
5. 딥러닝 기초
신경망이란, 선형모델과 활성함수를 합성한 함수를 뜻한다.
 기본적 선형모델
기본적 선형모델
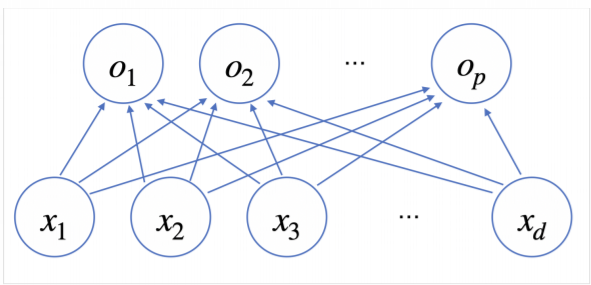
- 개의 변수 [] * 연산 => 개의 선형모델 []
선형모델을 살펴보면, 선형모델로 출력된 값은 확률벡터가 아닌 경우가 많기 때문에, 특정 벡터가 어떤 class 에 속할 확률을 계산하기 위해 소프트맥스 연산을 해주게 된다.
softmax 연산
- 모델의 출력을 확률로 해석할 수 있게 변환해 주는 연산
분류문제의 경우 softmax를, 추론문제의 경우 one hot vector를 사용한다.
학습이 아닌 추론의 경우 출력값 중 최대값만 1로 출력하는 연산을 사용하면 되기 때문에, 굳이 softmax 함수를 사용하지 않는다.
활성함수
입력 신호의 총합을 출력 신호로 변환하는 비선형함수이다. 선형모델로 나오는 출력물 각각의 원소에 적용한다.
잠재벡터(또는 히든벡터) 의 각 노드에 개별적으로 적용해, 새로운 잠재벡터(뉴런 네트워크) 를 만든다
softmax : 출력물 모든 값에 적용
활성함수 : 출력물 각각의 원소에 적용
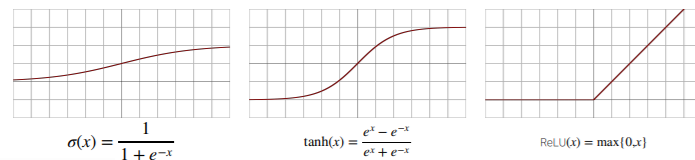
시그모이도(sigmoid)함수나 tanh함수의 경우 전통적으로 많이 쓰여 왔고, 현재 딥러닝에서는 ReLU 함수를 많이 쓰고 있다. (선형함수처럼 보이지만 비선형 함수이다.)
신경망은 선형모델과 활성함수를 합성한 함수인데,
입력받는 data인 x를 (1) 선형변환 하고, 각 벡터에 (1-2) 활성함수를 개별적으로 적용한 수 다시 (2) 선형변환해서 출력하게 되면 ()를 parameter로 가지는 2층(2-layers) 신경망이고, 이를 반복하면 다중(multi-layers) 신경망이다.
 2층 신경망
2층 신경망
 다층 신경망
다층 신경망
x
-> z = # (1)
-> = , H = # (1-2)
-> O = # (2)
이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있지만 (universal approximation theorem) 층이 깊을수록 적은 parameter로 복잡한 함수를 표현할 수 있어 더 효율적으로 학습이 가능하다. 단, 층이 깊으면 복잡한 함수를 더 잘 근사하는 것이지 최적화가 쉽다는 것은 아니다.
역전파 알고리즘(backpropagation)
까지 순차적 신경망 계산을 순전파(forward propagation)라 부른다. 순전파는 학습이 아닌, 주어진 입력으로 여러 층의 신경망을 따라 출력을 만들어 가는 과정이다.
딥러닝은 역전파 알고리즘으로 각 층에 사용된 parameter를 학습한다.
피어세션
Moore-Penrose Inverse 관련 질문
Q1. AI Math 2. 행렬이 뭐에요 강의 자료 37pg에서 Moore-Penrose 역행렬을 구할 때 Incercept 열 [1]을 직접 추가하는 이유가 무엇일까?

A. 
Q2. Moore-Penrose Inverse vs sklearn의 LinearRegression이 동일한 값이 나오지 않는 이유는 무엇일까?
A2. ppt 내용은 (2) 비선형모델 예시이지만, (1)선형모델로 test해 보면 동일한 값이 나오는 것을 확인할 수 있다. numpy에서 수행한 근사치라고 충분히 볼만한 값이 아닌가?
