Object Detection
Object Detection(객체 탐지)는 디지털 이미지나 비디오에서 객체의 위치(Localization)와 범주(Classification)를 동시에 식별하는 컴퓨터 비전 기술이다.
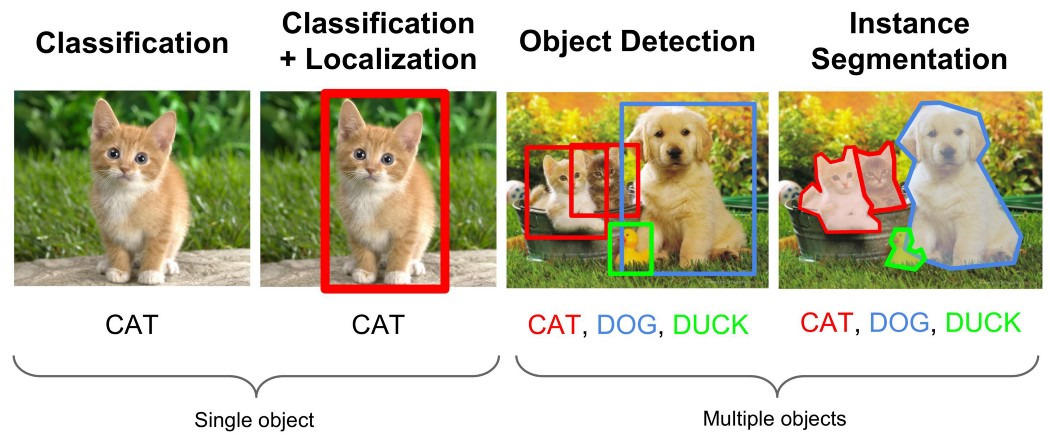
객체 탐지는 이미지 분류보다 한 단계 복잡한 작업이다. 이미지 분류는 전체 이미지에 하나의 라벨만 할당하지만, 객체 탐지는 한 장의 이미지 안에서 여러 개의 객체를 찾아내고 각 객체의 위치와 종류를 예측한다. 이 기술은 자율 주행, 의료 영상 분석, 보안 감시, 로봇 비전 등 다양한 분야에서 핵심 역할을 한다.
핵심 아이디어
객체 탐지는 크게 분류(Classification)와 회귀(Regression)를 결합한 문제로 볼 수 있다.
- 분류(Classification) : 해당 객체가 어떤 클래스에 속하는지 판별
- 회귀(Regression) : 객체의 위치를 경계 상자(Bounding Box) 좌표로 예측
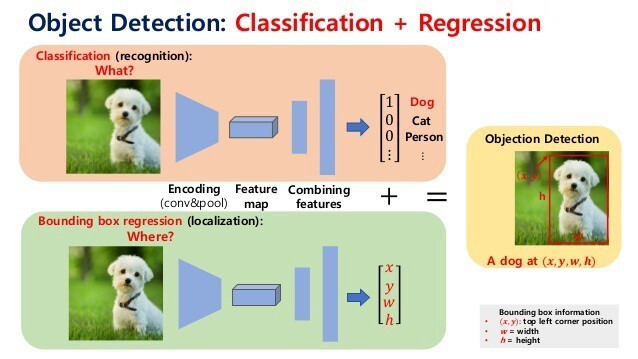
즉, 객체 탐지(Object Detection)는 한 장의 이미지에서 무엇이 있는지와 어디에 있는지를 동시에 알아내는 작업이다.
첫 번째 과정은 분류(Classification)이다. 입력 이미지가 주어지면 Convolution과 Pooling 같은 연산을 통해 이미지의 특징을 추출한다. 이렇게 얻은 특징 맵(Feature Map)은 신경망의 뒷부분을 거쳐 각 클래스에 대한 확률로 변환된다. 예를 들어, 강아지 사진이 입력되면 모델은 "Dog" 클래스의 확률을 높게 출력해 이 객체가 강아지임을 판단한다. 이 단께는 이미지 속 객체의 정체(What)를 밝히는 과정이다.
두 번째 과정은 경계 상자 회귀(Bounding Box Regression)이다. 여기서도 동일한 특징 추출 과정을 거치지만, 이번에는 객체의 위치를 나타내는 네 개의 숫자 를 예측한다. 와 는 경계 상자의 좌측 상단 좌표, 와 는 경계 상자의 너비와 높이를 뜻한다. 즉, 이 단계에서는 이미지 속 객체가 어디에 있는지(Where)를 수치로 알려준다.
