
7.1 시계열 문제
시계열 분석
: 특정 대상의 시간에 따라 변하는 데이터를 사용하여 추이를 분석하는 것
- 추세 파악, 향후 전망 등을 예측하기 위한 용도
- ex. 주가/환율 변동, 기온/습도 변화 등
시계열 형태
불규칙 변동
: 시간에 따른 규칙적인 움직임과 달리 어떤 규칙성이 없어 예측 불가능하고 우연적으로 발생하는 변동
- ex. 전쟁, 홍수, 화재, 지진, 파업 등
추세 변동
: 시계열 자료가 갖는 장기적인 변화 추세
- 추세: 장기간에 걸쳐 지속적으로 증가, 감소, 일정 상태 유지하는 성향
- 짧은 기간 동안 찾기 어려움
- ex. 국내총생산, 인구증가율
순환 변동
: 일정한 기간을 주기로 순환적으로 나타나는 변동
- 1년 이내 주기로 곡선을 그리며 추세 변동에 따라 변동
- ex. 경기 변동
계절 변동
: 계절적 영향과 사회적 관습에 따라 1년 주기로 발생하는 것
- 계절 따라 순환, 변동하는 특징
7.2 AR, MA, ARMA, ARIMA
AR(Auto Regression, 자기 회귀)
: 이전 관측 값이 이후 관측 값에 영향을 준다는 아이디어에 대한 모형
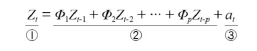
p 시점을 기준으로 그 이전의 데이터에 의해 현재 시점의 데이터가 영향을 받는 모형
(이전 데이터의 '상태'에서 현재 데이터의 상태를 추론)
- ①: 시계열 데이터의 현재 시점
- ②: 과거가 현재에 미치는 영향을 나타내는 모수(Φ)와 시계열 데이터의 과거 시점의 곱
- ③: 시계열 분석에서 오차 항(=백색 잡음)
MA(Moving Average, 이동 평균)
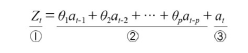
이전 데이터의 '오차'에서 현재 데이터의 상태를 추론
- ①: 시계열 데이터의 현재 시점
- ②: 매개변수(Θ)와 과거 시점의 오차의 곱
- ③: 오차 항(=백색 잡음)
ARMA(AutoRegression Moving Average, 자동 회귀 이동 평균)
: AR, MA 두 가지 관점에서 과거의 데이터를 사용하는 모델
- 윈도우: 주어진 전체 데이터 중 한 번에 가져오는 데이터의 부분 집합의 크기
- 시계열을 따라 윈도우 크기만큼 슬라이딩(moving)
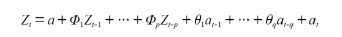
ARIMA(AutoRegressive Integrated Moving Average, 자동 회귀 누적 이동 평균)
: 자기 회귀와 이동 평균을 둘 다 고려하는 모형. 과거 데이터의 선형 관계 뿐만 아니라 추세(cointegration)까지 고려한 모델
ARIMA() 파라미터
-
p: 자기 회귀 차수
-
d: 차분 차수
-
q: 이동 평균 차수
-
fit(): 학습 / predict(): 예측
from pandas import datetime
from pandas import DataFrame
from statsmodels.tsa.arima_model import ARIMA
from matplotlib import pyplot
# 시간을 표현하는 함수 정의
def parser(x):
return datetime.strptime('199'+x, '%Y-%m') # 날짜와 시간 정보를 문자열로 변경
# 데이터 로드
series = read_csv('../chap7/data/sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# train/test set 분리
X = series.values
X = np.nan_to_num(X)
size = int(len(X) * 0.66)
train, test = X[0:size], X[size:len(X)]
history = [x for x in train]
predictions = list()
# ARIMA 함수 호출
model = ARIMA(history, order=(5,1,0))
# 모델 학습
model_fit = model.fit(disp=0) # disp=0: 디버그 정보 제공 기능 비활성화
print(model_fit.summary())
# 오차 정보
residuals = DataFrame(model_fit.resid)
residuals.plot()
pyplot.show()
residuals.plot(kind='kde')
pyplot.show()
print(residuals.describe())- 오류 평균 값이 0이 아님 = 예측이 치우쳐 있음
# 학습 및 예측
for t in range(len(test)):
model = ARIMA(history, order=(5,1,0))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0]
