🧠 앙상블 기법이란?
- 여러 개의 모델을 결합해서 더 좋은 성능을 내는 기법
- '알고리즘'이라기 보단 '카테고리'. '여러 알고리즘들 중에서 앙상블 기법을 쓰고 있는 것들'이라는 표현이 정확
🎯 앙상블의 주요 종류 3가지
| 구분 | 설명 | 특징 | 대표 알고리즘 |
|---|---|---|---|
| Voting | 여러 모델의 결과를 조합 (동일 데이터 / 다른 모델) | 단순 조합 | VotingClassifier, Random Forest(soft voting, bagging 둘다 사용) |
| Bagging | 여러 모델을 병렬로 학습시켜서 평균/투표 (다른 데이터 / 동일 모델) *전체 데이터셋에서 데이터를 샘플링함. 데이터 샘플링 시 데이터 중복 허용 | 데이터를 다르게 샘플링 | Random Forest |
| Boosting | 약한 모델을 순차적으로 강화 | 오류 보정에 집중 | Gradient Boosting, XGBoost, LightGBM, AdaBoost |
| Stacking | 다양한 모델을 결합 + 최종 모델로 조합 | 결과를 다시 학습 | 여러 모델 조합 가능 |
1. Voting (투표 방식 앙상블)
- 여러 다른 모델들의 예측 결과를 모아 투표해서 최종 결과를 결정하는 방법
- 동일한 데이터 / 다른 모델
Voting 종류 2가지
| 방식 | 설명 | 특징 |
|---|---|---|
| Hard Voting | 모델들이 예측한 클래스 라벨 자체를 투표해서 가장 많이 나온 걸 선택 | 다수결 |
| Soft Voting | 모델들이 출력한 클래스 확률(probability)을 평균낸 다음, 가장 높은 확률을 가진 클래스를 선택 | 확률 기반 |
Hard Voting (다수결)
- 모델 A: 0, 모델 B: 1, 모델 C: 1인 경우,
→ 0 vs 1 → 1이 두 번 나왔으니까 최종 예측은 1
from sklearn.ensemble import VotingClassifier
voting_hard = VotingClassifier(
estimators=[
('lr', LogisticRegression()),
('knn', KNeighborsClassifier()),
('dt', DecisionTreeClassifier())
],
voting='hard' # hard voting
)Soft Voting (확률 평균)
- 모델 A: [0.2, 0.8], 모델 B: [0.6, 0.4], 모델 C: [0.1, 0.9] (=> 확률 출력)
- 평균: [0.3, 0.7]
→ 둘 중에 0.7로 높은 클래스 1을 최종 선택
voting_soft = VotingClassifier(
estimators=[
('lr', LogisticRegression(probability=True)),
('knn', KNeighborsClassifier()),
('dt', DecisionTreeClassifier())
],
voting='soft' # soft voting
)
(주의: soft voting은 확률 출력이 가능한 모델이어야 함)
2. Bagging (Bootstrap Aggregating)
- 데이터를 중복을 허용해서 샘플링하고, 그 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정함
→ 같은 모델 여러 개를 서로 다른 데이터로 학습시키는 것 - 예측은 평균 (회귀) 또는 다수결 (분류)
- 병렬로 학습 가능해서 빠름
- 대표적인 예: 랜덤포레스트 (RandomForest)
- 부트스트래핑으로 샘플링된 데이터마다 결정나무가 예측한 결과를 소프트보팅으로 최종 예측 결론을 얻음
- 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식을 부트스트래핑(bootstrapping) 분할 방식이라고 한다.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)3. Boosting
- 약한 모델(보통 얕은 트리)을 하나씩 순차적으로 학습
- 이전 모델이 틀린 데이터를 더 잘 맞추도록 보완
- 성능 좋음 (근데 느릴 수 있음)
- 대표 알고리즘:
- Gradient Boosting
- XGBoost (속도 빠름 + 정교함)
- LightGBM (대용량 데이터에 유리)
- AdaBoost (가중치 조절 방식)
from xgboost import XGBClassifier
model = XGBClassifier()4. Stacking
- 여러 서로 다른 모델들을 조합 (ex. 로지스틱 + 랜덤포레스트 + SVM)
- 이들의 예측 결과를 메타 모델이 받아서 다시 최종 예측!
