Machine Learning에 대해 알아보자
1.[Machine Learning] Iris Classification (1)
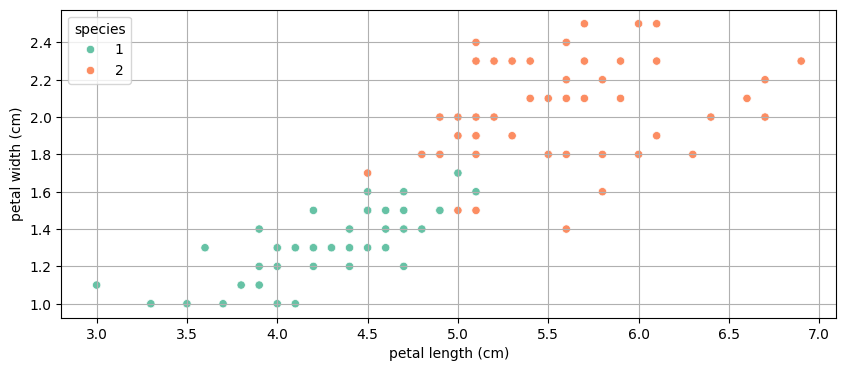
간단히 말해서, 기계한테 데이터를 주고 학습을 시켜서 내가 원하는 문제에 대한 답을 찾아내도록 하는 것.머신 러닝계에서 가장 유명한 데이터셋 중 하나가 Iris라고 함.Iris의 품종은 Versicolor, Virginica, Setosa가 있는데, 위 데이터셋을 통해
2.[Machine Learning] Iris Classification with Decision Tree
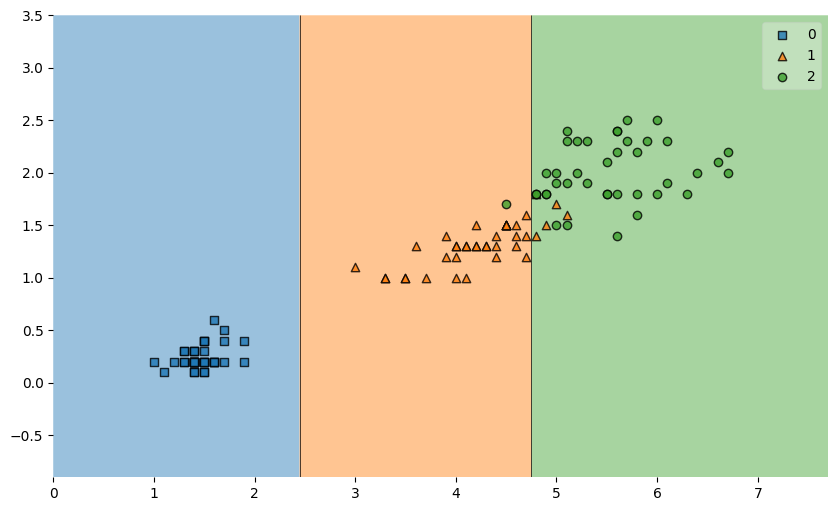
과적합이란 개념이 등장한다일단 머신 러닝의 일반적인 절차는, 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고,모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것일단 우리는 DecisionTreeClassifier를 통해 ac
3.[Machine Learning] 머신러닝의 종류
지도학습: 정답을 주고 학습시키는 것비지도학습: 정답이 없음강화학습 (제로베이스 데이터스쿨 과정에서는 다루지 않음)데이터를 보고 정해진 카테고리 중 하나로 분류하는 모델새로운 Instance를 주었을 때 어떤 Label을 붙일지 결정하는 모델. 예를 들어:이메일이 스팸
