Part 1. Introduction to Deep Neural Network
1) 심층 신경망의 기본 동작 과정
딥러닝
- 두뇌의 동작 과정을 모방하여 수학적인 인공지능 알고리즘으로 만든 것
머신러닝 (기계학습)
- 학습데이터로 기계 학습이라는 알고리즘에 줬을 때 기계학습 알고리즘이 예시 데이터에서 주어진 입력과 출력의 관계를 모방하여 새로운 입력이 주어졌을 때에 해당 task를 잘 수행할 수 있도록 하는 알고리즘
딥러닝
- 학습 데이터에 기반한 여러 기계학습 알고리즘 중 신경세포들이 망을 이루면서 정보를 교환하고 처리하는 과정을 모방하여 만듬
Artificial Neural Network
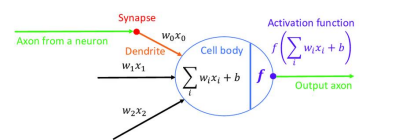
하나의 계층에 있는 뉴런들은 동일한 입력 정보를 받아 각기 나름의 정보를 처리
Deep Neural Network (심층 신경망)
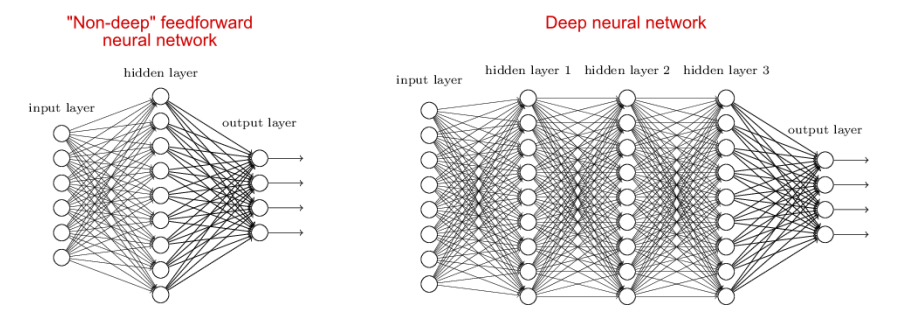
이러한 정보를 수백 단계, 계층으로 처리
perceptron
뉴런의 동작 과정을 알고리즘으로
입력 정보를 가중치와 곱해서 가중합을 만들어냄 -> 활성 함수를 거쳐 최종 출력 신호를 만들어줌
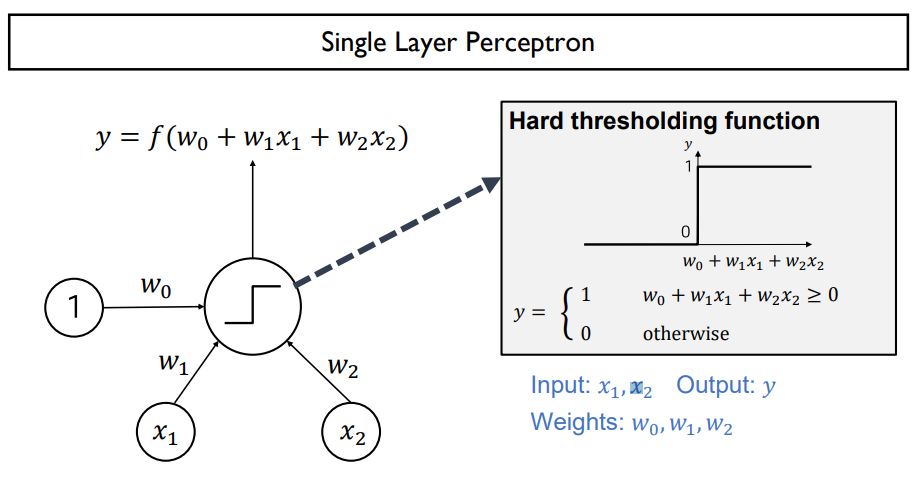
- 0보다 커지면 1, 0보다 작아지면 0을 최종 output으로 가질때 이 경계를 descision boundary라고 부름
- 좌표 공간을 input feature space라고도 부름
XOR
- 0,1 다른 값이 나올 때 1반환
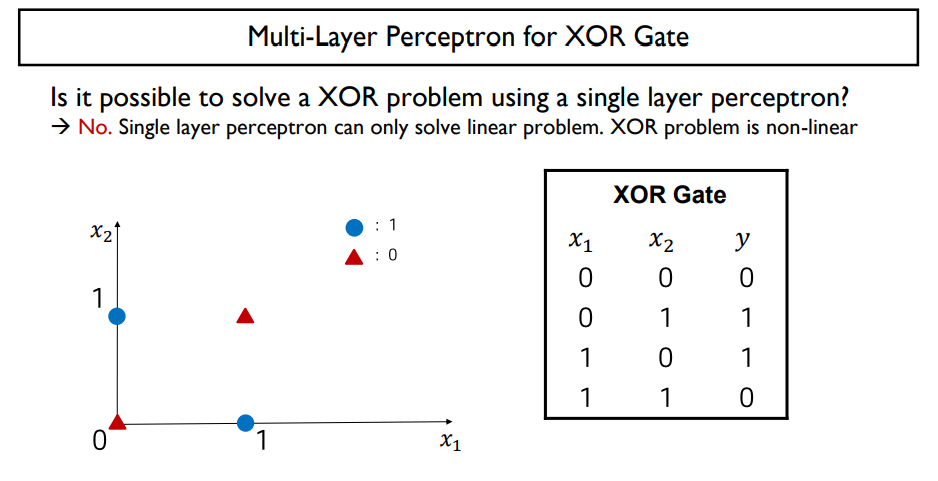
- XOR problem의 경우 Multi-layer perceptron으로 해결
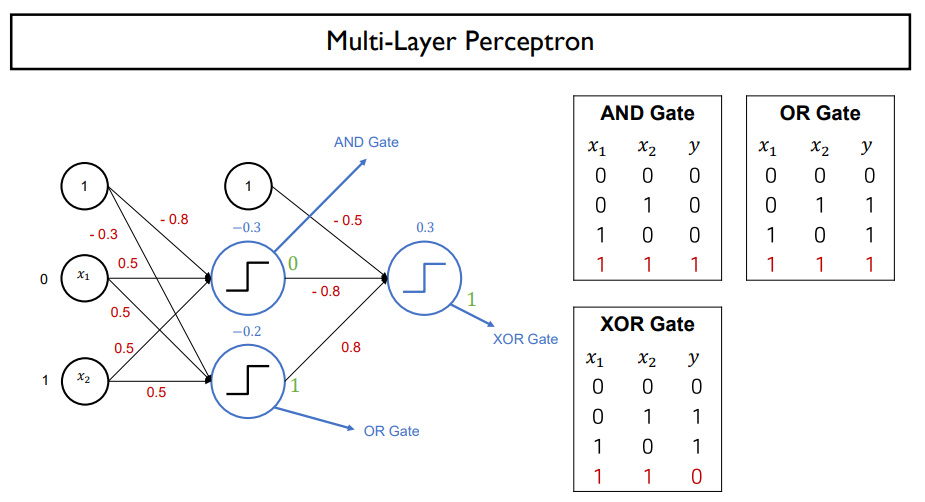
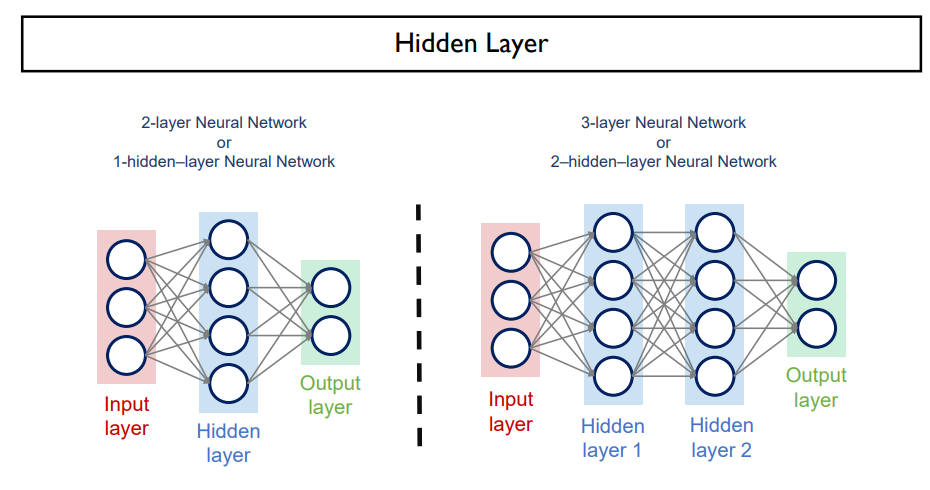
