
12.1 강화학습이란
: 어떤 환경에서 어떤 행동을 했을 때 그것이 잘된 행동인지 잘못된 행동인지를 판단하고 보상 또는 벌칙을 주는 과정을 반복해서 스스로 학습하게 하는 분야
구성 요소
- 환경: 에이전트가 다양한 행동을 해보고, 그에 따른 결과를 관측할 수 있는 시뮬레이터
ex. 게임기 - 에이전트: 환경에서 행동하는 주체
ex. 게임하는 사람 - 환경과 상호작용하는 에이전트를 학습시키는 것이 강화학습의 목표
과정

- 에이전트가 상태에서 행동을 취하며 학습해 나감
- 에이전트가 취한 행동은 그에 대한 응답으로 양, 음, 0의 보상을 돌려받음
용어
- 상태: 에이전트가 관찰 가능한 상태의 집합
- 자신의 상황에 대한 관찰
- 시간에 따라 변화
- 시간 t에서의 모든 상태의 집합 S
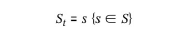
- 행동: 에이전트가 상태 St에서 가능한 행동
- 전체 행동의 집합 A에 대해 시간 t에서 특정 행동 a를 하는 것
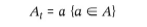
- 전체 행동의 집합 A에 대해 시간 t에서 특정 행동 a를 하는 것
- 강화학습의 문제들은 마르코프 프로세스에 기반하는 마르코프 결정 과정으로 표현
12.2 마르코프 결정 과정
마르코프 프로세스
정의
-
어떤 상태가 일정한 간격으로 변하고, 다음 상태는 현재 상태에만 의존하는 확률적 상태 변화
- 현재 상태에 대해서만 다음 상태 결정
- 변화 상태들이 체인처럼 엮여 있음 (마르코프 체인)
-
마르코프 특성을 지니는 이산 시간에 대한 확률 과정
- 확률 과정: 시간에 따라 어떤 사건의 확률이 변화하는 과정
- 이산 시간: 시간이 이산적으로 변화
- 마르코프 특성: 과거 상태(S1, ..., St-1)과 현재 상태(St)가 주어졌을 때 미래 상태(St+1)는 과거 상태와는 독립적으로 현재 상태로만 결정
- 과거, 현재 모두 고려 = 현재만 고려
- 현재 상태가 바로 직전의 상태에만 의존

전이
: 시간에 따른 상태 변화
- 상태 i가 있을 때 그 다음 상태 j가 될 확률: 상태 전이 확률
- ex. t에서의 상태 s, t+1에서의 상태 s'

- ex. t에서의 상태 s, t+1에서의 상태 s'
ex
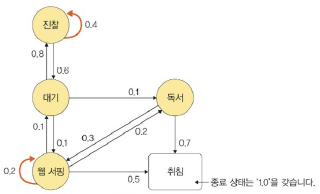
- 상태: 대기, 진찰, 독서, 웹 서핑, 취침
- 하나의 상태에서 다른 상태로 이동할 확률의 합 = 1
- 취침: 종료 상태
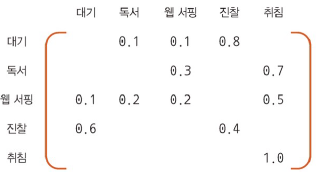
- 상태 전이 확률 행렬
마르코프 보상 프로세스(MRP)
: 마르코프 프로세스에서 각 상태마다 좋고 나쁨이 추가된 확률 모델
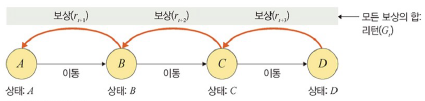
- 리턴: 모든 보상의 합
- 할인율(γ): 미래 가치를 현재 시점에서의 가치로 변환
- 0< γ < 1
- 0이면, 바로 다음의 보상만 추구하는 근시안적 행동
- 1에 가까워질수록 미래 보상에 대한 할인이 적어져 미래 보상을 많이 고려하게 되는 원시안적 행동