4.[Machine Learning] Regression & Linear Regression (OLS)
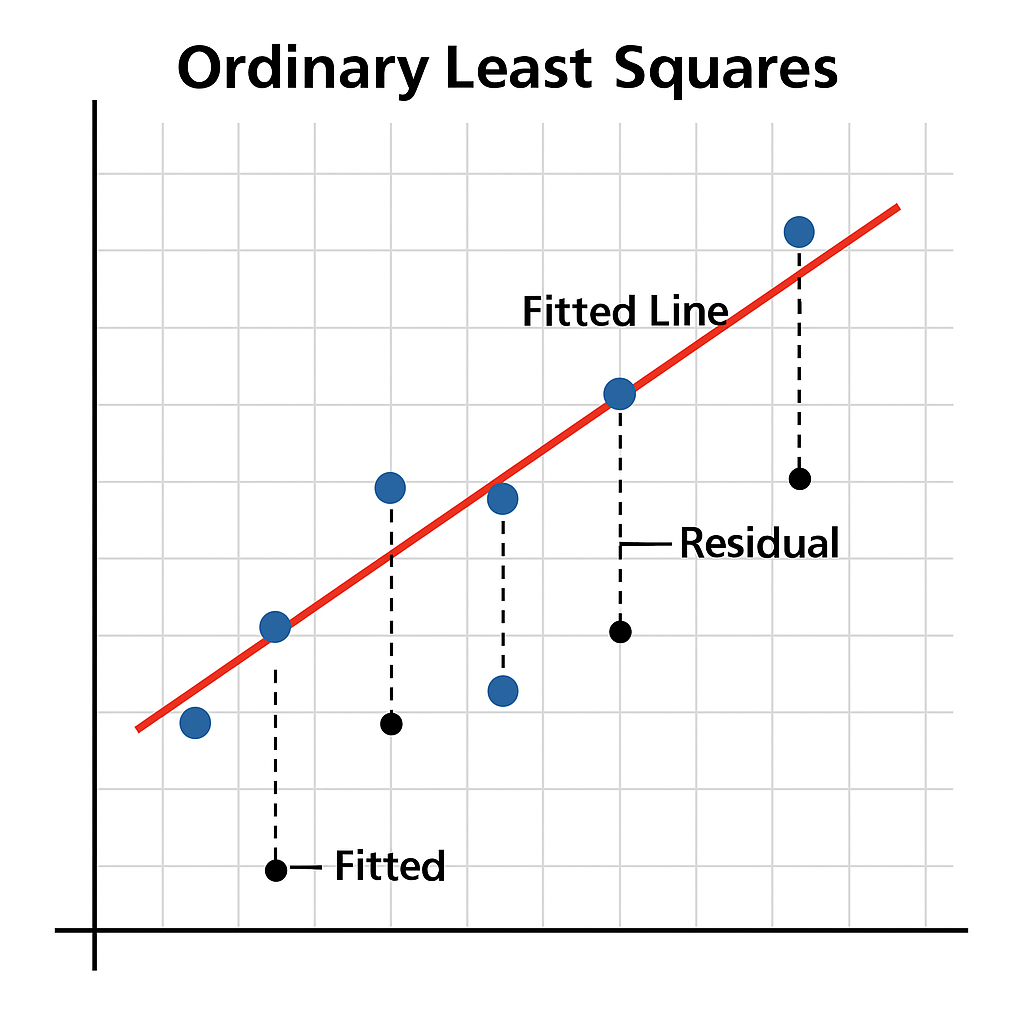
학습 데이터셋에는 주택 규모(㎡)와 주택 가격이 들어가 있음.그리고 주택 규모에 따른 가격을 예측하는 모델을 만들고 싶다.✔️ 학습 데이터 각각에 정답(주택 가격)이 주어져 있으므로 지도학습(Supervised Learning)이며, ✔️ 주택 가격을 연속된 값으로 예
5.[Machine Learning] Encoder & Scaler (머신러닝에서의 전처리)

Encoder와 Scaler는 머신러닝에서 데이터 전처리할 때 자주 쓰이는 도구들이다.문자(텍스트) 데이터를 숫자로 바꾸는 데 주로 사용하는 Scikit-learn 도구에는 LabelEncoder & OneHotEncoder가 있다.문자(카테고리형 데이터)를 정수(0,
6.[Machine Learning] 모델 평가의 개념

모델이 얼마나 잘 예측했는지, 또는 얼마나 똑똑하게 학습했는지를 수치로 확인하는 과정"알아서 훈련이 잘 됐겠지" 하는게 아니라,실제 처음 보는 데이터에 대해서도 잘 맞추는지 확인해야 함.과적합/과소적합 여부도 평가 지표로 판단함회귀 모델은 실제 값과의 에러치를 가지고
7.[Machine Learning] 이진 분류에서의 모델 평가

