
4.1 인공 신경망의 한계와 딥러닝 출현
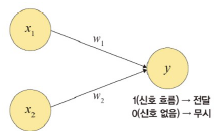
인공 신경망의 구조
: 입력층, 출력층, 가중치로 구성된 구조. 퍼셉트론이라는 선형 분류기
-
퍼셉트론: 다수의 신호를 입력으로 받아 하나의 신호 출력
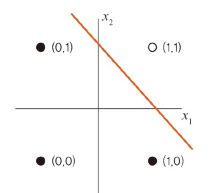
AND 게이트
: 모든 입력이 1일 때 작동
- 선형 분리
- 단층 퍼셉트론에서 학습 가능
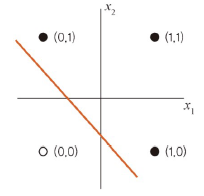
OR 게이트
: 입력 중에서 둘 중 하나만 1이거나 둘 다 1일 때 작동
- 선형 분리
- 단층 퍼셉트론에서 학습 가능
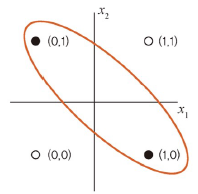
XOR 게이트
: 두 개 중 한 개만 1일 때 작동(배타적 논리합)
- 비선형적으로 분리되기 때문에 제대로 된 분류가 어려움
- 단층 퍼셉트론에서 학습이 불가능
- 해결 방안
- 다층 퍼셉트론: 입력층과 출력층 사이헤 하나 이상의 중간층(은닉층)을 두어 학습 가능
- 심층 신경망: 입력층과 출력층 사이에 은닉층이 여러 개 있는 신경망(=딥러닝)
4.2 딥러닝의 구조
딥러닝 용어
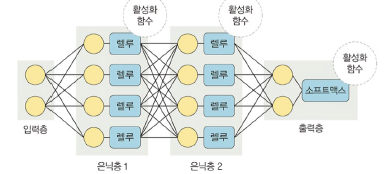
- 층(layer)
- 입력층(input): 데이터를 받는 층
- 은닉층(hidden): 입력 노드로부터 입력 값을 받아 가중합 계산, 이 값을 활성화 함수에 적용하여 출력층에 전달하는 층
- 출력층(output): 최종 결괏값이 포함된 층
- 가중치(Weight): 노드와 노드 간 연결 강도
- 바이어스(bias): 가중합에 더해주는 상수. 하나의 뉴런에서 활성화 함수를 거쳐 최종적으로 출력되는 값을 조절하는 역할
- 가중합(weighted sum): 가중치와 노드의 곱의 합
- 함수
- 활성화 함수: 신호를 입력 받아 이를 적절히 처리하여 출력해주는 함수
- 손실 함수: 가중치 학습을 위해 오차를 측정하는 함수
가중치
: 입력 값이 연산 결과에 미치는 영향력을 조절하는 요소
ex. w = 0.00, x = 10000000000 -> 0.00
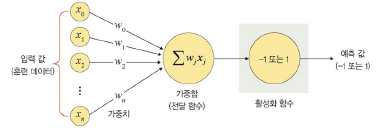
가중합
: 각 노드의 신호와 가중치의 곱의 합
(=전달함수: 노드의 가중합이 계산되면 이 가중합을 활성화 함수로 보냄)
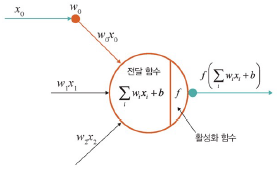
활성화 함수
: 전달 함수에서 전달받은 값을 출력할 때 일정 기준에 따라 출력 값을 변화시키는 비선형 함수
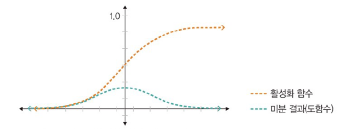
시그모이드 함수
: 선형 함수의 결과를 0~1 사이에서 비선형 형태로 변형
- 로지스틱 회귀 같은 분류 문제를 확률적으로 표현
- 기울기 소멸 문제: 모델의 깊이가 깊어지면 기울기가 사라지는 현상 -> 딥러닝에서는 잘 사용x
하이퍼 탄젠트 함수
: 선형 함수의 결과를 -1~1 사이에서 비선형 형태로 변형
- 시그모이드의 결과값의 평균이 0이 아닌 양수로 편향되는 문제 해결
- 기울기 소멸 문제 존재