- 보통 가장 좋은 성능 나옴 (하지만 복잡하고 튜닝도 많음)
from sklearn.ensemble import StackingClassifier
estimators = [
('rf', RandomForestClassifier()),
('knn', KNeighborsClassifier()),
]
stack_model = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())💡 앙상블 기법의 장점
✔️ 성능 향상 가능성 큼 (특히 Boosting)
✔️ 과적합 방지 효과 있음 (Bagging)
✔️ 다양한 모델을 조합 가능 (Stacking)
❗주의할 점
⚠️ 느릴 수 있음 (특히 Boosting, Stacking)
⚠️ 모델 간 균형, 하이퍼파라미터 튜닝 필요
⚠️ 이해도 없이 쓰면 블랙박스처럼 됨
📌 요약
| 앙상블 종류 | 특징 | 대표 모델 |
|---|---|---|
| Bagging | 병렬 / 분산 → 과적합 줄임 | RandomForest |
| Boosting | 순차 / 성능 강화 → 편향 줄임 | XGBoost, LightGBM, AdaBoost |
| Stacking | 서로 다른 모델 조합 → 최종 예측 | 다양한 모델 조합 가능 |
실습
실습 데이터
- HAR, Human Activity Recognition
- 클래스 - Walking Upstairs, Standing, Walking Downstairs, Sitting, Laying, Walking
1) Decision Tree
Label Encoder 적용:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train.to_numpy().ravel())
y_test = le.transform(y_test.to_numpy().ravel())Decision Tree로 학습:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)=> accuracy score: 0.80963
2) Decision Tree + GridSearchCV
from sklearn.model_selection import GridSearchCV
params = {
'max_depth': [6, 8, 10, 12, 16, 20, 24] # 이건 내맘
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
grid_cv.best_score_, grid_cv.best_params_
# max_depth가 8일때. 85%
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred1)
accuracy=> accuracy score: 0.873430
3) Random Forest + GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth': [6, 8, 10],
'n_estimators': [50, 100, 200],
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['rank_test_score', 'param_max_depth', 'param_n_estimators', 'mean_test_score', 'mean_test_score']]RandomForest 생성 후 GridSearchCV로 돌려준 다음, cv_results_ 속성을 데이터프레임으로 만들어주었다.
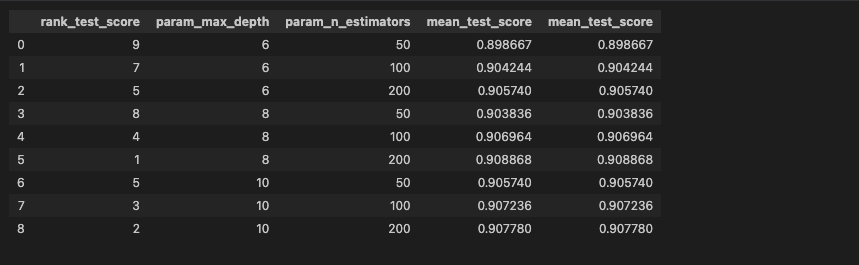
궁금한 것들 몇개만 뽑아서 보니, 이렇게 나왔다.