- 1-hidden layer neural network
Forward Propagation
-multi layer에서 계층 별로 계산 과정을 나타냄
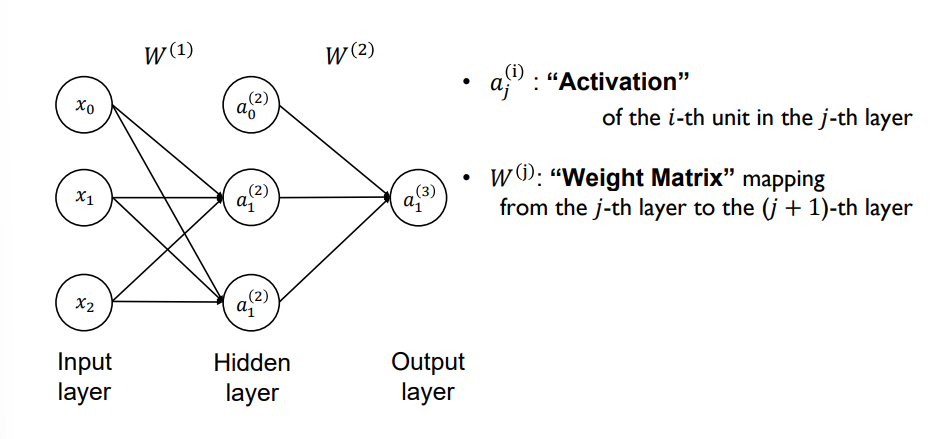
- 가중치를 행렬로
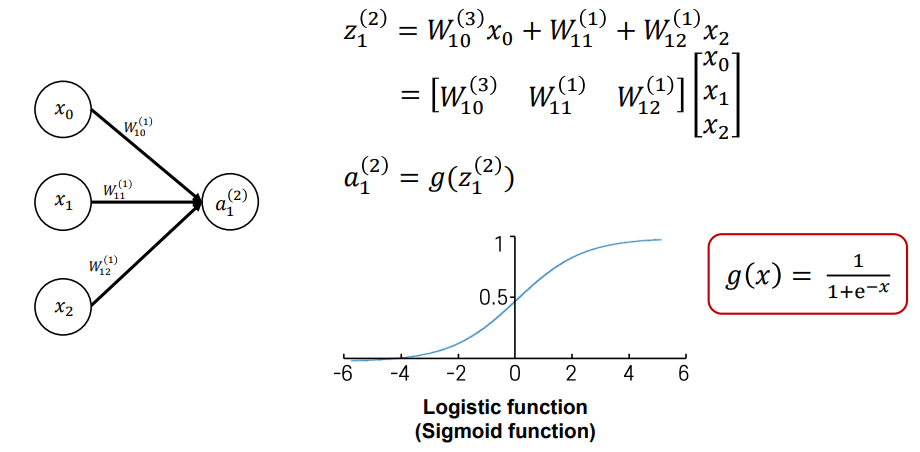
- 뉴런의 입력으로 주어지는 벡터를 column 벡터로 만들고, 가중치 행렬을 row vector로 가중합을 행렬의 내적 형태로 나타낼 수 있음
- 위 activation function은 sigmoid (logistic) function, 0에서 1사이 실수값을 output으로
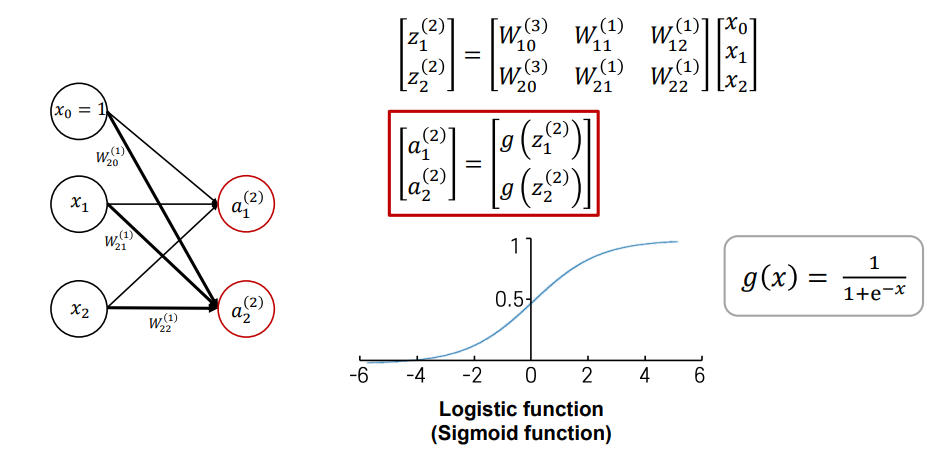
- output 노드가 여러 개인 경우 열 vector가 결과로 나오게 됨 -> 각각 sigmoid 통과
MNIST Classification
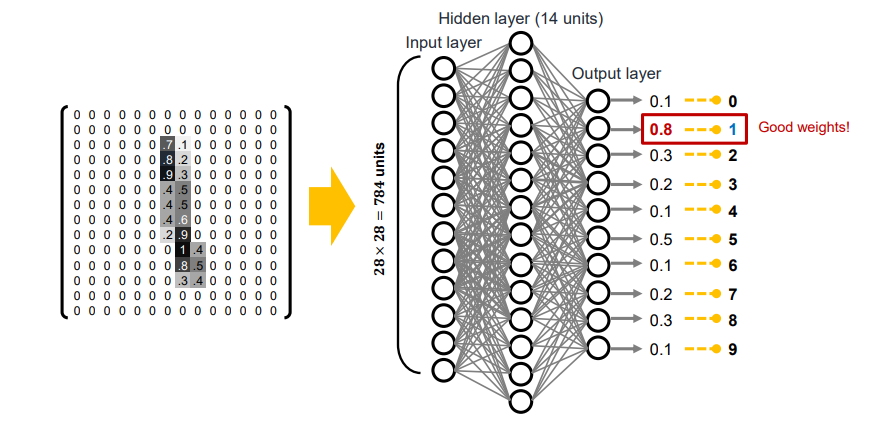
- 특정 digit으로 0-9까지 분류
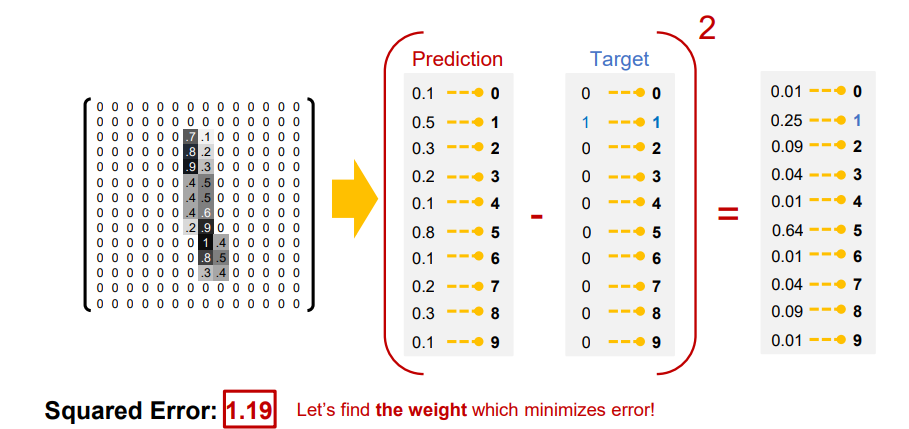
- ground truth 결과 바탕으로 loss fucntion을 만들 수 있음 -> 해당 예시에서 mean square error , 정답 제외 나머지 모두 0
- 문제점 -> loss가 최대 1이 될 수 있는데 학습에 사용되는 gradient 값이 적어 학습이 느려짐
- 확률값의 합이 1이 되는 것이 바람직
softmax layer, softmax classifier
- 전체 확률값의 합이 1
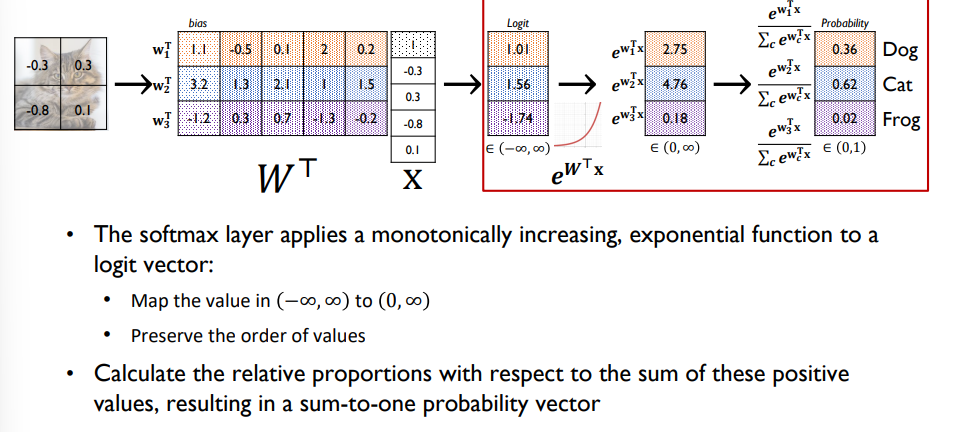
- softmax에 적용하는 loss function -> softmax loss 혹은 cross-entropy loss 를 사용 (정답을 최대한 1로 만듬)