- 가치 함수: 현재 시점에서 미래의 모든 기대되는 보상을 표현하는 미래 가치
- 가치: 앞으로 발생할 것으로 기대되는(E) 모든 보상의 합
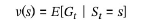
- 가치함수를 최대한 정확하게 찾는것, 미래 가치가 가장 클 것으로 기대되는 결정을 하고 행동하는 것이 강화 학습의 목표
- 가치: 앞으로 발생할 것으로 기대되는(E) 모든 보상의 합
ex
웹 서핑 가치 = -2.4, 진찰 가치 = 1.2
-
γ = 0
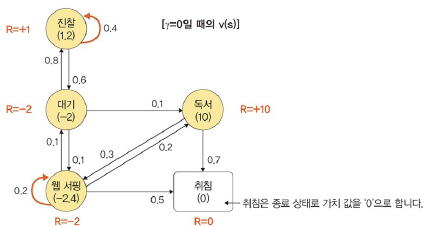
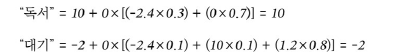
- 미래의 보상을 고려하지 않아 근시안적인 가치 값으로만 나타남
-
γ = 0.9
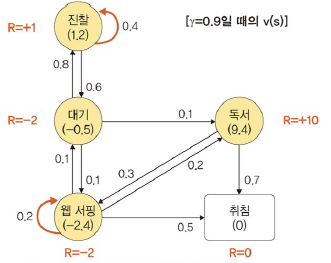

웹 서핑 가치 = -24, 진찰 가치 = 0.3
- γ = 1

- 모든 미래 가치를 할인 없이 고려하여 매우 원시안적인 상태로 가치 값들이 나타남
마르코프 결정 과정(MDP)
: 마르코프 보상 과정에서 행동이 추가된 확률 모델
- 목표: 정의된 문제에 대해 각 상태마다 전체적인 보상을 최대화하는 행동이 무엇인지 결정
정책(π)
: 각각의 상태마다 행동 분포를 표현하는 함수
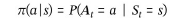
- π를 따를 때 s에서 s'로 이동할 확률

- s에서 얻을 수 있는 보상(R)
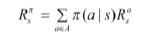
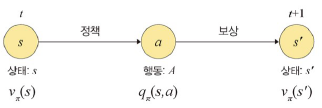
가치 함수
-
상태-가치 함수
: 주어진 정책 π에 따라 행동을 결정하면서 상태 s에서 얻을 수 있는 리턴의 기댓값

- ①: 즉각적 보상
- ②: 미래의 보상에 할인율이 곱해진 것
- 현재시점의 상태-가치 함수가 바로 다음 시점의 상태-가치 함수로 표현됨
-
행동-가치 함수
: 상태 s에서 a라는 행동을 취했을 때 얻을 수 있는 리턴의 기댓값

-
가치함수를 계산하는 방법은 시간 복잡도가 필요해 상태 수가 많으면 적용하기 어렵다는 문제를 해결하는 방법
- 다이나믹 프로그래밍: 상태와 행동이 많지 않고 모든 상태와 전이 확률을 알고 있으면 사용 가능. But, 대부분 강화학습은 상태가 많고 전이되는 경우 수도 많아 적용 어려움
- 몬테카를로: 전체 상태 중 일부 구간만 방문하여 근사적으로 가치 추정
- 초기 상태 -> 중간 상태 경유 -> 최종 상태까지 간 후 최종 보상 측정, 방문했던 상태 가치 업데이트
- 시간 차 학습: 최종 상태에 도달 전에 방문한 상태의 가치를 즉시 업데이트
- 다이나믹 프로그래밍과 몬테카를로의 중간적인 특성
- 본격적인 강화 학습의 단계
- 함수적 접근 학습: 연속적이 상태를 학습하고자 상태와 관련된 특성 벡터 도입, 특성의 가중치를 업데이트 하여 가치의 근사치 찾음
12.3 MDP를 위한 벨만 방정식
: 상태-가치 함수와 행동-가치 함수의 관계를 나타내는 방정식
벨만 기대 방정식
: 정책을 고려한 다음 상태의 이동
MDP의 상태-가치 함수 도출

- ①: 가치함수 = 현재 시점에서 미래에 기대되는 보상들의 총합
- 행동 방향을 몰라 기댓값으로 정의
- ②: 할인율을 적용하여 풀어쓴 것
- ③: 할인율을 기준으로 묶어준 것 -> 다음 상태의 가치(Gt+1)
- ④: Gt+1로 변경
- ⑤: 현재 상태의 가치 vπ(s) = Gt => vπ(st+1) = Gt+1
- 현재 시점의 가치는 현재의 보상과 다음 시점의 가치로 표현할 수 있음
상태-가치 함수

- 기댓값: 현재 상태에서 정책에 따라 행동했을 때 얻을 수 있는 각각의 행동(π(a|s))과 그 행동이 발생할 확률(p(s',r|s,a))의 곱
- Rt+1: 현재 행동을 선택했을 때 즉각적으로 얻어지는 보상
- γGt+1: 미래에 일어날 보상에 할인율이 곱해진 것 = 미래에 일어날 모든 일의 평균치
- ②의 기댓값은 다음 상태 s'의 상태-가치 함수가 됨