predictions.append(yhat)
obs = test[t]
history.append(obs)
print('predicted=%f, expected=%f' % (yhat, obs))
error = mean_squared_error(test, predictions)
print('Test MSE: %.3f' % error)
pyplot.plot(test)
pyplot.plot(predictions, color='red')
pyplot.show()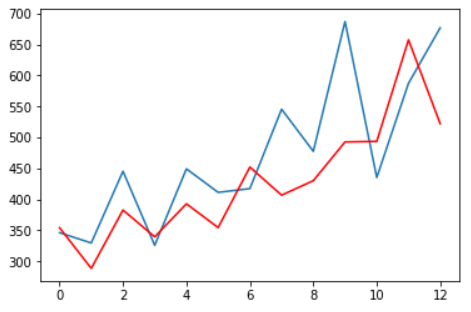
- 빨간색: 실제/ 파란색: 모형 실행 결과
- 우상향 추세
- ARIMA를 이용하면 데이터 경향을 파악하여 미래 예측할 수 있음
7.3 순환 신경망(RNN)
: 시간적으로 연속성이 있는 데이터를 처리하려고 고안된 인공 신경망
- 기억: 현재까지 입력 데이터를 요약한 정보
- 새로운 입력이 네으워크로 들어올 때마다 기억이 조금씩 수정되며 최종적으로 남겨진 기억이 모든 입력 전체를 요약한 정보가 됨
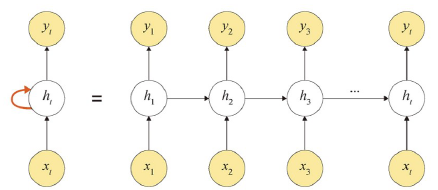
- 첫 번째 입력 -> 첫 번째 기억(h1)
- 두 번째 입력 -> h1과 새로운 입력을 참고하여 두 번째 기억(h2)
유형
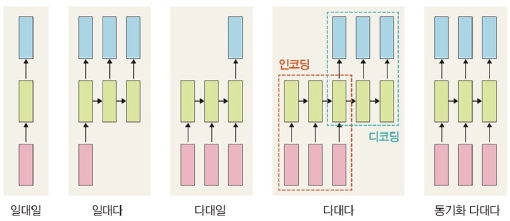
일대일
: 순환이 없어 RNN이라고 말하기 어려움. 순방향 네트워크
일대다
: 입력이 하나, 출력이 다수. 이미지 캡션
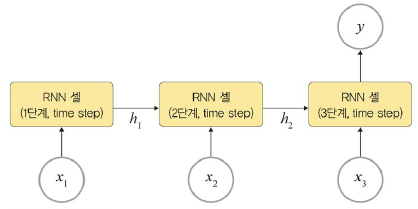
다대일
: 입력이 다수, 출력이 하나. 감성 분석기
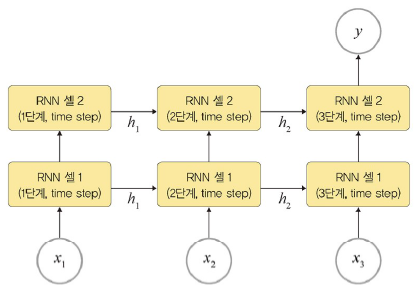
- 다대일
- 적층된 다대일
다대다
: 입력과 출력이 다수. 언어 자동 번역기
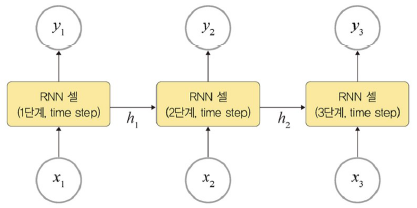
동기화 다대다
: 입력과 출력이 다수. 프레임 수준의 비디오 분류
RNN 계층과 셀
RNN 계층: 입력된 배치 순서열을 모두 처리
RNN 셀: 오직 하나의 단계만 처리. RNN 계층의 for loop 구문의 내부
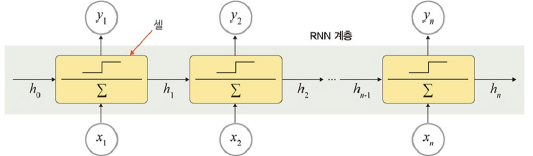
셀은 단일 입력과 과거 상태를 가져와서 출력과 새로운 상태를 생성함
셀 유형
- SimpleRNNCell: SimpleRNN 계층에 대응되는 RNN 셀
- GRUCell: GRU 계층에 대응되는 GRU 셀
- LSTMCell: LSTM 계층에 대응되는 LSTM 셀
7.4 RNN 구조
: 은닉층 노드들이 연결되어 이전 단계 정보를 은닉층 노드에 저장할 수 있도록 구성한 신경망
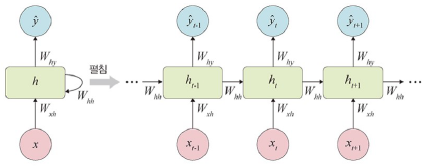
가중치
- Wxh: 입력층 -> 은닉층
- Whh: 은닉층 -> 은닉층
- Why: 은닉층 -> 출력층
RNN 계산
은닉층 계산
- 활성화 함수: 일반적으로 하이퍼볼릭 탄젠트 함수
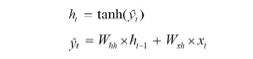
출력층 계산
- 활성화 함수: 소프트맥스 함수
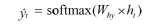
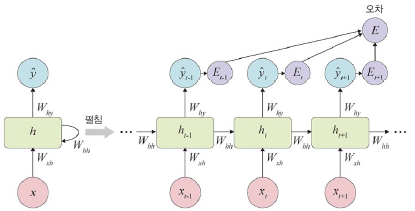
오차
: MSE 적용
역전파
- 모든 단계마다 처음부터 끝까지 역전파
- BPTT: 각 단계마다 오차를 측정하고 이전 단계로 전달
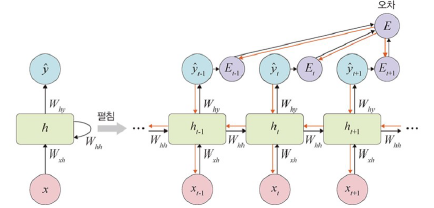
- 오차를 이용하여 Wxh, Whh, Why, bias 업데이트
- 기울기 소멸 문제: 오차가 멀리 전파될 때 계산량이 만아지고 전파 양이 점차 적어지는 문제
- 생략된-BPTT(오차를 일정 시점까지만(보통 5단계) 전파), LSTM, GRU 사용
RNN 셀 구현
#################### 네트워크 생성
class RNN_Build(tf.keras.Model):
def __init__(self, units): # 인스턴스를 생성할 때 초기화하는 부분, 객체 생성될 때 호출
super(RNN_Build, self).__init__() # 메서드 호출
self.state0 = [tf.zeros([batch_size, units])] # self는 자신의 인스턴스, 0 값으로 채워진 텐서를 생성하여 저장
self.state1 = [tf.zeros([batch_size, units])]
# 임베딩: 자연어를 숫자 형태의 벡터로 바꾼 결과 또는 그 일련의 과정 전체
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len) # 임베딩층, 전체 단어 집합 크기, 임베딩 후 단어의 차원, 입력 데이터의 길이