- 확률값이 1에 가까울수록 무한대로 큰 loss를 부여
Logistic Regression - Softmax Classifier
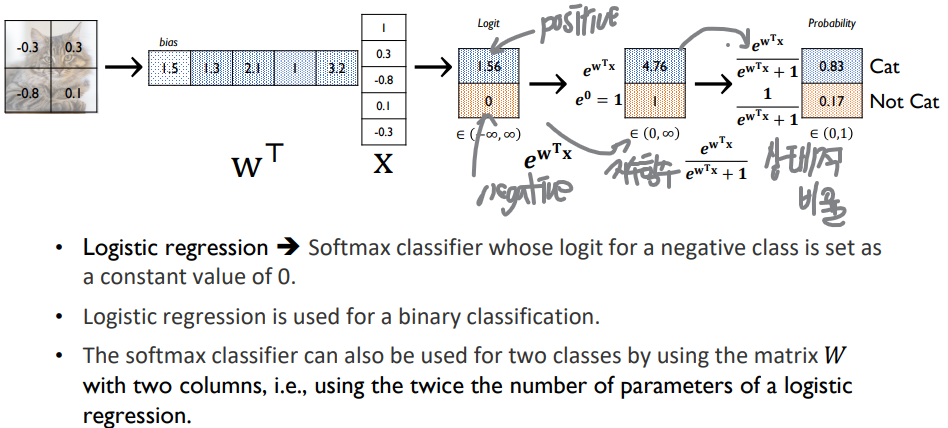
- output노드는 선형결합의 결과값으로 내어주게 됨
- negative는 가상, positive class에 해당하는 부분만 학습을 통해 최적화된 값으로 도출해냄
- Binary cross-entropy(BCE) loss - class가 두개인

Part 2. Training Neural Networks
neural network를 어떻게 학습하는가
-> gradient descent알고리즘을 통해, 최적화 파라미터, loss function을 최소화하는 파라미터를 찾음
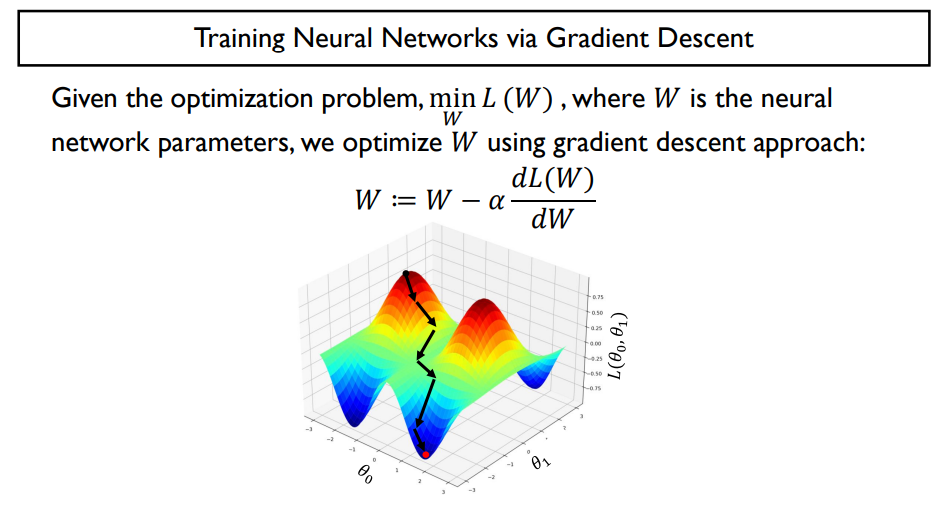
- loss function에 대해 각 파라미터들에 대한 미분값을 구함, 그 미분값을 사용해 현재 파라미터를 미분 방향의 - 방향으로 step size혹은 learning rate를 곱함
- random initialization에서부터 시작해서 함수 높이가 점점 낮아지는 방향으로
- loss function이 복잡해지는 경우 수렴 속도가 느려짐
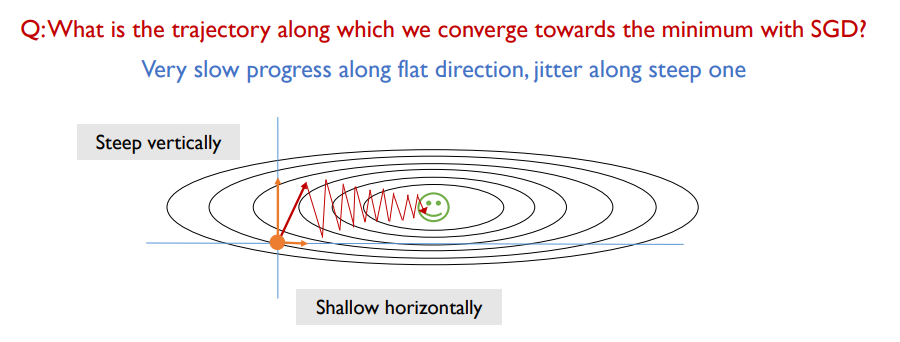
- 학습을 통해 최적화를 이루어내야하는 대상 변수들은 layer에서의 parameter w들
- random initialization에서 시작하여 forward propagation을 진행
- 결과에서 예측값과 ground truth (결과) 값과의 차이를 계산하고 차이를 최소화하는 방향으로 loss function을 정의
- loss function 에 대한 편미분 값을 backpropagation으로 구하여 파라미터를 업데이트
- 파라미터 업데이트, 최적화가 반복적으로 진행