이진 분류(Binary Classification) 모델은 머신러닝 분류 모델 중에서도 가장 기본이면서 실무에서도 자주 쓰이는 모델이다.결과가 두 가지 중 하나인 문제.예:메일인가 스팸인가?이 환자가 암인가 아닌가?고객이 이탈할까 안 할까?👉 이런 문제에서, 예측이
8.[Machine Learning] Decision Tree를 이용한 와인 데이터 분석
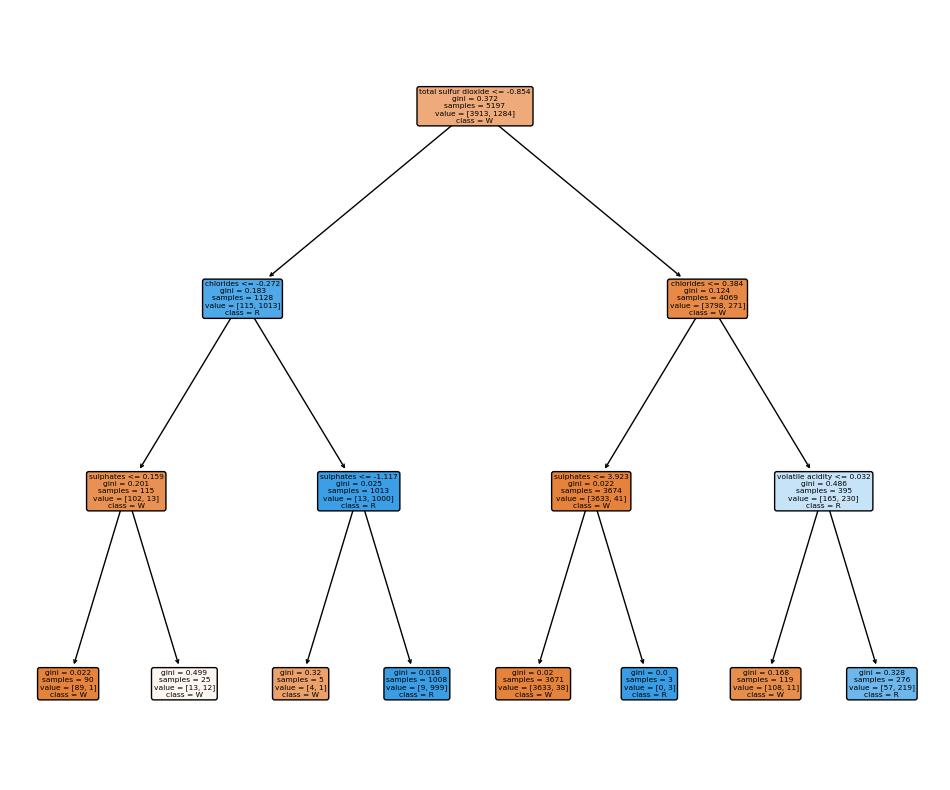
요런.. 와인 데이터셋이 있다.이런 정보들이 담겨있다.fixed acidity: 고정 산도volatile acidity: 휘발성 산도citric acid: 시트르산residual sugar: 잔류 당분chlorides: 염화물free sulfur dioxide: 자유
9.[Machine Learning] Pipeline
데이터 전처리부터 모델 학습까지의 과정을 하나로 묶어주는 도구👉 “데이터 → 스케일링 → 모델 학습” 이 흐름을 줄줄이 이어 붙여서 자동화하는 것코드 깔끔해짐실수 줄어듦 (예: 훈련/테스트 데이터에 같은 전처리 적용 안 했을 때)GridSearch 등 하이퍼파라미터
10.[Machine Learning] Logistic Regression

입력값들을 기반으로 어떤 데이터가 특정 클래스(예: 0 or 1 이진 분류)에 속할 확률을 예측하는 모델이름은 Regression(회귀)이지만 실제로는 이진 분류 문제에 많이 쓰인다. (분류기)선형 조합을 만들고직선 - 문제는 데이터가 x축 아주 오른쪽에 가있으면,?
