
🧠 k-최근접 이웃 (k-Nearest Neighbors, kNN)
“모르는 애가 있으면, 가까운 애들(k명)한테 물어보고 다수결로 결정하자!”
- 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제
- k는 몇번째 가까운 데이터까지 볼 것인가를 정하는 수치
📌 핵심 아이디어
- 어떤 데이터를 분류하거나 예측할 때,
- 그 데이터와 가장 가까운 k개의 이웃을 찾아서,
- 그 이웃들의 결과를 참고해서 결정하는 것
예시
어떤 장소에 피자 집을 새로 열고 싶다고 가정,
- 고민: "여기 오면 사람들이 피자를 시킬까?"
- 주변에 이미 피자 가게 잘 되는 동네들이 있다.
- 그럼 새로운 장소 근처 가까운 k개 동네를 보고, 피자 가게가 많은 쪽이면 피자집 내는 식
⚙️ 작동 방식
- 예측하고 싶은 데이터 포인트가 있음
- 기존 데이터들과의 거리를 계산함 (유클리디안 거리 보통 사용)
- 가장 가까운 k개의 데이터를 선택
- 그 k개의 레이블 다수결로 분류 (분류 문제일 경우)
- 예: k=3, 이웃들 라벨이 [0, 1, 1] → 결과는 1
- 회귀 문제일 경우 → 평균값을 취함
📏 거리 계산 방법
보통은 유클리디안 거리 사용 (유클리드 거리):
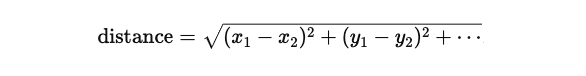
📌 그래서 스케일링이 중요함!
어떤 feature는 01인데 어떤 feature는 01000이면 거리 계산이 왜곡됨!
💡 주요 파라미터
n_neighbors: 몇 명한테 물어볼 거냐? (k 값)weights:'uniform'= 모두 동일한 가중치'distance'= 가까운 애들한테 더 큰 영향 부여
metric: 거리 계산 방식 (보통은 'minkowski', 그 안에 유클리디안 포함)
⚠️ kNN의 단점
| 문제점 | 설명 |
|---|---|
| 느림 | 새로운 데이터 들어올 때마다 모든 거리 계산해야 됨 (훈련은 빠름) |
| 차원의 저주 | Feature가 많아지면 거리 계산이 의미 없어짐 |
| 이상치 영향 | 주변에 이상치가 있으면 결과에 방해될 수 있음 |
실습
이번엔 오랜만에 iris 데이터로 실습~
iris 데이터 불러오고, data split:
from sklearn.datasets import load_iris
iris = load_iris()from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2,
random_state=13, stratify=iris.target)kNeighborsClassifier 불러오고 fit:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)accuracy 확인:
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
accuracy_score(y_test, pred)
96%. 간단한 데이터여서 그런지 n_neighbors=3을 줘도 acc가 동일했다.
confusion matrix와 classification report로 간단한 성과 확인:
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))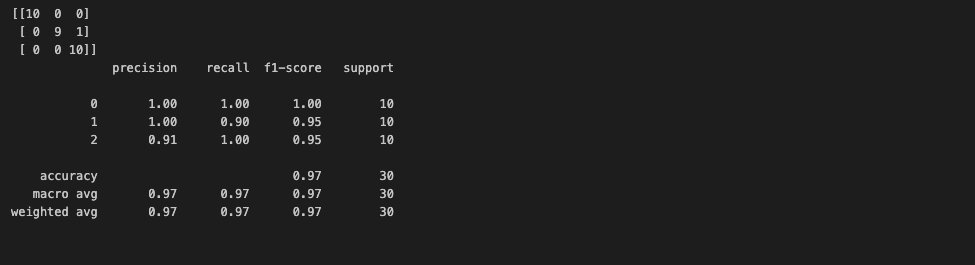
다시, confusion matrix의 형태는,
row - 실제 라벨 / 열 - 예측값
끄읕. 😄
(이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.)

데이터 엔지니어 도전기 / 스터디 노트