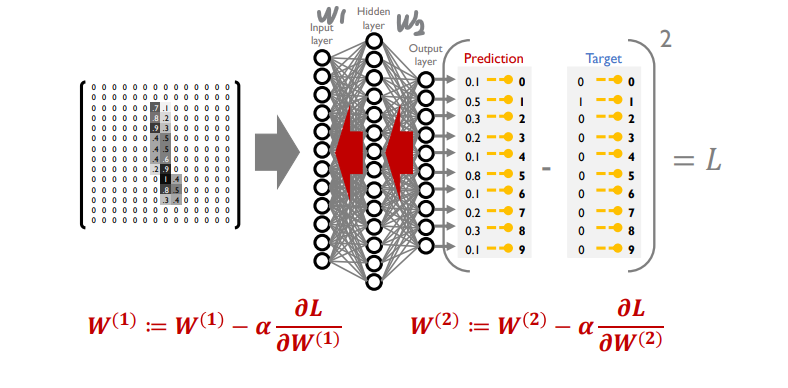
random initialization
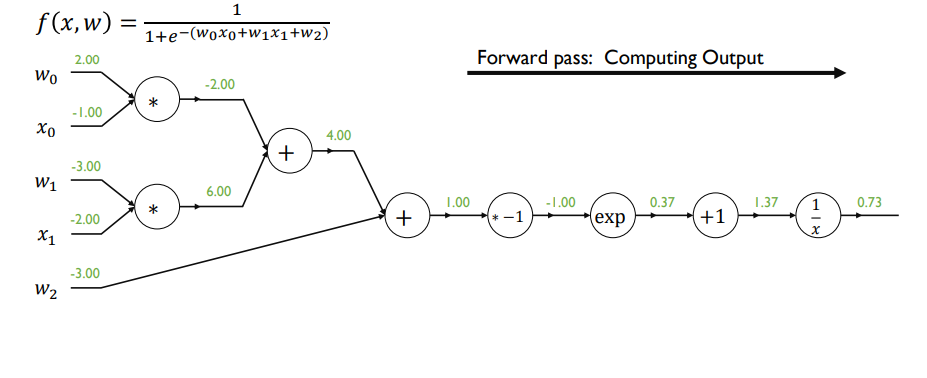
(보통은 binary cross entropy를 loss로 logistic regression을 학습)
- 해당 예시에선 sigmoid의 output이자 logistic regression의 최종 출력값이 loss function이라 가정
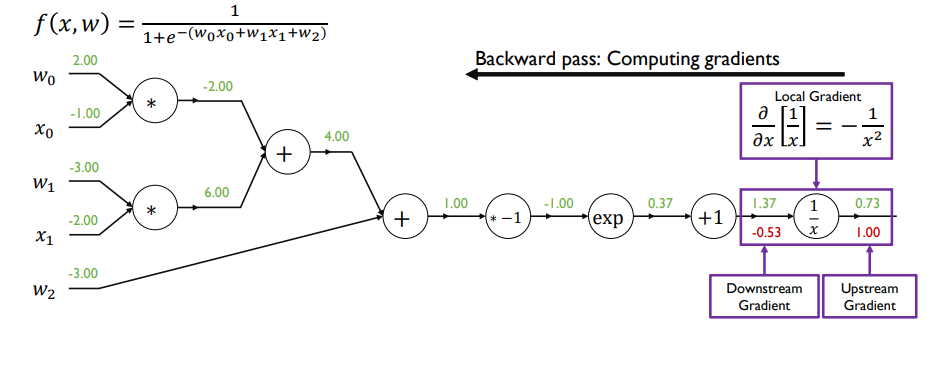
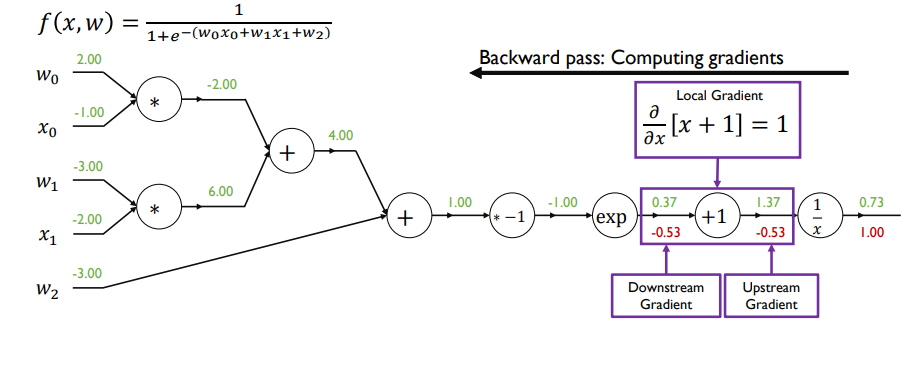
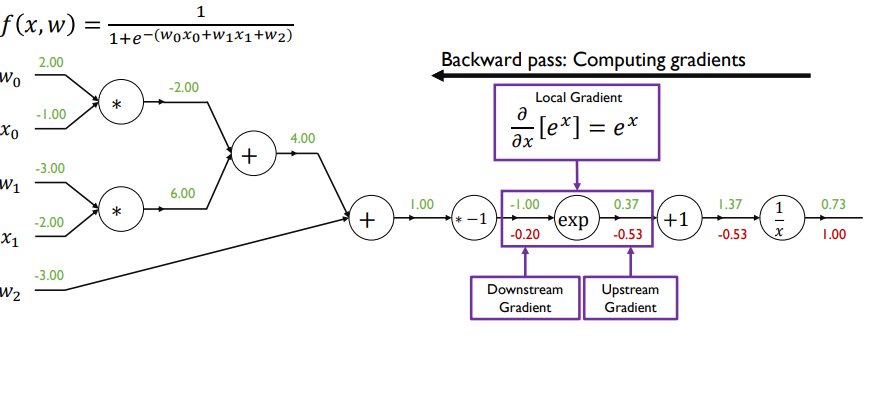
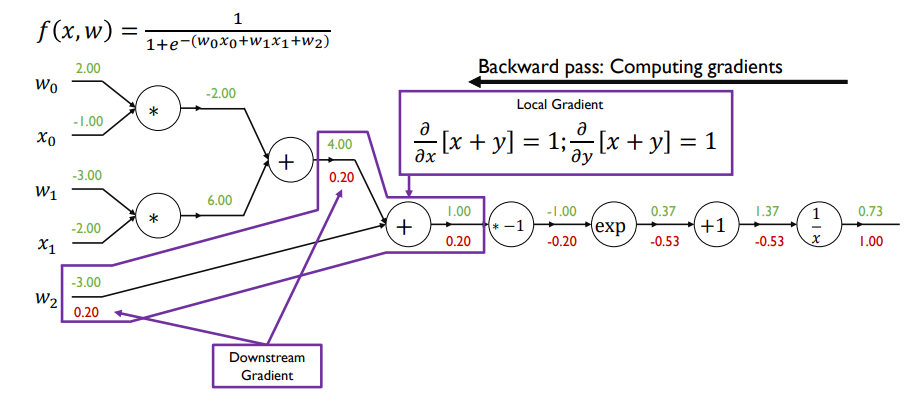
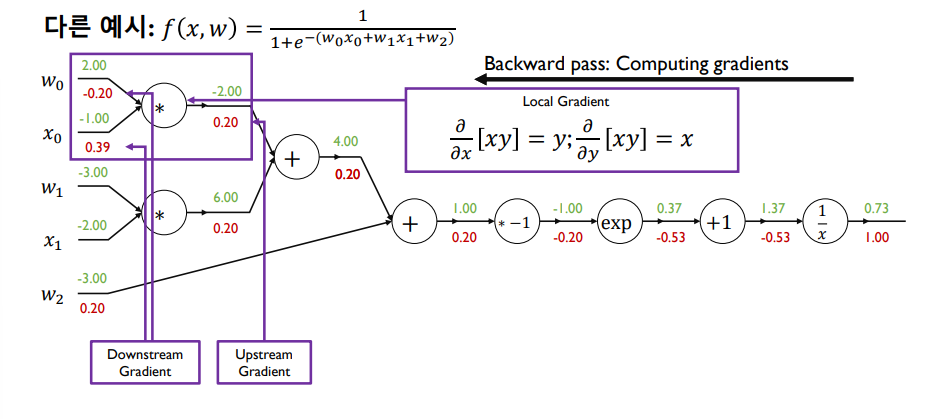
- 편미분 값을 전부 구한 뒤 실제 업데이트 해야하는 w0, w1, w2
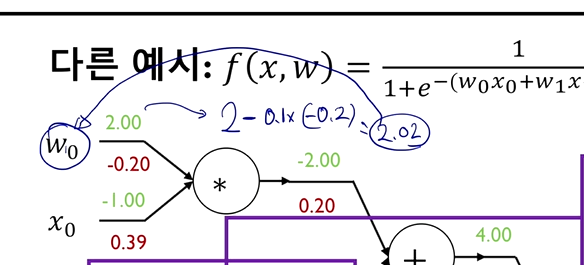
- 미분값과 learning rate를 곱한 값을 초기값에서 빼서 파라미터 업데이트
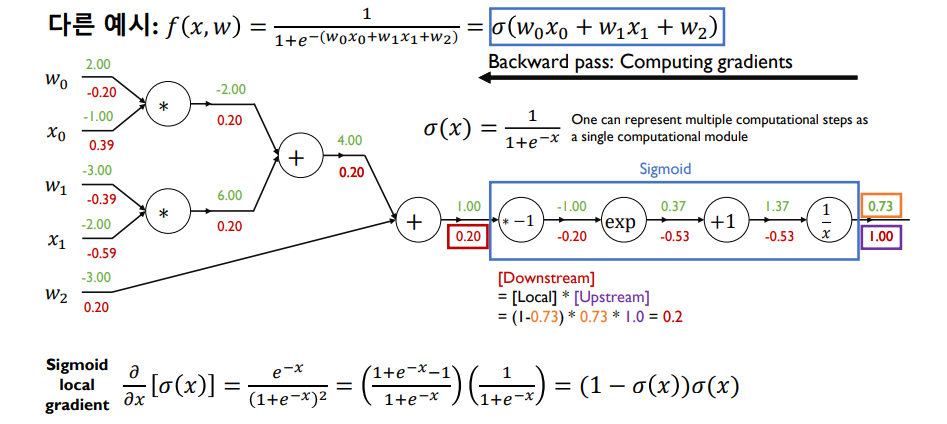
- sigmoid 함수 자체를 노드로 보고 한 번에 미분값 계산할 수 O
Sigmoid Activation
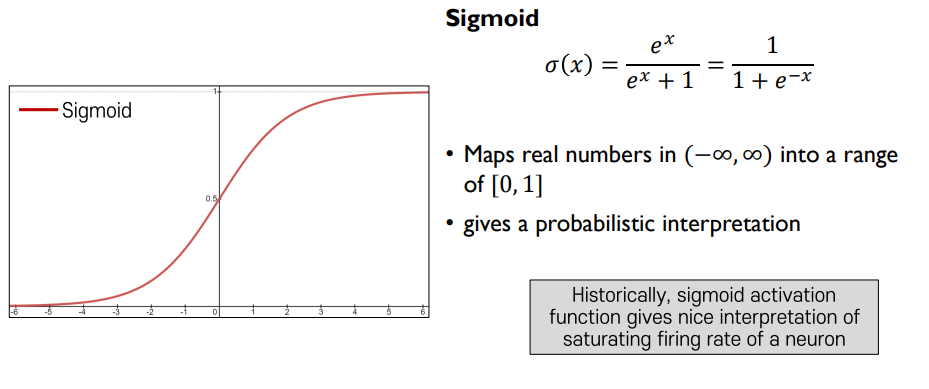
- hard threshold를 부드러운 형태로 근사화
- 주어진 선형결합의 결과가 마이너스 무한대부터 무한대까지 가질 수 있는 값들을 0에서 1사이 값들로 mapping
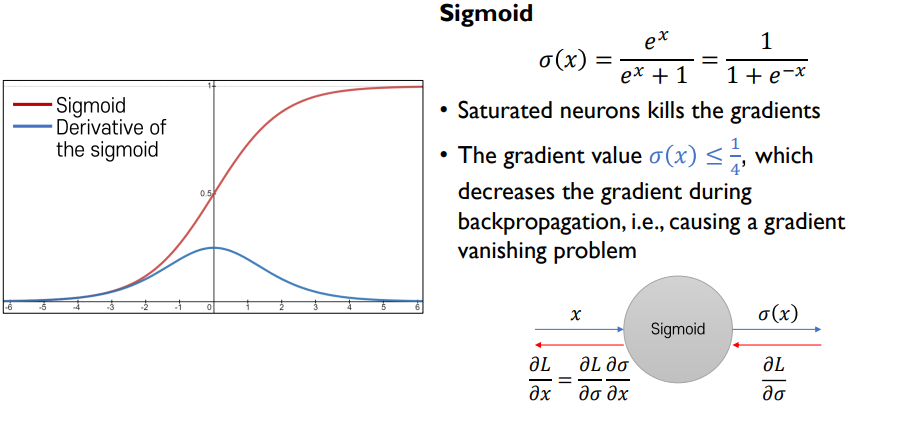
- 0에서 1/4 사이의 값을 곱해주게 됨, 1보다 많이 작은 값이라 backpropagation을 점차 진행할 수록 gradient값이 점점 0에 가까워짐 -> gradient vanishing -> Tanh Activation으로 해결