마지막으로, 이 두 가지 결과를 결합하면 "이 이미지는 강아지이고, 해당 강아지는 (x,y) 좌표에서 시작해 w,h 크기의 상자 안에 있다."라는 형태로 표현할 수 있다. 이렇게 분류와 회귀가 결합되어야 비로소 객체의 종류와 위치를 함께 제공하는 객체 탐지 결과가 완성된다.
Pipeline
객체 탐지(Object Detection)의 전형적인 딥러닝 파이프라인은 크게 입력 특징 추출 객체 위치분류 예측 결과 출력의 흐름으로 구성되며, 구현 방식에 따라 Two-Stage 방식과 One-Stage 방식으로 나눌 수 있다.
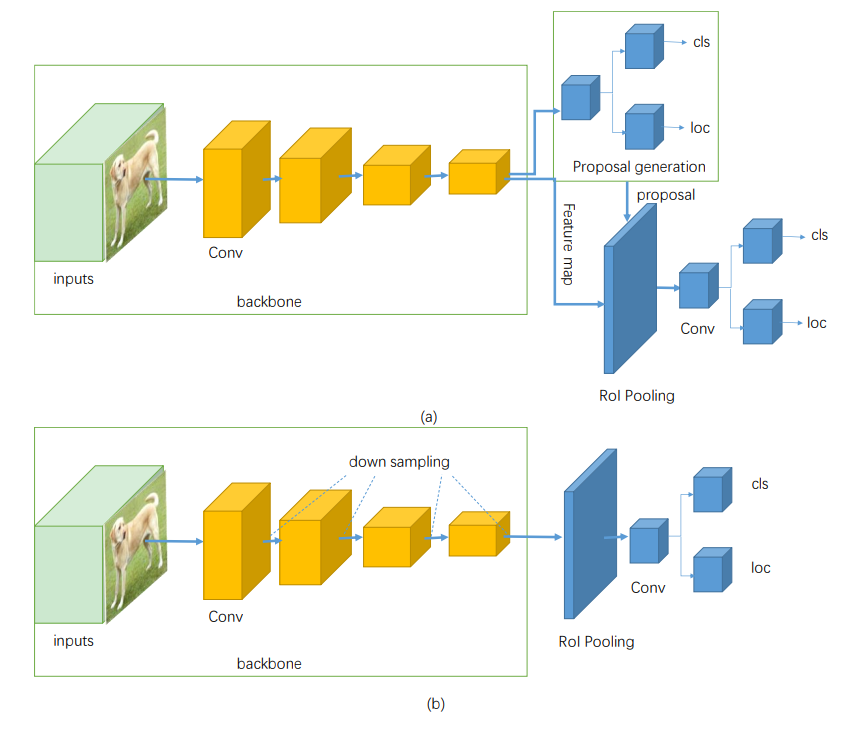
(1) 입력 단계(Input)
원본 이미지를 모델의 입력으로 사용한다. 일반적으로 RGB 3채널 형태이다. 이 단계에서 데이터 증강(augmentation)이 적용되기도 한다.
(2) 백본(Backbone) - 특징 추출(Feature Extraction)
CNN을 사용해 이미지의 시각적 특징을 추출한다.(ResNet, VGG, CSPDarknet, EfficientNet 등이 사용됨) 출력은 다양한 해상도의 특징 지도(Feature Map)이다.
- 큰 해상도 작은 객체 탐지에 유리
- 작은 해상도 큰 객체 탐지에 유리
(3) 넥(Neck) - 다중 해상도 특징 결합
넥(Neck)은 백본(Backbone)이 뽑아낸 서로 다른 해상도의 특징 맵을 결합가공해, 탐지 성능을 높이는 중간 처리 단계이다. 작은 객체와 큰 객체 모두 잘 탐지하려면 여러 스케일의 정보를 동시에 활용해야하기 때문에 필요하다.
대표 구조로는
- FPN(Feature Pyramid Network) : 위, 아래로 특징을 전달해 다중 해상도 결합
- PANet(Path Aggregation Network) : FPN에 경로 보강(Path Augmentation)을 추가해 하위 계층 측징을 더 잘 전달
- BiFPN : 가중치 기반 양방향 특징 통합(효율성과 정확성 향상)
출력은 다중 해상도의 통합된 특징 맵이 출력된다.