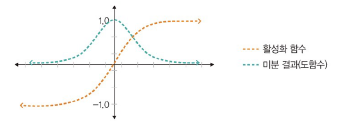
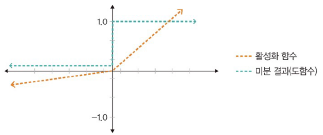
렐루 함수(Relu)
: 입력이 음수일 때는 0 출력, 양수일 때는 x 출력
- 경사하강법에 영향 x -> 학습 속도 빠름(하이퍼볼릭 탄젠트 함수 대비 학습 속도 6배), 기울기 소멸 문제 x
- 일반적으로 은닉층에서 사용
- 음수 값을 입력받으면 항상 0을 출력하여 학습 능력 감소
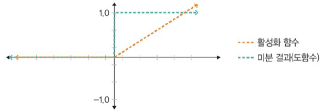
리키 렐루 함수(Leaky Relu)
: 입력이 음수일 때는 0이 아닌 매우 작은 수 반환
- 입력 값이 수렴하는 구간이 제거되어 렐루 함수의 문제 해결
소프트맥스 함수(Softmax)
: 입력 값을 0~1 사이에 출력되도록 정규화하여 출력 값들의 총합이 항상 1이 되도록 함
- 일반적으로 출력 노드의 활성화 함수로 많이 사용
- n: 출력층의 뉴런 개수, yk: k번째 출력
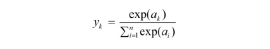
from tensorflow.keras import layers
model = tf.keras.Sequential()
# 유닛 64개를 가진 완전 연결층
model.add(layers.Dense(64, activation='relu')
model.add(layers.Dense(64, activation='relu')
# 출력 유닛 10개, 소프트맥스 함수 사용
model.add(layers.Dense(10, activation='relu')손실 함수
: 오차를 구하는 함수. 추정치가 실제 데이터와 얼마나 차이가 나는지 평가하는 지표.
- 0에 가까울수록 추정이 잘 된 것
평균 제곱 오차(MSE)
: 실제값과 예측값의 차이의 제곱의 평균

model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss='mse')크로스 엔트로피 오차(Cross-entropy)
: 분류 문제에서 원-핫 인코딩을 했을 때만 사용할 수 있는 오차 계산법
- 시그모이드 함수에 포함된 자연상수 e때문에 mse를 적용하면 매끄럽지 않은 그래프가 출력됨
- 경사하강법 과정에서 학습이 지역 최소점에서 멈추는 것을 방지하기 위해 자연상수 e에 반대되는 자연 로그를 출력값에 취함

model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])딥러닝 학습
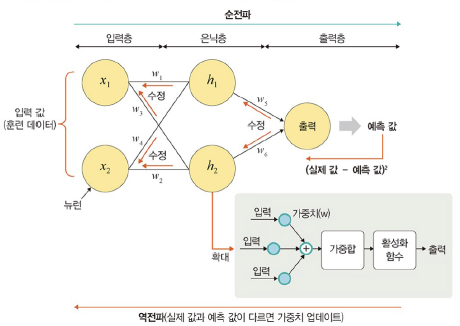
Step 1: 순전파
: 네트워크에 훈련 데이터가 들어올 때 발생
- 데이터를 기반으로 예측값을 계산하기 위해 전체 신경망을 교차해 지나감
- 모든 뉴런이 이전 층의 뉴런에서 수신한 정보에 변환(가중합 및 활성화 함수)을 적용하여 다음 층(은닉층)의 뉴런으로 전송하는 방식
- 모든 뉴런이 계산을 완료하면 예측값은 출력층에 도달
- 손실함수로 오류 추정. '0'이 이상적 -> 모델 반복 훈련하면서 가중치 조정
Step 2: 역전파
: 손실이 계산되면 정보는 역으로 전파됨(출력층 -> 은닉층 -> 입력층)