Tanh Activation
- sigmoid에 두 배를 곱함
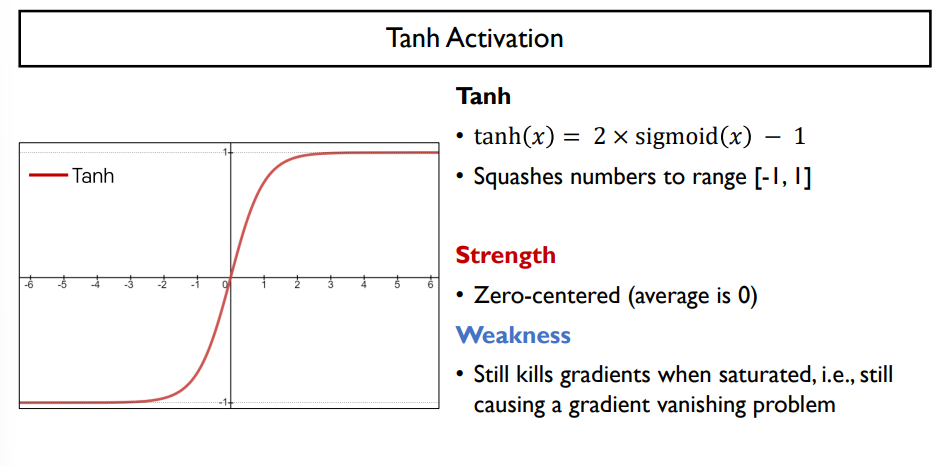
- -1사이부터 1사이의 값으로 mapping, 학습을 조금 더 빠르게 해주는 효과
- gradient값이 0에서 1/2사이 값으로만 되는
ReLU Activation
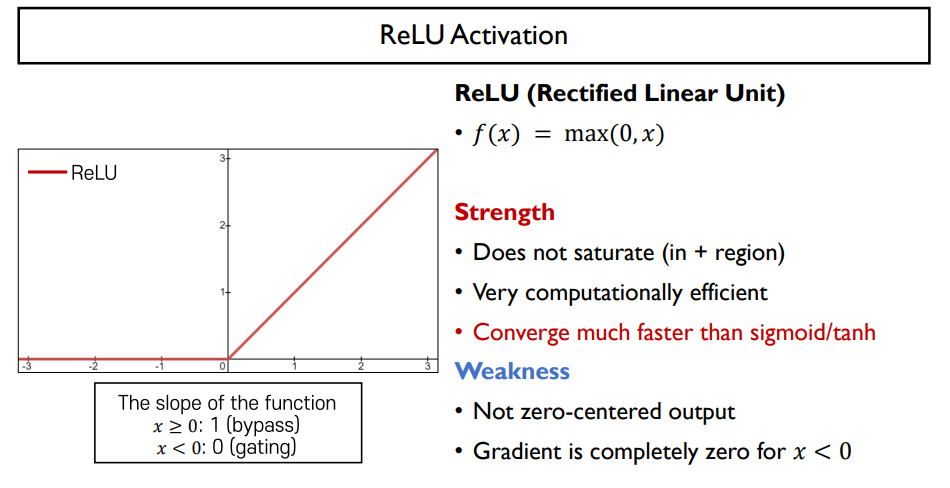
- gradient vanishing 문제를 해결해주는 대안으로 활용
- 선형결과의 값이 0보다 작으면 0으로 0보다 크면 결과값 그대로 상수값을 가지게 되는 것
- sigmoid/tanh보다 훨씬 빠르게 수렴
Batch Normalization
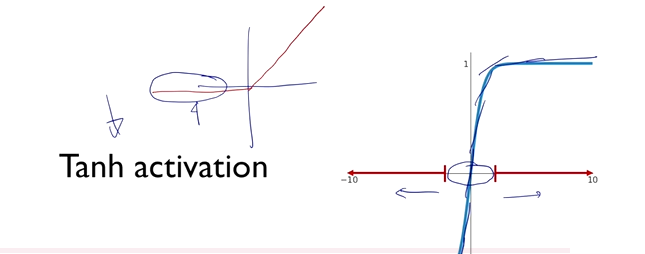
- 위 구역 외에 나머지 부분은 gradient가 작아 업데이트가 잘 이뤄지지 않는다는 단점, backpropagation 과정에서도 적절한 signal을 주지 못함
- batch normoalization의 아이디어 : 해당 범위로 값들을 제한할 수 있는 방법을 고안 (gradient vanishing을 해결)

- 평균 0, 분산 1로 정규호
- 입력으로 주어지는 값의 대략적인 범위를 0을 중심으로 하는 분포로 만듬
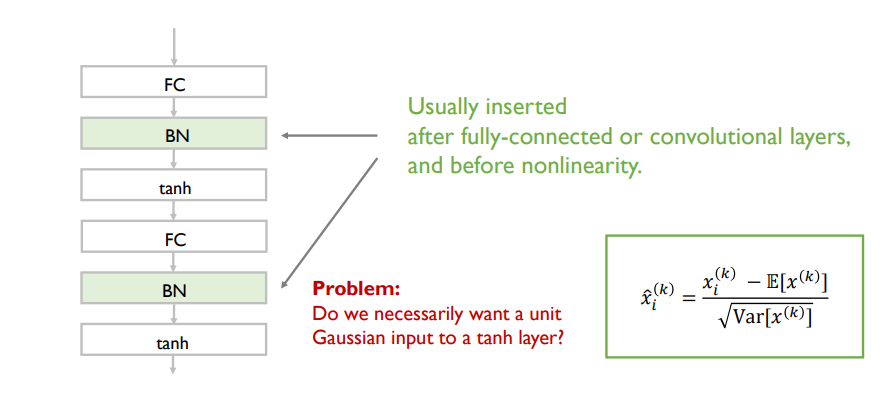
- 고유한 평균과 분산 자체도 neural network가 학습해야 하는 중요한 정보를 담고 있다면 문제가 발생 -> 이 잃어버린 정보를 복원하는 단계도 존재
두번째 변환
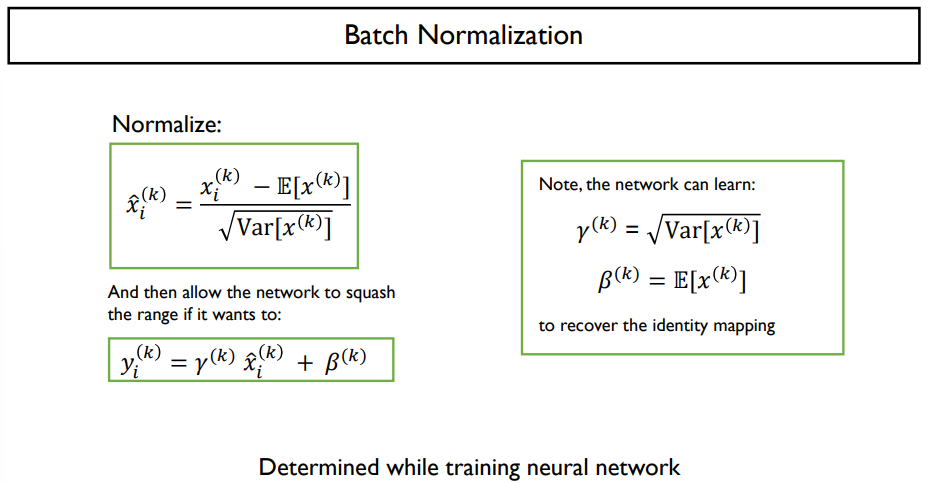
- gd 학습을 통해 최적화하게 되는 파라미터를 도입하여 y=ax+b라는 변환을 수행하는 추가적인 레이어를 삽입
