
Sharding
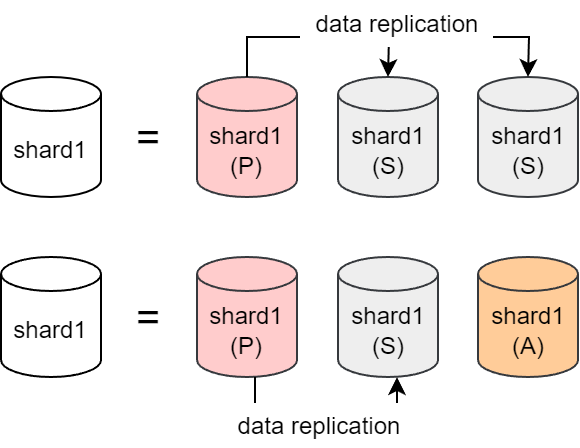
MongoDB는 확장성과 성능 향상을 위해 Sharding을 사용한다. Sharding은 데이터베이스를 물리적으로 분할한 것을 의미하며, Shard는 물리적인 노드를 의미한다. 하지만 Shard 1개가 물리적인 노드 1개를 의미하는 것은 아니다. MongoDB는 가용성을 높이기 위해 Shard를 동일한 데이터를 가진 Replica Set으로 구성해둔다. Replica Set에는 총 3가지 타입의 노드가 있다:
- Primary: 사용자의 read, write를 처리하는 노드이다.
- Secondary: Primary에서 write가 발생하면 Secondary로 데이터가 복제된다. Primary에 장애가 발생하는 경우 Secondary는 Primary로 선출될 수 있다.
- Arbiter: 데이터를 가지지 않고, 투표권만 가지는 노드이다. Primary에 장애가 발생하는 경우 어떤 Secondary를 Primary로 선출할지 투표한다.
💡Replica Set은 PSS (Primary, Secondary, Secondary) 또는 PSA (Primary, Secondary, Arbiter)로 구성할 수 있다. 즉, Shard 1개는 최소 3개의 노드로 구성된다.
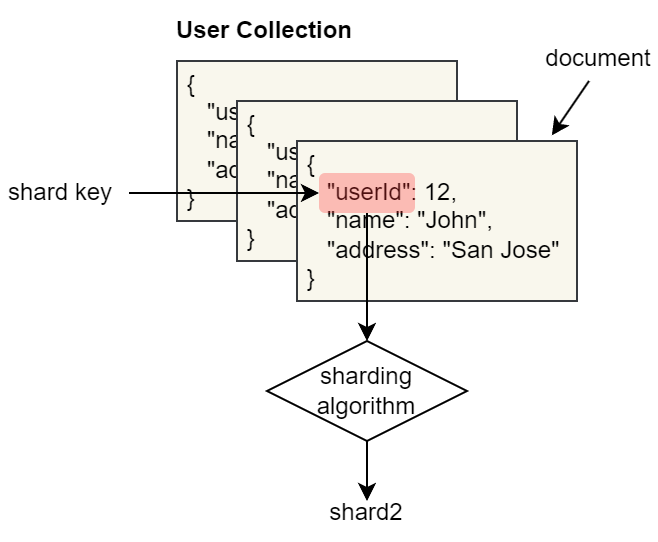
데이터를 어떻게 Shard에 배치시킬까
총 3개의 shard로 구성된 MongoDB를 사용하고 있고, 사용자 정보를 담은 User Collection이 있다고 가정하자. 애플리케이션에서 {"userId": 12}에 대해 쓰기 요청을 하면 MongoDB는 어떤 shard에 데이터를 배치시킬까?
모든 document에 존재하는 field의 경우 shard key로 지정할 수 있고, shard key를 기준으로 sharding algorithm을 사용하여 데이터를 분산시켜 저장한다.
💡 만약 shard key를 지정하지 않는다면
_idfield가 자동으로 shard key로 지정된다.