- 출력층에서의 손실비용은 은닉층에서 각 뉴런이 출력에 기여한 상대적 기여도에 따라 달라짐
- 모든 뉴런에 대해 역전파 진행하여 계산된 각 뉴런 결과를 순전파의 가중치 값으로 사용
딥러닝의 문제점과 해결방안
딥러닝은 여러 은닉층을 결합하여 비선형 영역을 표현하여 데이터 분류가 잘 됨
문제점
- 과적합 문제: 훈련 데이터를 과하게 학습하여 실제 데이터에 대한 오차 증가
- 드롭 아웃(dropout): 학습 과정 중 임의로 일부 노드들을 학습에서 제외하여 과적합 방지
# drop_rate = 0.3: 0.7에 해당하는 노드들만 남겨두고 다 지워버림
tf.keras.layers.Dropout(0.3) -
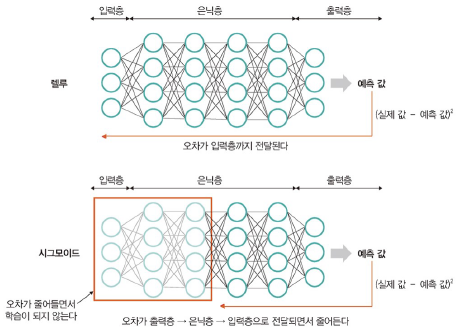
기울기 소멸 문제: 출력층에서 은닉층으로 전달되는 오차가 크게 줄어 학습이 되지 않는 현상
- 학습되는 양이 0에 가가워져 더디게 학습되다가 오차를 더 줄이지 못하고 그대로 수렴
- 은닉층이 많은 신경망에서 발생
- 렐루 활성화 함수를 사용하여 해결
-
성능 감소 문제: 경사하강법에서 손실함수의 비용이 최소가 되는 지점을 찾기 위해 기울기가 낮은 쪽으로 계속 이동시키는 과정을 반복하면서 생기는 문제
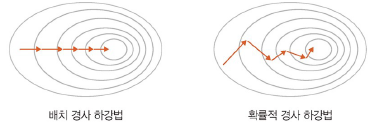
- 배치 경사 하강법: 전체 데이터셋에 대한 오류를 구한 후 기울기를 한 번만 계산하여 모델의 파라미터를 업데이트하는 방식
- 전체 훈련 데이터셋에 대해 가중치 편미분
- 한 스텝에 모든 훈련 데이터셋을 사용하여 학습 시간이 긺
- 확률적 경사 하강법: 임의로 선택한 데이터에 대해 기울기를 계산하는 방법
- 학습 시간이 빠름
- 파라미터 변경 폭이 불안정
- 배치 경사 하강법보다 정확도가 낮을 수 있음
- 미니 배치 경사 하강법: 전체 데이터셋을 미니 배치 여러 개로 나누고 미니 배치 한 개마다 기울기를 구하여 그것의 평균 기울기를 이용하여 모델을 업데이트하며 학습하는 방식
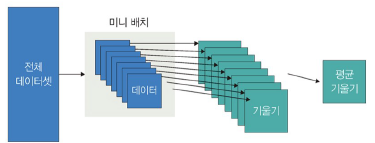
- 전체 데이터를 게산하는 것보다 빠름
- 확률적 경사 하강법보다 안정적
- 가장 많이 사용
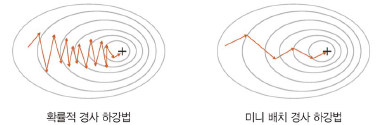
- 배치 경사 하강법: 전체 데이터셋에 대한 오류를 구한 후 기울기를 한 번만 계산하여 모델의 파라미터를 업데이트하는 방식
# 확률적 경사 하강법
model.fit(X_train, y_train, batch_size = 1)
# 미니 배치 경사 하강법
model.fit(X_train, y_train, batch_size = 12)확률적 경사 하강법의 옵티마이저
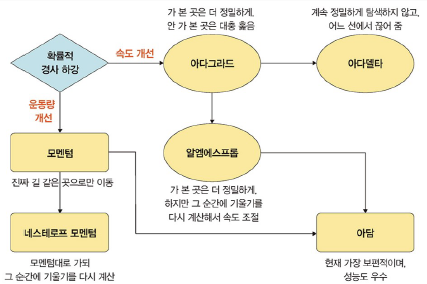
- 속도 조정
- 아다그라드(Adagrad)
: 가중치의 업데이트 횟수에 따라 학습률을 조정하는 방법- 많이 변화하지 않는 변수들의 학습률은 크게, 많이 변화하는 변수들의 학습률은 작게
- 많이 변화한 변수는 최적값에 근접했을 것이라는 가정 하에 작은 크기로 이동하면서 세밀하게 값 조정
- G 함수: 파라미터마다 다른 학습률 부여. 이전 G값의 누적.