- 분산은 a제곱, 평균은 b로 되어 최적의 평균, 분산값을 구할 수 있게 됨

Part 3. Convolutional Neural Networks and Image Classification
-
computer vision에서는 CNN이 default로 사용될 정도

-
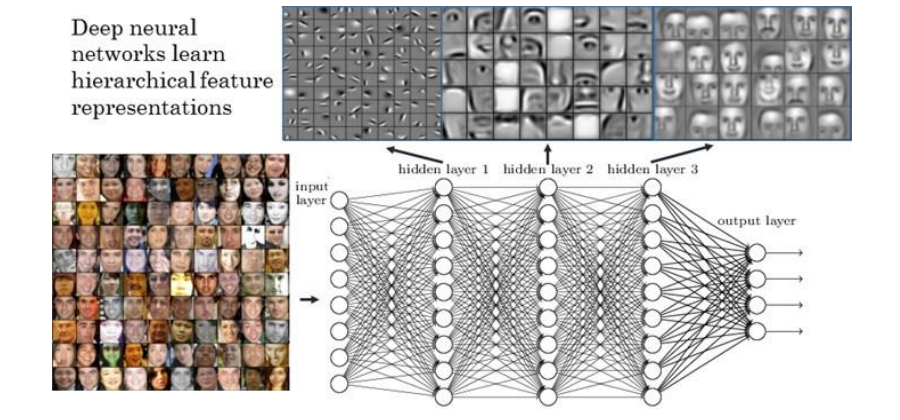
ConvNet은 요소 패턴을 잘 인식, 일관되게 나타내는 부분들의 특징을 bottom up 방식으로 잘 검출
-
작은 특정 패턴을 파악하고 패턴들이 주어진 이미지 상에 있는지를 판단
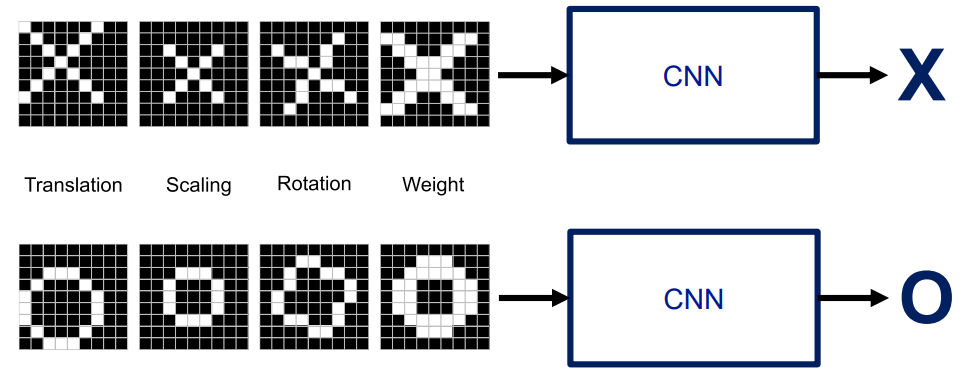

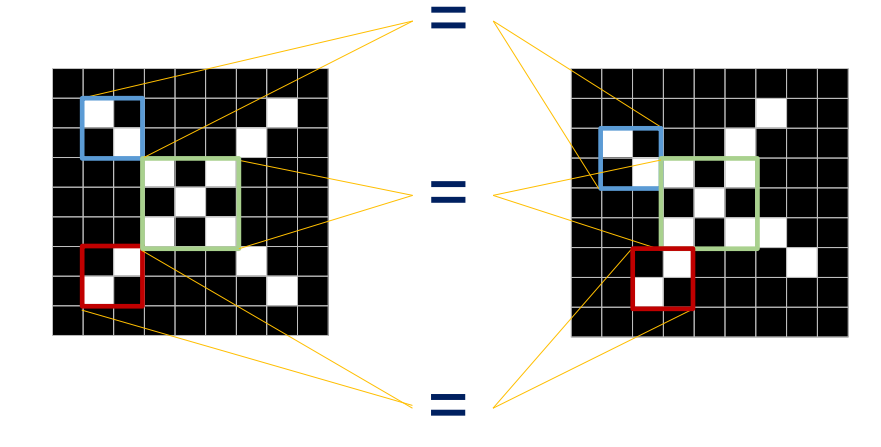
-
패턴들이 매칭되는 특정한 위치가 있음
-
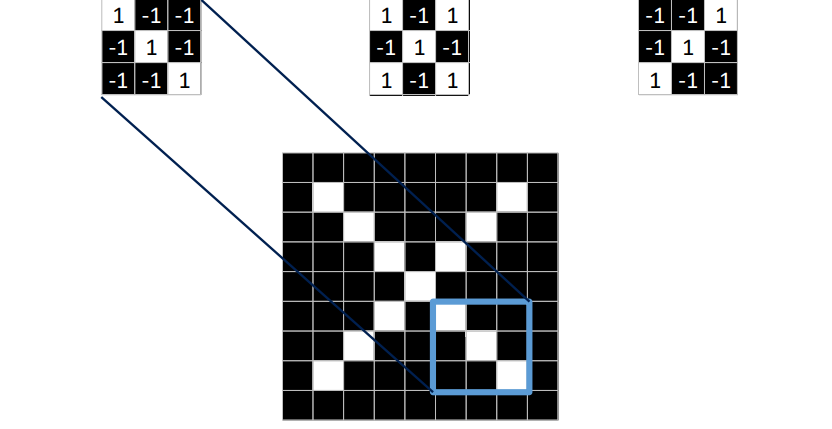
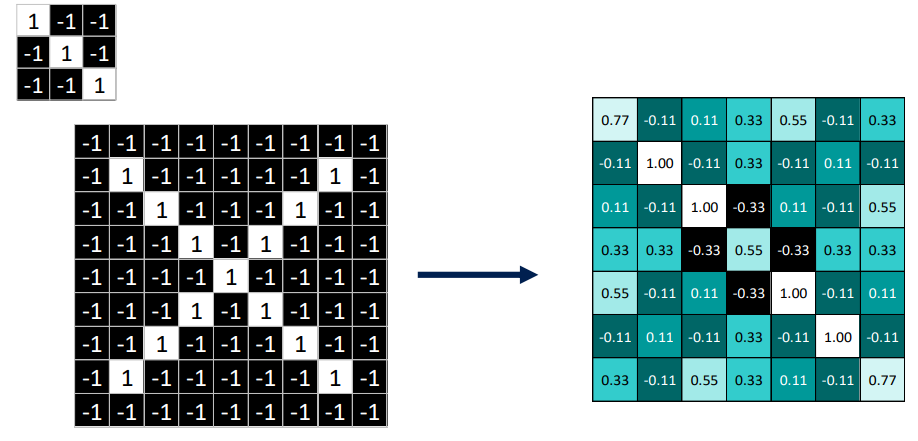
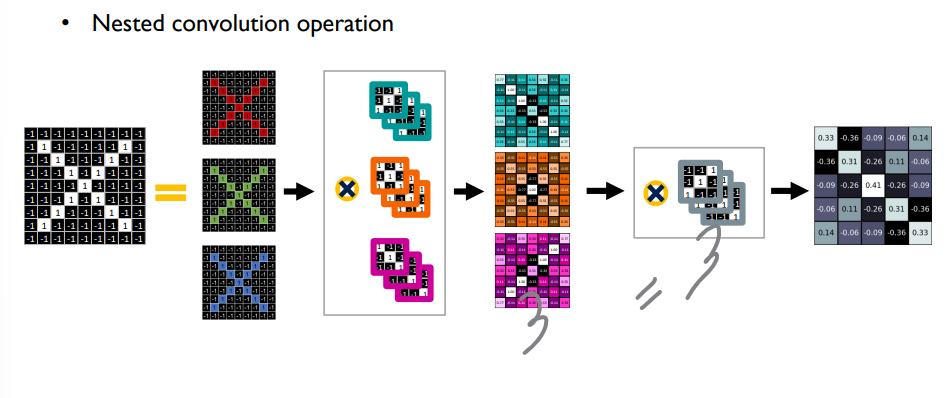
3x3패치를 주어진 이미지에 오버랩, 같은 위치의 값들을 곱함 , 두 픽셀이 같으면 1을 output으로
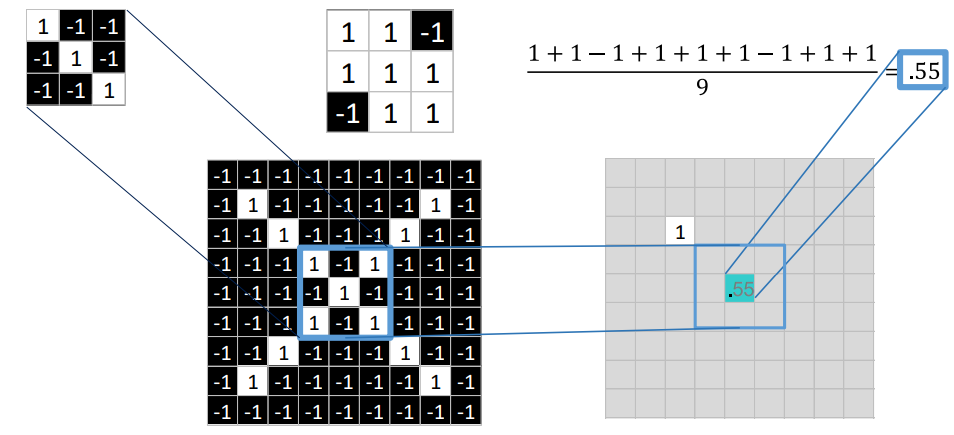
-
파란색 패치(convoluation filter)에서 55프로 매칭 확률을 얻을 수 있음
-
패치를 가능한 모든 위치에 위치시켜가며 행렬을 채움
-
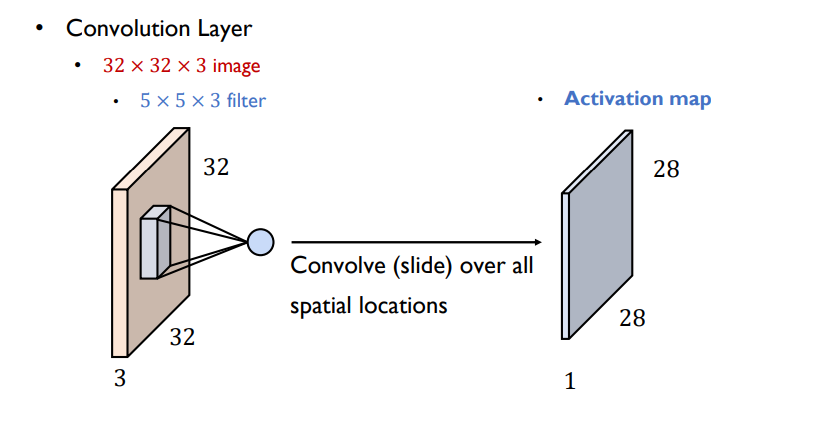
이를 통해 얻어낸 결과를 activation map, 활성화 지도라고 부름
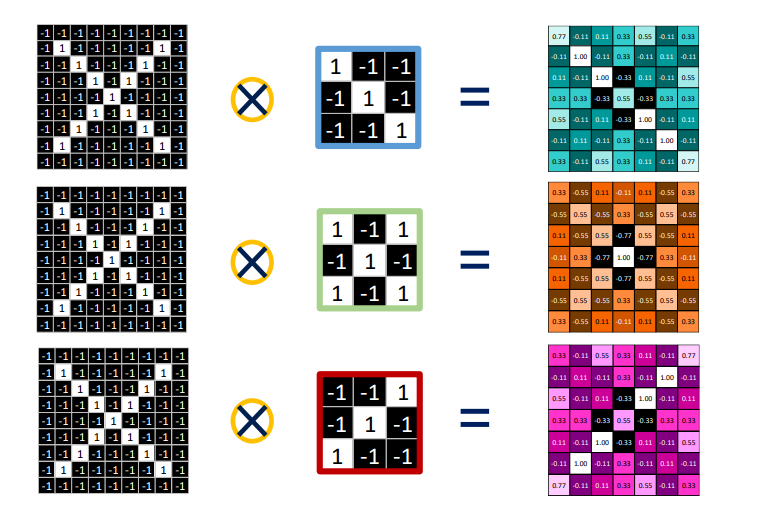
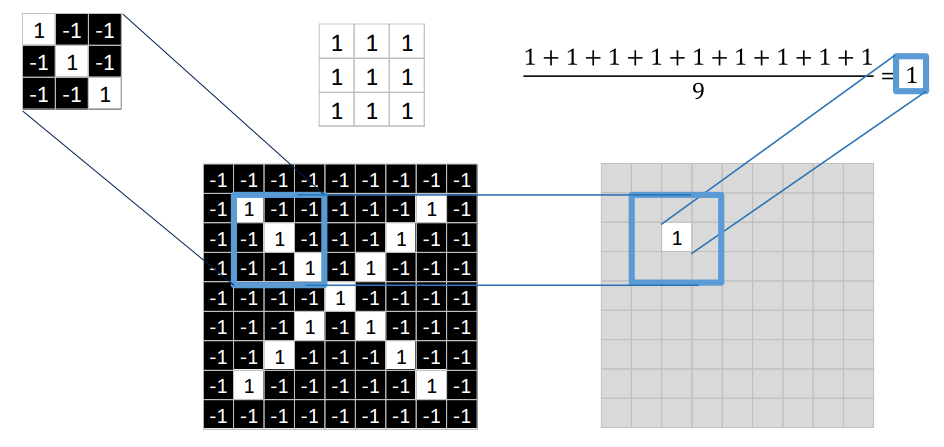
- Overlap the convolution filter and the image patch.