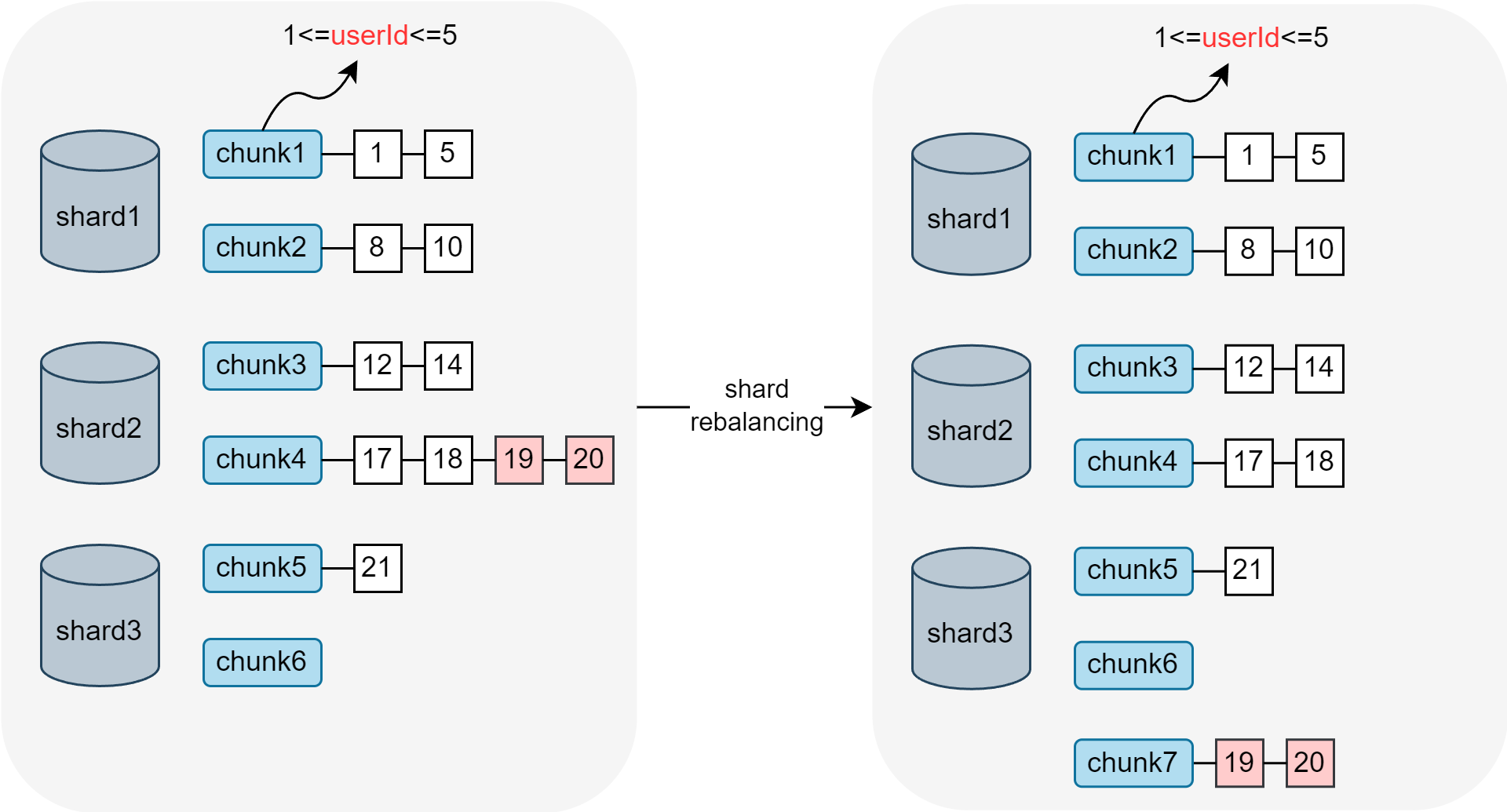
MongoDB는 sharding algorithm을 통해 데이터를 shard에 분산시키지만, shard 내에서 chunk로 한번 더 데이터의 위치를 분산시킨다. chunk 내에서도 데이터가 균등하게 분산되어야 좋은 성능을 낼 수 있기 때문에, chunk가 과도하게 커지면 split하여 다른 shard로 migration시키는 shard balancing을 수행하게 된다.
💡 chunk4는 userId 16~20에 대한 데이터를 가지고 있는데, shard rebalancing을 통해 userId 19~20을 chunk7로 split하여 shard3으로 migration시킬 수 있다.
데이터의 Shard 정보는 어디에 있을까
애플리케이션에서 {"userId": 12} 데이터를 읽기 위해 모든 shard에 쿼리를 보내서 해당 데이터가 있는지 확인한다면 굉장히 비효율적일 것이다. Config Server는 데이터의 shard 및 chunk 정보를 가지고 있다.
따라서 router 계층인 Mongos가 애플리케이션의 쿼리를 전달받으면 Config Server에 질의해서 shard 정보를 얻어온 후 요청을 해당 shard의 primary 노드로 전달하게 된다.