기울기가 크면 G값이 커지면서 학습률이 작아짐
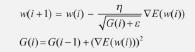
- 아다델타(Adadelta): 아다그라드에서 G값이 커짐에 따라 학습이 멈추는 문제 해결하기 위한 방법
- 아다그라드의 수식에서 학습률을 D함수로 변환하였기 때문에 학습률에 대한 하이퍼파라미터 필요 없음
- D 함수: 가중치의 변화량 크기를 누적한 값
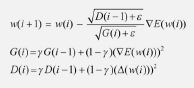
- 알엠에스프롭(RMSProp): 아다그라드의 G 값이 무한히 커지는 것을 방지하고자 제안된 방법
- G 함수에 r를 추가하여 학습률 크기를 비율로 조정할 수 있도록 함
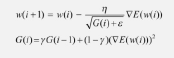
- G 함수에 r를 추가하여 학습률 크기를 비율로 조정할 수 있도록 함
- 아다그라드(Adagrad)
- 운동량 조정
- 모멘텀(Momentum): 가중치를 수행하기 전에 이전 수정 방향을 참조하여 같은 방향으로 일정한 비율만 수정하면서 기울기를 구하는 방법
- 지그재그 현상 감소
- 관성 효과: 이전 이동 값 고려하여 일정 비율만큼 다음 값 결정
- 확률적 경사 하강법과 함께 사용
확률적 경사 하강법에서 기울기를 속도로 대체하여 사용(이전 속도의 일정 부분을 반영)
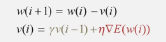
- 네스테로프 모멘텀(Nesterov Accelerated Gradient, NAG): 모멘텀 값이 적용된 지점에서 기울기 값 계산
-
모멘텀으로 절반 정도 이동한 후 어떤 방식으로 이동해야 하는지 다시 계산하여 결정
-
빠른 이동 속도는 그대로 가져가면서 멈추어야 할 적절한 시점에 제동을 거는 데 훨씬 용이
-
이전에 학습했던 속도와 현재 기울기에서 이전 속도를 뺀 변화량을 반영하여 가중치 구함
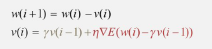
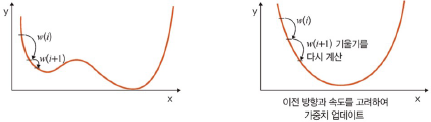
-
- 모멘텀(Momentum): 가중치를 수행하기 전에 이전 수정 방향을 참조하여 같은 방향으로 일정한 비율만 수정하면서 기울기를 구하는 방법
- 속도와 운동량 혼용
- 아담(Adam): 모멘텀과 알엠에스프롭의 장점을 결합한 경사 하강법
- 기울기의 제곱을 지수 평균한 값(알엠에스프롭 G 함수)과 v(i)(모멘텀)를 수식에 활용
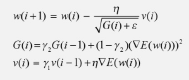
- 기울기의 제곱을 지수 평균한 값(알엠에스프롭 G 함수)과 v(i)(모멘텀)를 수식에 활용
- 아담(Adam): 모멘텀과 알엠에스프롭의 장점을 결합한 경사 하강법
딥러닝의 장점
특성 추출
: 데이터 별로 어떤 특징을 가지고 있는지 찾아내고, 이를 토대로 데이터를 벡터로 변환하는 작업
