰 때, 리스트의 중간에 새로운 컴포넌트가 추가될 수도, 삭제될 수도 있다.
key가 없는 경우는 가상 DOM에를 비교하는 과정에서 리스트를 순차적으로 비교하여 변화를 감지한다. 하지만 key가 있다면 이 값을 사용하여 어떤 변화가 있었는지 더욱 빠르게 알아낼 수 있다.
고유한 키값을 잘 넣어준다면 VDOM과 realDOM사이의 리스트간 변화를 빠르게 알아 차릴 수 있다는 것이다.
key를 index로 사용 하면 발생하는 문제
위의 설명에서 항목의 순서가 바뀔 수 있는 경우 key를 index로 사용 하면 어떤 문제가 생기는지 알아보자.
아래의 코드는 첫 번째 줄의 input에 있는 값 add 버튼을 눌렀을 때 배열의 첫 번째 값으로 넣어주고 컴포넌트 형태로 보여주는 간단한 코드이다.
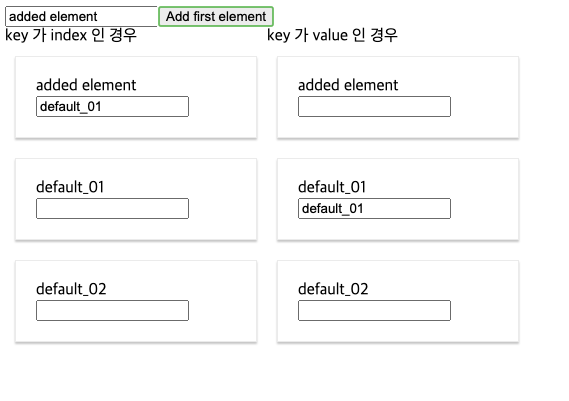
왼쪽 컴포넌트는 key가 index인 경우, 오른쪽 컴포넌트는 key가 고유한 특정 절댓값으로 있는 경우를 각각 보여준다.
['default_01','default_02'] -> ['fitst_element','default_01','default_02']Result에서 input에 임의의 값을 넣은 후 add first element 버튼을 눌러보자.

버튼 클릭 전
버튼 클릭 후
key를 value인 고유 값으로 사용 하는 경우 리렌더링 이후 input값들도 뒤로 잘 밀려나지만,
key를 index로 사용 하는 경우 input에 있는 값들이 뒤로 밀려나야 하지만 원하지 않는 결과가 생기는 경우를 볼 수 있다.
왜 이런 현상이 일어나는 것일까? 아래에서 리액트에서 vDOM을 DOM에 적용하는 절차를 확인해보자.
재조정(Relconciliation)
위에서 에러가 발생하는 이유는 리액트 공식 문서 재조정(Relconciliation)에서 찾아 볼 수 있다.
위의 문제의 원인을 알기 앞서 리액트에서 어떤 형식으로 컴포넌트를 부분적으로 다시 그리는지 알아야 할 필요가 있다.
재조정이란 ?
React에서 state나 props가 갱신되면, render()함수를 다시 부르게 되고 새로운 DOM tree를 반환하게 됩니다. 이때 React는 방금만들어진 element를 효과적으로 브라우저에 갱신해야 합니다.
리액트는 virtual DOM이라는 변경된 tree에서 전체가 아닌, 일부분 변경된 tree부분만 변경을 해주는 자체적인 로직을 가지고 있고, 이를 위해 기존의 tree(realDOM)와 변경된 tree(virtual DOM)를 비교해주는 절차(Diffing Algorithm)를 가지게 됩니다.
이를 일일이 비교해 주게 된다면, O(n^3)만큼의 비교가 필요합니다. 하지만 리액트는 두가지 가정을 기반으로 O(n)의 복작도를 가지는 휴리스틱 알고리즘을 구현했습니다.
결론: 모두 비교하지 않고 제한 조건(key)을 걸어두겠다
1. 서로 다른 타입의 두 엘리먼트는 서로 다른 트리를 만들어낸다.
2. 개발자가 key prop을 통해, 여러 렌더링 사이에서 어떤 자식 엘리먼트가 변경되지 않아야 할지 표시해 줄 수 있다.
React에서는 컴포넌트의 갱신을 렌더링에 반영할지 비교 알고리즘 (Diffing Algorithm)을 통해 내부적으로 동작하고있습니다.
비교 알고리즘 (Diffing Algorithm)**은 아래와 같은 절차를 통해 동작합니다.
1. 첫번째로 엘리먼트타입이 달라지는 경우, React는 이전 트리를 버리고 완전히 새로운 트리를 구축합니다.
<div>
<Counter />
</div>
<span>
<Counter />
</span>이렇게 루트 노드가 변경 된다면 리액트에서는 기존의 DOM노드를 완전 새로운 DOM노드로 변경을 하고 Counter 컴포넌트에서는 라이프사이클 함수인componentWillUnmount가 불리게 될겁니다.