11.[Machine Learning] 하이퍼파라미터 튜닝 & 교차 검증 실습
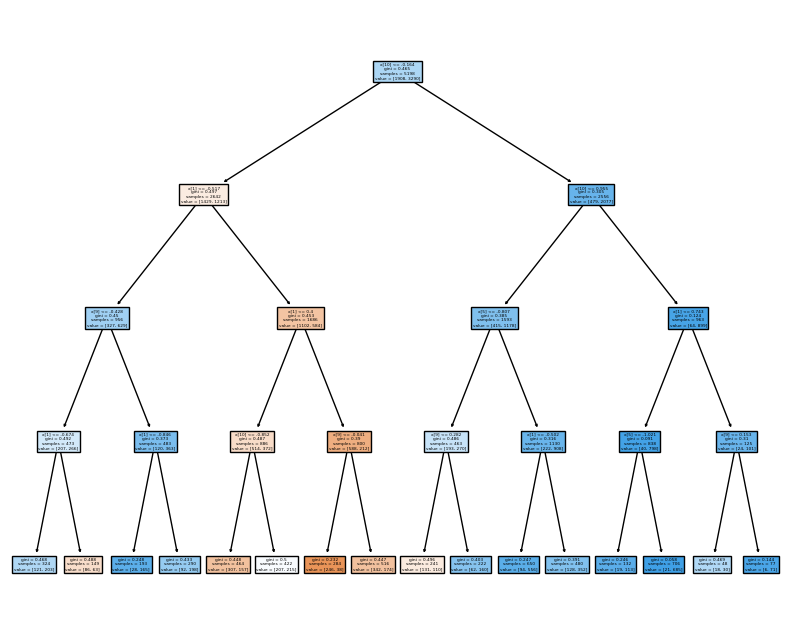
계속 다루고 있던 와인데이터로 실습~비교를 위해, 원래 하던 대로 DecisionTreeClassifier 만들고, accuracy 확인해보자.8:2로 train/test 데이터 나눠준 뒤,DecisionTreeClassifier를 선언했다. (max_depth 2로
12.[Machine Learning] Precision & Recall
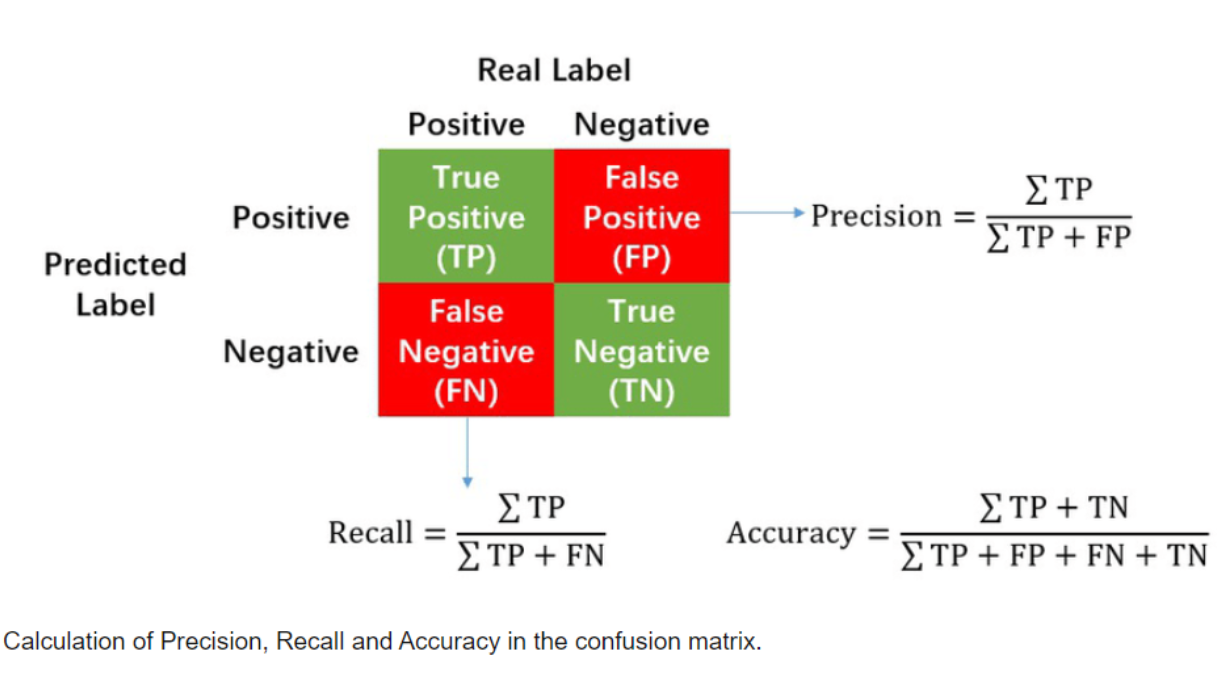
모델을 평가할 때, Accuracy 지표만 들여다보는 것으로 부족할 때가 있다.그래서 라벨 0인걸 몇개 맞췄느냐, 라벨 1인걸 몇개를 맞췄느냐 이런식으로 세부적으로 볼 수 있는 classification_report라는 기능이 있다. (precision / recall
13.[Machine Learning] k-최근접 이웃 (k-Nearest Neighbors, kNN)

“모르는 애가 있으면, 가까운 애들(k명)한테 물어보고 다수결로 결정하자!”새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제k는 몇번째 가까운 데이터까지 볼 것인가를 정하는 수치어떤 데이터를 분류하거나 예측할 때,그 데이터와 가장
14.[ML] 앙상블(Ensemble) 기법