(4) 헤드(Head), 파이프라인 분기: Two-Stage vs One-Stages
-
Two-Stage Detector
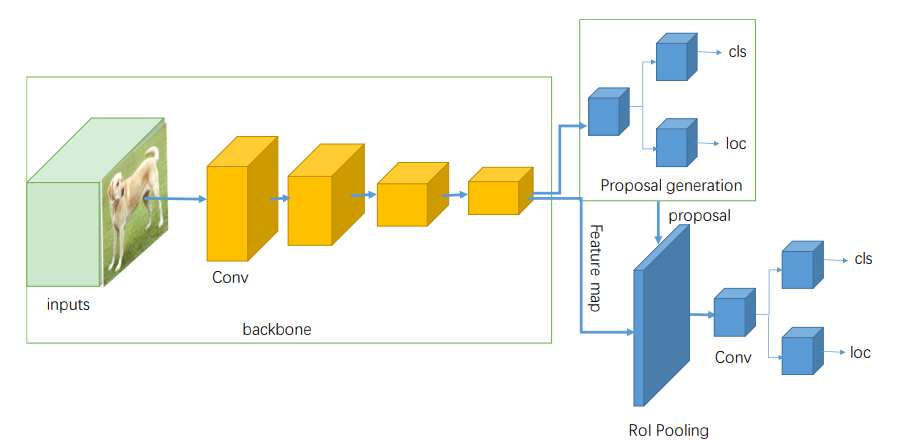
Stage 1: 영역 제안(Region Proposal) : RPN(Region Propsal Network) 또는 Selective Search로 이미지에서 객체가 있을 법한 후보 영역(ROI, Region of Interest)를 찾는다.
Stage 2: 분류(Classification) + 위치 회귀(Localization) : ROI Pooling/Align으로 고정 크기의 특징 맵으로 변환, 각 ROI에 대해 클래스 확률과 경계 상자 좌표를 예측한다.대표 모델로는 R-CNN, Fast R-CNN, Faster R-CNN 등이 있다. 해당 구조는 정확도는 높으나 속도는 상대적으로 느리다.
-
One-Stage Detector
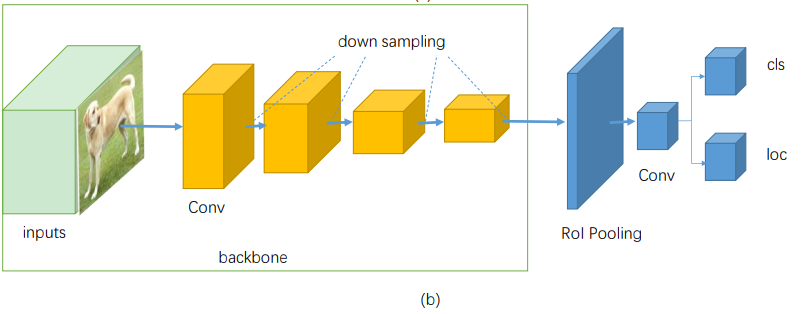
RPN 같은 별도의 제안 단계 없이, 특징 맵 상의 모든 셀 또는 앵커 박스에 대해 직접 클래스와 위치를 동시에 예측한다.
대표 모델로는 YOLO, SSD, RetinaNet 등이 있다. 속도가 빠르고, 실시간 처리가 가능하지만, 작은 객체 탐지 성능은 상대적으로 떨어질 수 있다.
이후는 후처리 단계로 Non-Maximum Suppression(NMS)로 중복 박스 제거 후 출력한다.
출력은 각 객체에 대한 클래스 라벨 + 신뢰도 점수 + 경계 상자 좌표를 반환한다. (예:
Dog, 0.93, x=120, y=80, w=200, h=150)
평가 지표
객체 탐지(Object Detection)의 성능 평가는 위치 예측의 정확도와 분류 정확도를 모두 반영해야 하므로, 이미지 분류와는 다른 지표들이 사용된다. 대표적으로는 IoU(Intersection over Union), mAP(mean Average Precision), Precision/Recall, FPS 등이 있다.
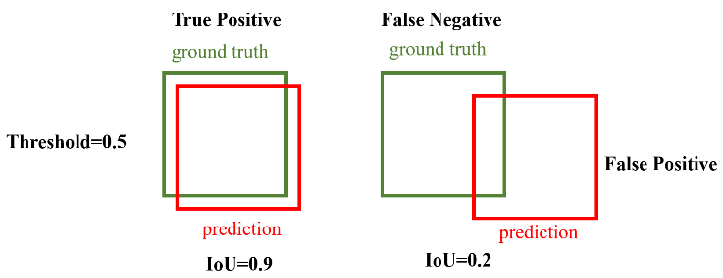
1. IoU(Intersection over Union) - 위치 정확도
IoU는 예측 경계 상자()와 실제 경계 상자()의 겹치는 면적 비율을 의미한다.