self.RNNCell0 = tf.keras.layers.SimpleRNNCell(units, dropout=0.2) # SimpleRNN의 셀 클래스(출력 공간의 차원, 입력 중에서 삭제할 유닛의 비율)
self.RNNCell1 = tf.keras.layers.SimpleRNNCell(units, dropout=0.2)
self.outlayer = tf.keras.layers.Dense(1) # 출력 유닛 크기
def call(self, inputs, training=None): # 인스턴스가 생성될 때 호출
x = inputs
x = self.embedding(x) # 입력 데이터에 원-핫 인코딩 적용
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1): # 그룹화된 데이터를 행렬 형태로 전환하여 연산
out0, state0 = self.RNNCell0(word, state0, training)
out1, state1 = self.RNNCell1(out0, state1, training)
x = self.outlayer(out1)
prob = tf.sigmoid(x) # 시그모이드 활성화 함수
return prob
#################### 모델 훈련
import time
units = 64
epochs = 4
t0 = time.time()
model = RNN_Build(units)
# 이진분류-> BinaryCrossentropy(), metrics: 훈련 모니터링을 위한 지표, experimental_run_tf_function: 모델 인스턴스화
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.losses.BinaryCrossentropy(),
metrics=['accuracy'],
experimental_run_tf_function=False)
# epochs: 학습데이터 반복 횟수, validation_freq: 모든 에포크가 아닌 적절한 간격을 두고 검증 데이터셋에 대한 계산
model.fit(train_data, epochs=epochs, validation_data=test_data, validation_freq=2)
#################### 모델 평가
print("훈련 데이터셋 평가...")
(loss, accuracy) = model.evaluate(train_data, verbose=0)
print("loss={:.4f}, accuracy: {:.4f}%".format(loss,accuracy * 100))
print("테스트 데이터셋 평가...")
(loss, accuracy) = model.evaluate(test_data, verbose=0)
print("loss={:.4f}, accuracy: {:.4f}%".format(loss,accuracy * 100))
t1 = time.time()
print('시간:', t1-t0)RNN 계층 구현
#################### 네트워크 생성
class RNN_Build(tf.keras.Model):
def __init__(self, units):
super(RNN_Build, self).__init__()
self.embedding = tf.keras.layers.Embedding(total_words, embedding_len, input_length=max_review_len)
self.rnn = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units, dropout=0.5, return_sequences=True),
tf.keras.layers.SimpleRNN(units, dropout=0.5)
]) # units: 네트워크 층 수(출력 공간의 차원), return_sequences=True: 전체 순서 반환(False는 마지막 출력만 반환)
self.outlayer = tf.keras.layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
# 다수의 셀을 사용하는 경우
#for word in tf.unstack(x, axis=1):
# out0, state0 = self.RNNCell0(word, state0, training)
# out1, state1 = self.RNNCell1(out0, state1, training)
# simpleRNN
x = self.rnn(x)
x = self.outlayer(x)
prob = tf.sigmoid(x)
return prob
#################### 이후 과정 동일