- Multiply each image pixel by the corresponding filter coefficient.
- Add them up.
- Divide by the total number of pixels (픽셀 수로 나눔) in the feature. (optional)
- 고유한 패턴을 가진 filter혹은 패치를 주어진 입력 이미지에 적용, 필터별로 activation map이 output으로
- filter개수 만큼의 이미지가 생성됨
- 입력 이미지는 채널(=depth)
입력이 여러 장인 경우 ( 채널과 activation map의 수와는 관련X)
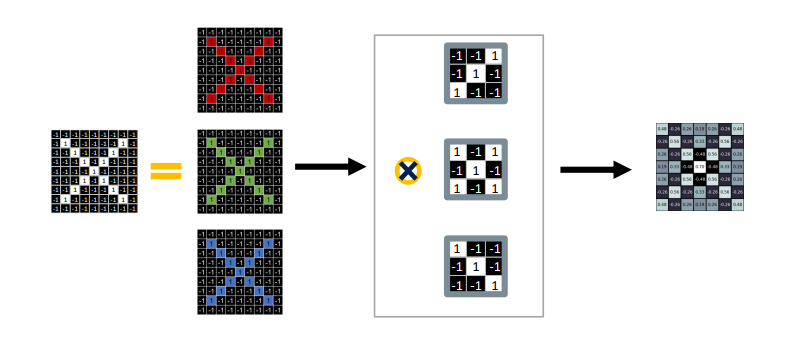
Convolution layer
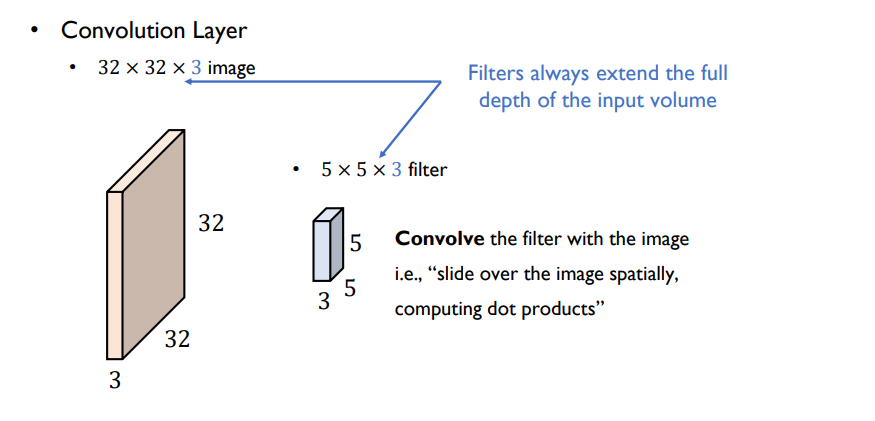
- 입력의 개수와 convolution layer의 개수는 같아야함
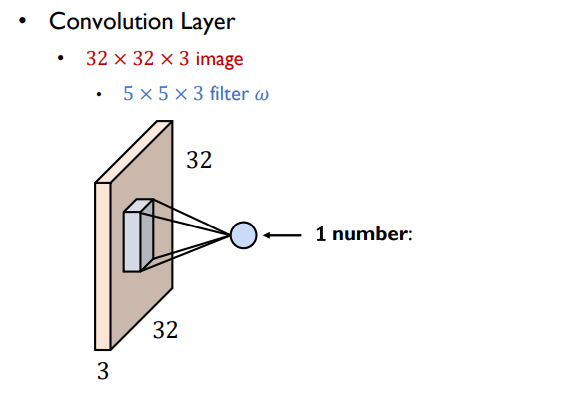
- 한 위치에서 하나의 scalar값
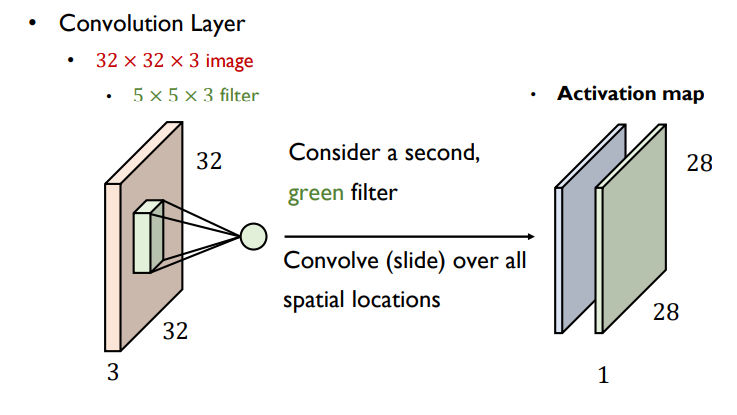
- output으로 나온 입력 채널과 필터의 수가 같아야함
Pooling
-
가로 세로 사이즈를 절반으로 줄여주는 효과 , 일종의 요약 과정 , 패턴이 이러한 세기로 나타났다
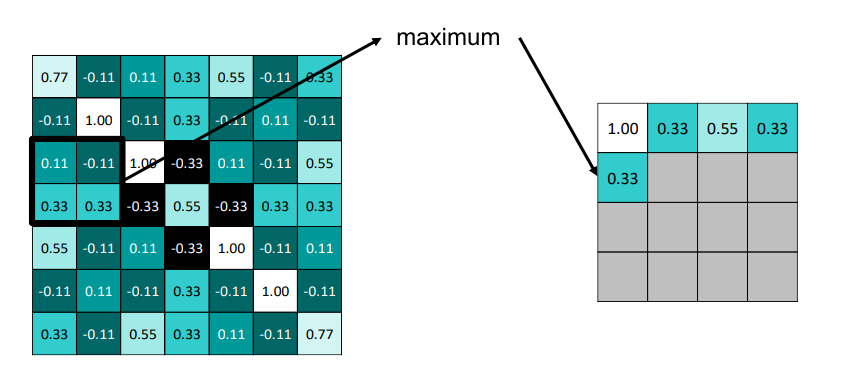
-
matching의 정도 (패턴의 일치 정도) 가 가장 크게 나타난 것을 채택하는 방식이 max pooling

-
pooling은 입력 이미지의 채널 별로 진행
-
선형 연산 이후 sigmoid , tanh , ReLU 등의 활성함수를 통과시켜줌으로써 함수를 보다 유연하게 다양한 패턴을 표현하게끔 만들어줌
-
convolution 연산 이후에도 ReLU를 적용해 주게 됨 -> 양수는 그대로 음수는 0으로