💡 shard key가 아닌 field로 요청하면 모든 shard에 쿼리가 전달된다.
정리해보자
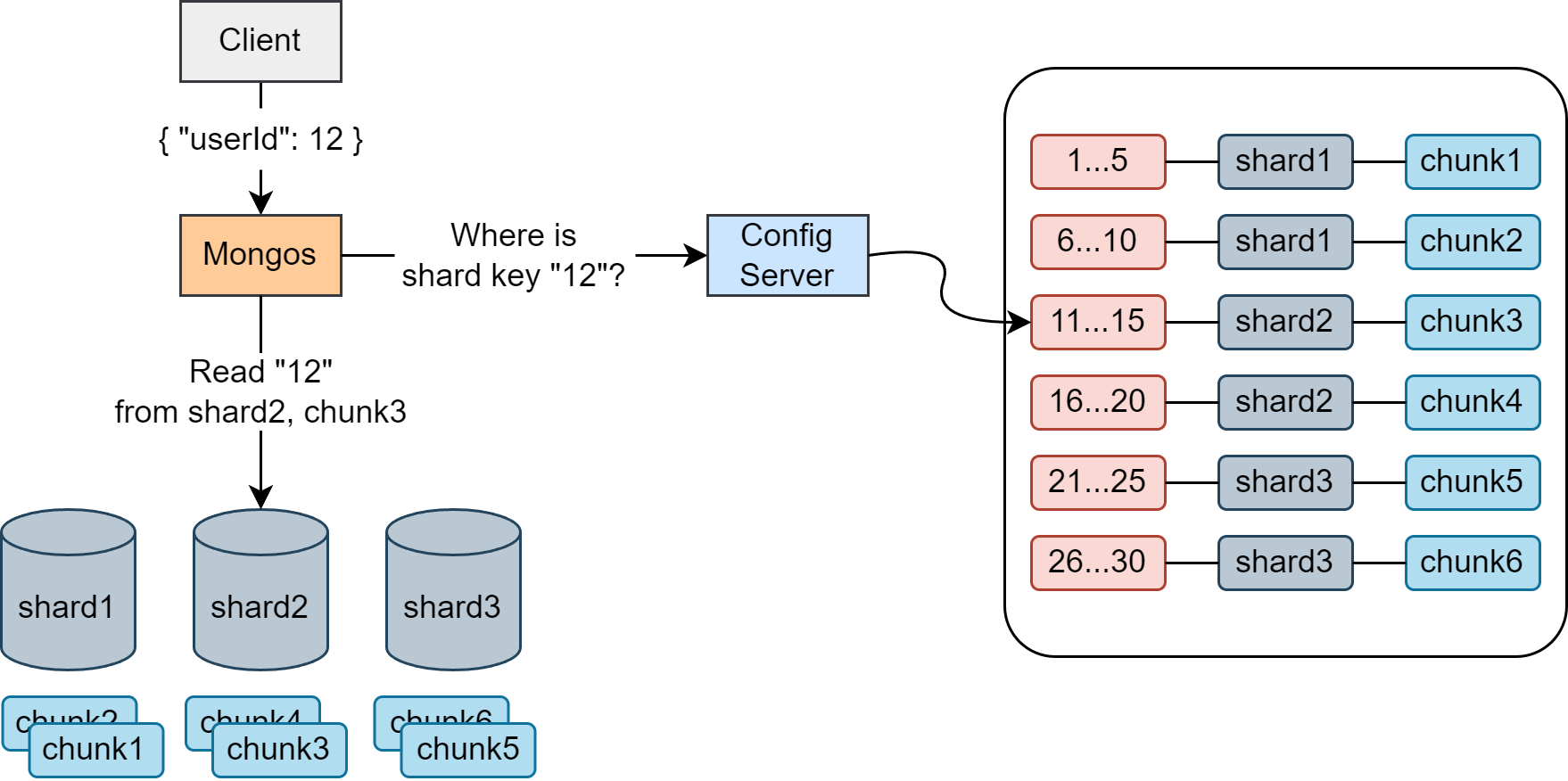
- Client는 Mongos에
{"userId": 12}read 쿼리를 전송한다. - Mongos는 Config Server에 질의해서 해당 데이터가 어떤 shard와 chunk에 위치하는지 확인한다
- Mongos는 shard2의 primary 노드로 쿼리를 전송한다
- shard2의 primary 노드는 쿼리를 실행하고 결과를 Mongos로 리턴한다
- Mongos는 결과를 Client에게 리턴한다
참고자료