여러 개의 모델을 결합해서 더 좋은 성능을 내는 기법'알고리즘'이라기 보단 '카테고리'. '여러 알고리즘들 중에서 앙상블 기법을 쓰고 있는 것들'이라는 표현이 정확여러 다른 모델들의 예측 결과를 모아 투표해서 최종 결과를 결정하는 방법동일한 데이터 / 다른 모델모델 A
15.[ML] PCA (Principal Component Analysis, 주성분 분석)
고차원 데이터를 → 낮은 차원으로 축소하면서, 최대한 정보(분산)을 보존하려는 기법.한줄 요약하면, "데이터를 가장 잘 설명하는 방향으로 압축하는 기술."데이터 차원이 너무 높으면 ➔ 계산 복잡, 오버피팅 위험 커짐비슷한 정보끼리 묶어 ➔ 축소(압축) 시키기시각화(2D
16.[ML] PCA (Principal Component Analysis, 주성분 분석) (시각화 실습)
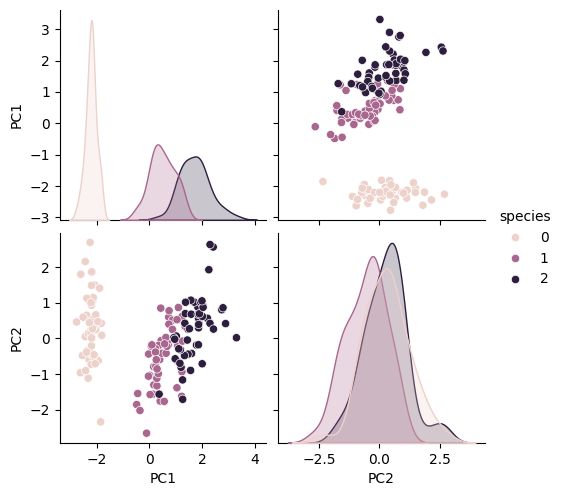
iris data로 PCA를 실습해보자!iris_pca와 iris_ss shape 비교:pca mean 속성과 components 속성 확인:pca 데이터로 데이터프레임 만들기:페어플롯:PC1과 PC2가 데이터셋을 각각 73%, 23% 정도를 설명한다.(이 글은 제로베
17.[ML] Clustering (군집화)
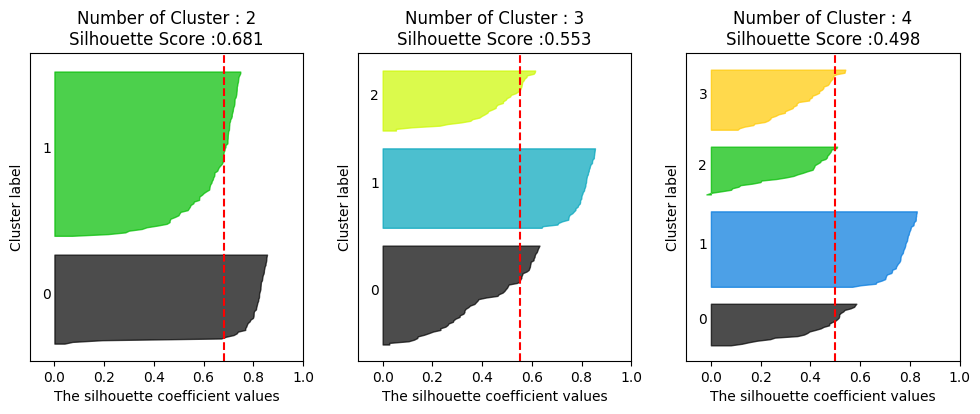
"비슷한 애들끼리 그룹 묶는 것"근데 레이블은 없음. 즉, 비지도 학습이다.→ "정답 없이, 데이터 자체를 분석해서 비슷한 것끼리 뭉쳐보자."는 것이 Clustering이다.비지도 학습 → 정답(y)이 없음패턴 탐색 → 비슷한 데이터끼리 그룹 찾기거리 기반 → 보통 거