빅데이터의 효율적 활용
: 데이터 사례가 많을수록 특징 추출의 성능 향상
4.3 딥러닝 알고리즘
심층 신경망(DNN)
: 입력층과 출력층 사이에 다수의 은닉층을 포함하는 인공 신경망
- 다양한 비선형적인 관계 학습 가능
- 학습을 위한 연산량 많음, 기울기 소멸 문제
=> 드롭아웃, 렐루 함수, 배치 정규화 적용하여 해결
합성곱 신경망(CNN)
: 합성곱층(Convolutional layer)과 풀링층(Pooling layer)을 포함하는 인공 신경망
- 이미지 처리에서 객체를 탐색, 객체 위치를 찾아내는 데 유용
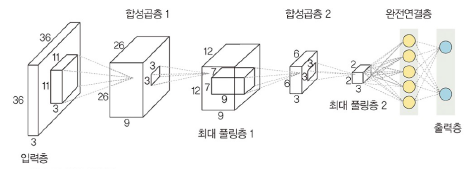
- LeNet-5, AlexNet, VGG, GoogLeNet, ResNet
- 차별성
- 각 층의 입출력 형상 유지
- 이미지의 공간 정보 유지, 인접 이미지와 차이가 있는 특징 효과적으로 인식
- 복수 필터로 이미지 특징 추출, 학습
- 추출한 이미지의 특징을 모으고 강화하는 풀링층 존재
- 공유 파라마터로 필터를 사용하여 학습 파라미터가 매우 적음
순환 신경망(RNN)
: 시계열 데이터(음악, 영상 등) 같은 시간 흐름에 따라 변화하는 데이터를 학습하기 위한 인공 신경망
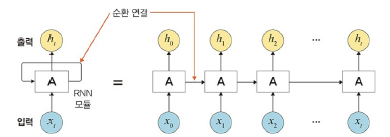
- 기울기 소멸 문제로 학습이 제대로 되지 않음 -> LSTM(메모리 개념 도입)
- 자연어 처리 분야
특징
- 많은 데이터가 시간성을 가짐
- 시간성 정보를 이용하여 데이터 특성을 잘 다룸
- 시간에 따라 내용이 변하므로 데이터는 동적, 길이가 가변적
제한된 볼츠만 머신(Boltzmann Machine)
: 가시층과 은닉층으로 구성되고, 가시층이 은닉층과만 연결된 모델
특징
- 차원 감소, 분류, 선형 회귀 분석, 협업 필터링, 특성 값 학습, 토픽 모델링 등에 사용
- 기울기 소멸 문제를 해결하기 위해 사전 학습 용도로 활용
- 심층 신뢰 신경망(DBM)의 요소로 활용
심층 신뢰 신경망(DBM)
: 입력층과 은닉층으로 구성된 제한된 볼츠만 머신을 블록처럼 여러 층으로 쌓은 형태로 연결된 신경망
- 비지도 학습 가능
- 부분적 이미지에서 전체를 연상하는 일반화, 추상화 과정을 구현할 때 유용
학습 과정
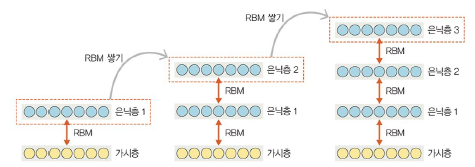
Step 1: 가시층과 은닉층 1의 제한된 볼츠만 머신 사전 훈련
Step 2: 첫 번째 층 입력 데이터와 파라미터 고정, 두 번째 층 제한된 볼츠만 머신 사전 훈련
Step 3: 원하는 층 개수만큼 제한된 볼츠만 머신 쌓아올려 전체 DBM 완성
특징
- 순차적으로 심층 신뢰 신경망을 학습시켜 계층적 구조 생성
- 비지도 학습
- 위로 올라갈수록 추상적 특성 추출
- 학습된 가중치를 다층 퍼셉트론의 가중치 초기값으로 사용