(1)


(2)
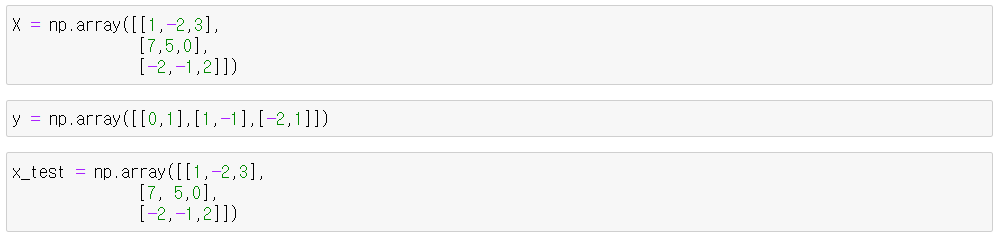
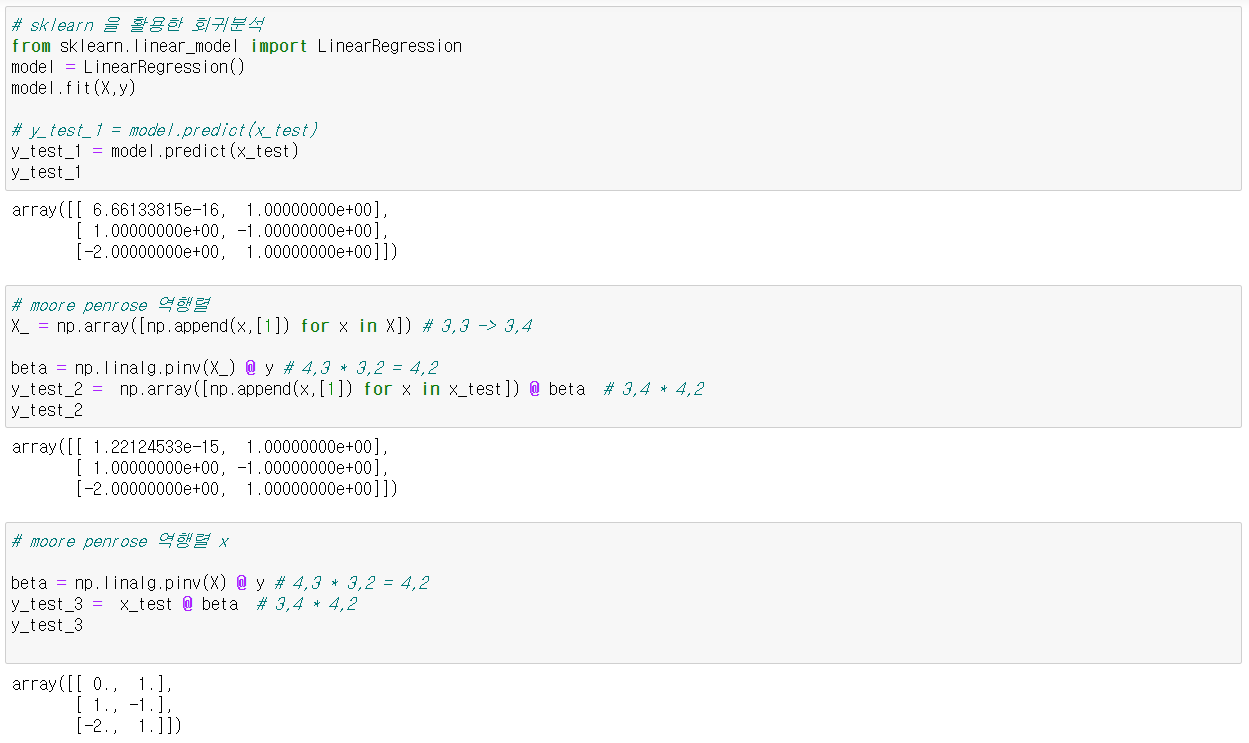
즉 우리가 알 수 있는 것은,
- 연립방정식에 완전히 fit 할 수 있는 X matrix 예시라면 (i) sklearn.linear_model.LinearRegression()과 (ii) np.linalg.pinv() 결과값은 같다.
- 이때 Moore Penrose 역행렬에 column of [1]을 추가하지 않으면 sklearn.linear_model.LinearRegression()으로 구한 결과값이 다르게 된다.
회고
- 공부는 혼자 하는게 아니다! 라는 것을 체감한 하루였다. 밤에 혼자 공부하며 머리를 싸맸는데, 피어세션에서 팀원들과 같이 논의하며 궁금증을 해결할 수 있었다.
- 앞으로도 집단지성의 힘을 믿고 팀원들, 멘토분들, 커뮤니티 등 궁금한 게 있으면 언제든 질문해야겠다. 🤗