- IoU = 1 : 두 상자가 완벽히 일치
- IoU = 0 : 전혀 겹치지 않음
IoU는 예측을 정답으로 인정할 최소 기준값(IoU threshold)을 정한다.
2. Precision, Recall - 분류 정확도와 재현율
-
Precision(정밀도) : 모델이 "객체"라고 한 것 중 실제 객체의 비율
-
Recall(재현율) : 실제 객체 중에서 모델이 찾아낸 비율
-
TP(True Positive) : 올바르게 탐지한 객체
-
FP(False Positive) : 배경인데 객체로 잘못 탐지
-
FN(False Negative) : 객체인데 놓친 경우
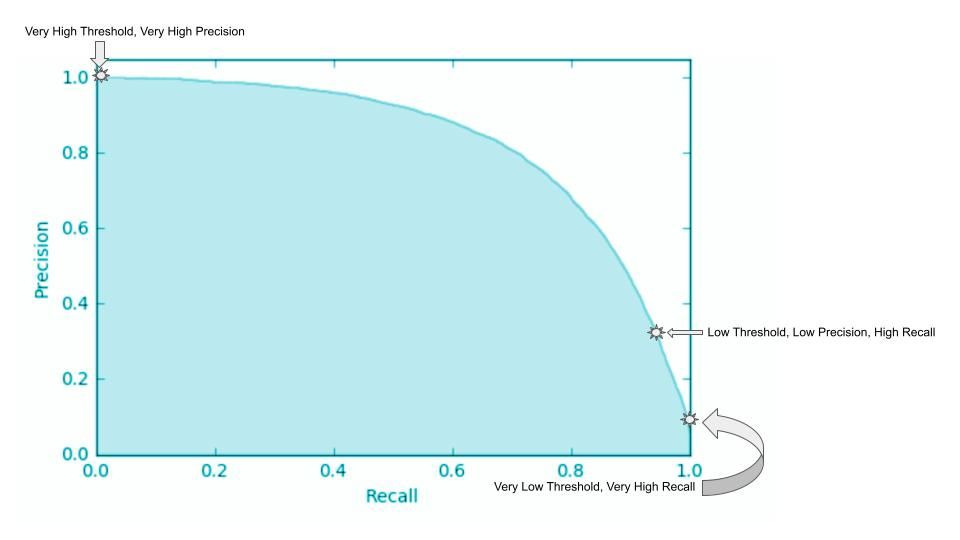
3. AP(Average Precision) - PR 곡선 기반 평가
PR 곡선(Precision-Recall Curve)을 그린 뒤, 그 면적을 계산한 값이다. AP가 클수록 좋은 모델이다.
- AP@0.5: IoU ≥ 0.5 기준에서의 Average Precision
- AP@[.5:.95]: IoU 0.5~0.95 구간 평균 (COCO 평가 방식, 더 엄격)
4. mAP(mean Average Precision) - 다중 클래스 평균
여러 클래스에 대해 AP를 구하고 평균을 낸 값이다.
- VOC 방식: mAP@0.5
- COCO 방식: mAP@[.5:.95] (IoU 기준 10개 구간 평균)
5. 추가 지표
- FPS(Frames Per Second) : 초당 처리 가능한 이미지 수 실시간성 평가
- Params / FLOPs : 모델의 파라미터 수와 연산량
- GIoU, DIoU, CIoU : IoU의 개선 버전
- GIoU : 상자가 겹치지 않는 경우에도 패널티 부여
- DIoU : 중심점 거리 고려
- CIoU : 중심점 거리 + 종횡비(aspect ratio)까지 반영
정리하자면, IoU는 위치 예측 정확도, Precision/Recall은 분류 성능, AP/mAP은 두 요소를 종합 평가, FPS는 속도, GIoU, DIoU, CIoU는 IoU 개선 손실 및 지표로 사용한다.
References
A Survey of Deep Learning-based Object Detection, DeepAI (https://arxiv.org/pdf/1907.09408v1)
IoU Image from https://www.researchgate.net/figure/Examples-when-IoU-threshold-is-05_fig4_373625169
Precision-Recall Curve in Python Tutorial - https://www.datacamp.com/tutorial/precision-recall-curve-tutorial
출처: https://doong-e.tistory.com/101 [폴밍끼의 인공지능:티스토리]