-
convolution ReLU를 stacking한 뒤 이미지를 축약, 요약하는 pooling진행

Fully connected layer
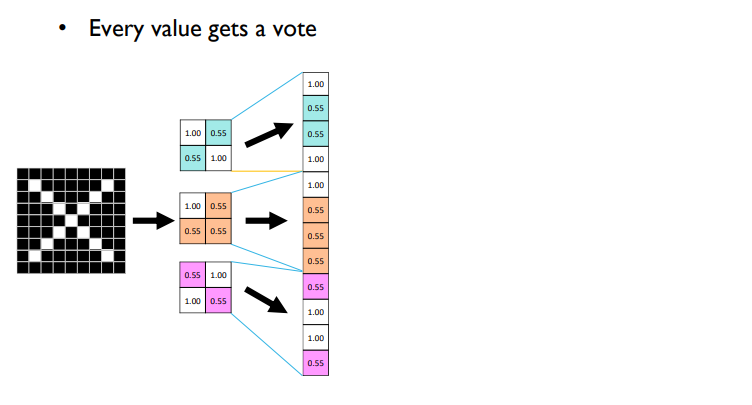
- 2x2를 한 줄의 vetor로 피게 됨
- 2의 제곱X입력 채널 수 만큼의 dimension을 가지는 한 줄 짜리 vector를 얻음
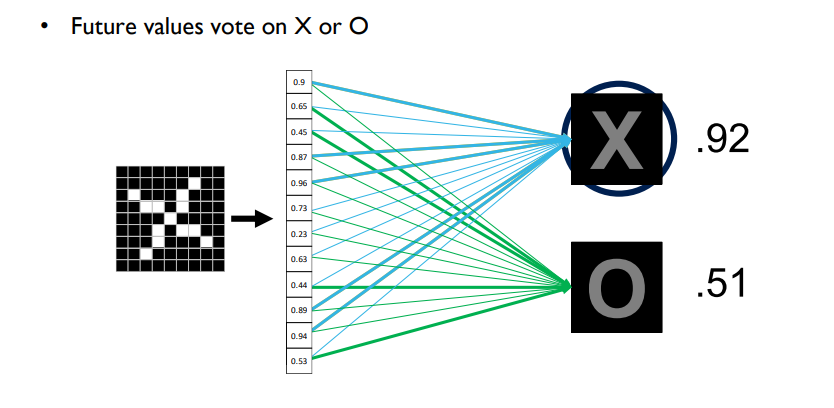
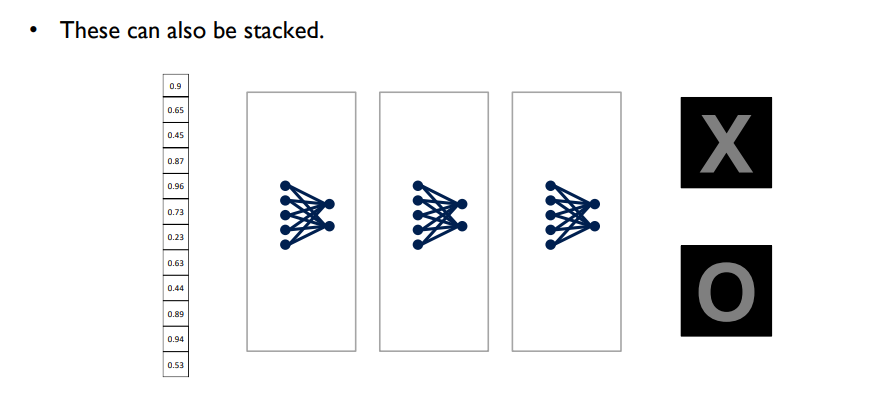
- fully connected layer도 여러 개 배치할 수 O
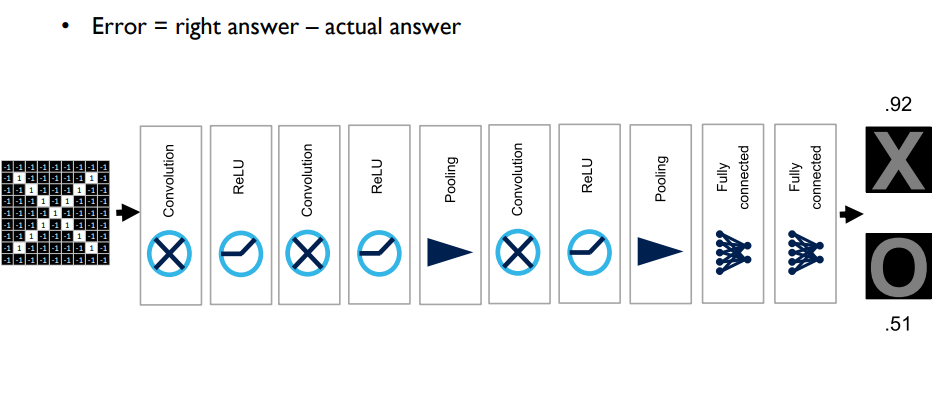
- 위와 같이 network를 구성할 수 있게 됨
- relu와 pooling에는 별다른 trainable한 파라미터 없음
- convolution layre에서는 각 이미지 특정 위치에 있는 convolution filter의 coefficient 혹은 filter 패턴 자체가 해당 필터의 가중치가 됨 ->gradient 계산
Hyperparameter

CNN architecture
- AlexNet
- VGGNet
- GoogleNet
- ResNet
VGGNet

- convolution layer의 filter size (패턴을 정의하는)를 무조건 3X3으로 진행하여 레이어를 깊이 쌓음
Resiual Network
ResNet
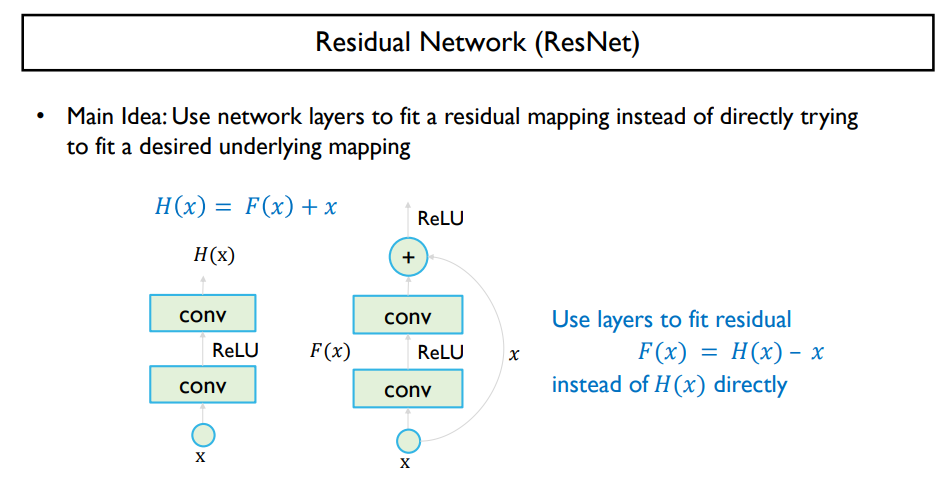
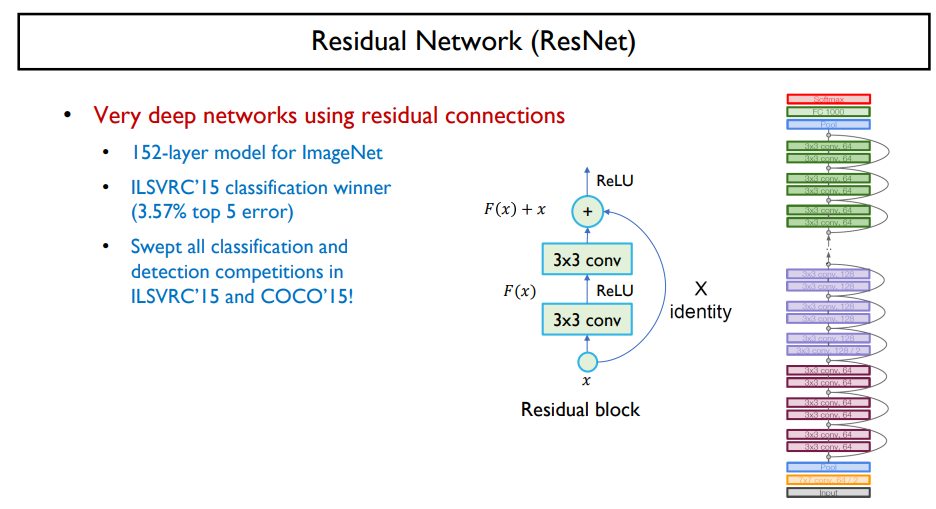
- 학습 레이어가 깊어지도록 유용하게 학습할 수 있는 네트워크
- 레이어를 필요할 땐 건너 뛸 수 있도록 skip connection
- 출력은 입력 대비 얼만큼 더해 줄지 빼줄지 차이 값만을 추가적인 레이어에서 만들어주면 됨