2. 두번째로 DOM 엘리먼트의 타입이 같은 경우, React는 동일한 내역은 유지하고 변경된 속성만 갱신합니다.
<div className="before" title="stuff" />
<div className="after" title="stuff" />위와 같은 경우에서는 react는 DOM노드 상에서 className만 수정을하게 됩니다.
DOM 노드의 처리가 끝나면, React는 이어서 해당 노드의 자식들을 재귀적으로 처리합니다.
자식에 대한 재귀적 처리
DOM노드의 자식들을 재귀적으로 처리할때, React는 동시에 두 리스트를 순회하고 차이점이 있으면 변경을 생성합니다.
리액트에서 자식들이 key를 가지고 있다면, key를 통해 기존 트리와 이후 트리의 자식이 일치하는지 확인합니다.
예를들어 아래와 같이 key가 없다면 Duke와 Villanova는 같은 컴포넌트이더라도 기존의 트리는 제거 되고 새로운 컴포넌트로 다시 그려지게 됩니다.
<ul>
<li>Duke</li>
<li>Villanova</li>
</ul>
<ul>
<li>Connecticut</li>
<li>Duke</li>
<li>Villanova</li>
</ul>반면에 아래와 같이 key가 같다면 있다면 컴포넌트는 사라지지 않고 이동만 하면 되는 것을 React는 알 수 있습니다.
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>리액트는 이러한 Virtual DOM과 Real DOM의 변경사항을 확인 하는 휴리스틱한 Diffing 알고리즘을 통해, O(n^3)의 시간이 걸리는 비교 알고리즘을 O(n)으로 줄일 수 있었습니다.
key를 index로 사용 하면 어떤 문제가 발생 하는가 ?
다시 위의 예제러 돌아가서, 그렇다면 key를 index로 사용 했을때, 왜 Input의 값이 밀리지 않고 가만히 있었던 걸까요?
// 변경 전
<ul>
<li key="1">Duke</li>
<li key="2">Villanova</li>
</ul>
// 변경 후
<ul>
<li key="1">Connecticut</li>
<li key="2">Duke</li>
<li key="3">Villanova</li>
</ul>위에서 발생한 key를 index로 사용 하고, 처음 순환 요소로 새로운 컴포넌트가 들어오게 된다면, React는 기존의 첫번째 컴포넌트와 새로운 컴포넌트가 같은 key값을 가지고 있으니 같은 컴포넌트라 생각하게 되어 기존의 컴포넌트를 그대로 그려주게 될것입니다.
<li key="1">Duke</li>
<li key="1">Connecticut</li>
React: 위 컴포넌트는 key값이 같으니 똑같은 컴포넌트 군 ! 예외 사항
unique한 id를 쓸만한게 없다면 ?
하지만 고유한 id값을 가지고 있지 않는 경우가 있을 것입니다.
이럴 때, 아래 3가지를 만족한다면 안심하고 key를 index로 사용해도 문제는 없을것입니다.
- 배열과 각 요소가 static이며 computed 되지 않고 변하지 않아야 한다.
- 데이터 내부에 id로 쓸만한 unique 값이 없을 경우
- 데이터가 결코 reordered or filtered 되지 않을 경우
결국 순서가 변하지 않고, 추가 삭제 될 일이 없는 list라면 key값으로 index를 사용하더라도 문제 없을 것입니다.
Math.random를 key로 사용해도 되나요 ?
추가적으로 key는 반드시 변하지 않고, 예상 가능하며, 유일해야 합니다. 변하는 key(Math.random()으로 생성된 값 등)를 사용하면 많은 컴포넌트 인스턴스와 DOM 노드를 불필요하게 재생성하여 성능이 나빠지거나 자식 컴포넌트의 state가 유실될 수 있다.
nanoid를 key로 사용해도 되나요 ?
nanoid 와 같은 unique한 값을 만들어 사용하는 방식은 nanoid에서도 지양하고 있다.
클라이언트 레벨에서 nanoid를 리렌더링시 매번 만드는 작업이 위 Math.random과 같은 이유로 사용을 금지하고 있지만, 백엔드에서 데이터 레벨에서 id를 세팅 후 넘겨준다면, id가 특정 데이터에 대해서 변경되지 않음을 보장할 수 있다면 사용 해도 괜찮을 것으로 보인다.
참고 : https://github.com/ai/nanoid#react
nonoid 에서는 react18의 useId hooks를 사용하라고 권장하고 있지만,
react docs에서는 useId를 key로 사용하는 것을 권장하지 않는다.
참고 : https://reactjs.org/docs/hooks-reference.html#useid
출처
https://robinpokorny.medium.com/index-as-a-key-is-an-anti-pattern-e0349aece318