best_estimator_ 로 다시 훈련:
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(X_train, y_train)
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols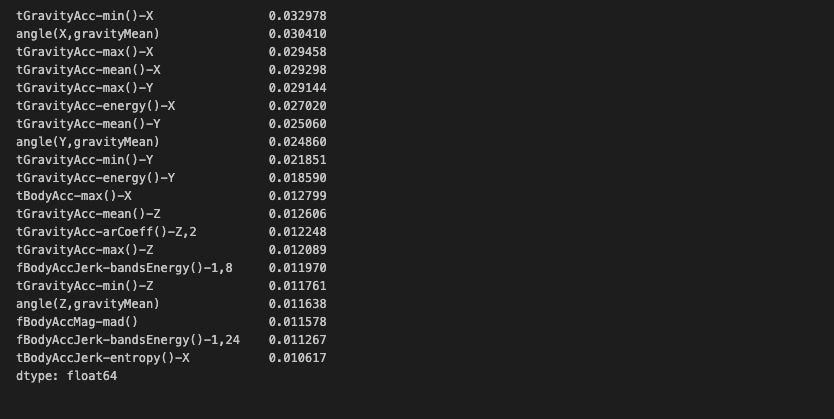
feature_importances_를 뽑아서, 상위 20개를 추출해보았다.
근데 컬럼간 차이가 크지 않아서 골고루 중요하단걸 알 수 있다.
이걸 갖고 그래프로 그려보면:
import seaborn as sns
plt.figure(figsize=(10, 7))
sns.barplot(x=top20_cols.values, y=top20_cols.index)
plt.show()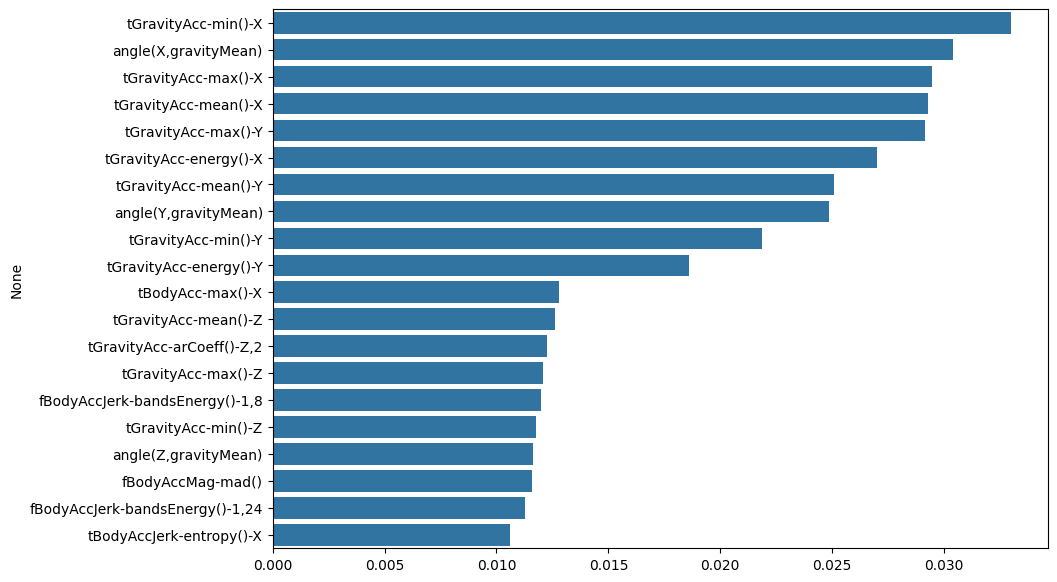
상위 5개 정도까지가 특히 중요했다는 것을 알 수 있다.
상위 20개 특성으로 다시 모델을 돌려보면:
X_train_re = X_train[top20_cols.index] # reduce
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train)
pred_re = rf_clf_best_re.predict(X_test_re)
accuracy = accuracy_score(y_test, pred_re)
accuracy=> accuracy score: 0.808279
정리:
데이터셋의 561개의 특성을 다 돌리려면 시스템에 너무 부담일 수 있다.
이럴 때에는 성능을 조금 포기하더라도 연산량을 줄이는게 나은 선택이 될 수 있다.
컬럼을 5개로 선정하면 정확도 63%가 나왔는데, 전체 561개 중 단 5개로 63% 성능이면 나쁘지 않다는 판단이다. 돌려보니 5개로 했을 때와 10개로 했을 때가 별 차이가 없었고, 100개로 했을 때엔 89%였다. 즉, '20개'라는 숫자가 중요하다고 볼 수 있을 것 같다.
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)