- ③, ④: 상태-가치 함수의 벨만 방정식
- qπ(s, a) 변환
- 상태 s에서 행동 a를 했을 때의 보상과 그다음 상태의 가치함수로 구성
- 다음 상태-가치 함수는 t+1 시점의 가치함수 -> 할인율, 현재(t) 상태 s에서 다음(t+1) 상태 s'로 전이될 확률 적용
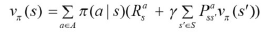
행동-가치 함수
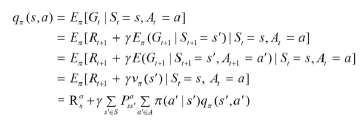
백업 다이어그램
: 벨만 방정식을 다이어그램으로 표현한 것
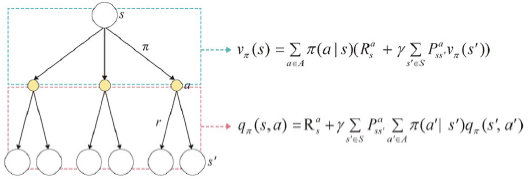
- 상태-가치 함수: 뒤따를 행동-가치 함수의 정책 기반 가중평균
- 행동-가치 함수: 다음 상태-가치 함수의 보상과 상태 전이 확률에 대한 결합 확률의 가중평균
강화학습 과정
Step 1: 처음 에이전트가 접하는 상태 s나 행동 a를 임의의 값으로 설정
Step 2: 환경과 상호 작용하면서 얻은 보상과 상태에 대한 정보를 이용하여 어떤 상태에서 어떤 행동을 취하는 것이 최대의 보상을 얻을 수 있는지 판단
Step 3: 최적의 행동을 판단하는 수단이 상태-가치 함수, 행동-가치 함수이며 벨만 기대 방정식을 이용하여 이를 업데이트하면서 높은 보상을 얻을 수 있는 상태와 행동 학습
Step 4: 최대 보상을 갖는 행동을 선택하도록 최적화된 정책 찾기
벨만 기대 방정식의 의미
: 미래 가치 함수 값을 이용하여 초기화된 임의의 값들을 업데이트하면서 최적의 가치함수로 다가가는 것
벨만 최적 방정식
- 최적의 상태: 강화 학습에서 어떤 목적이 달성된 상태
- 최적화된 정책: 강화 학습 목표에 따라 찾은 정책
- 벨만 최적 방정식: 최적화된 정책을 따르는 벨만 방정식
최적의 가치 함수
: 최대의 보상을 갖는 가치 함수
- 상태-가치 함수
: 어떤 상태가 더 많은 보상을 받을 수 있는지 알려줌 - 행동-가치 함수
: 어떤 상태에서 어떤 행동을 취해야 더 많은 보상을 받을 수 있는지 알려줌 - 최적의 상태-가치 함수
: 주어진 모든 정책에 대한 상태-가치 함수의 최댓값
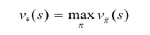
- 최적의 행동-가치 함수
: 주어진 모든 정책에 대한 행동-가치 함수의 최댓값
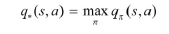
- 행동-가치 함수
- 최적의 가치 함수를 구할 수 있으면 주어진 상태에서 q값이 높은 행동 선택 가능 -> 최적화된 정책 구함(행동-가치 함수를 최대로 하는 행동만 취함)

- 행동-가치 함수
다이나믹 프로그래밍
: 연속적으로 발생되는 문제를 수학적으로 최적화하여 풀어내는 것
- 모든 상황에 대한 것을 이미 알고 있다고 가정하여 계획이 가능
- 예측 과정: MDP와 정책을 입력으로 하여 가치 함수를 찾아내는 것
- 컨트롤 과정: MDP를 입력으로 하여 기존 가치 함수를 더욱 최적화하는 것
정책 이터레이션
- 정책 평가: 현재 정책을 이용해서 가치 함수를 찾는 것
- 모든 상태에 대해 그다음 상태가 될 수 있는 행동에 대한 보상의 합 저장
- 주변 상태의 가치 함수와 바로 다음 상태에서 얻어지는 보상만 고려하여 현재 상태의 다음 가치 함수를 계산하는 것
- 무한 반복하면 특정 값에 수렴, 이 값을 실제 가치 함수 값으로 유추
- 정책 발전: 정책 평가에서의 가치 값과 행동에 대한 가치 값을 비교하여 더 좋은 정책을 찾아가는 과정
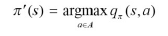
- 욕심쟁이 정책 발전: 에이전트가 할 수 있는 행동들의 행동-가치 함수를 비교, 가장 큰 함수 값을 가진 행동 취하는 것
- 이렇게 정책 업데이트하면 이전 가치 함수에 비해 업데이트된 정책으로 움직였을 때 받을 가치 함수가 무조건 크거나 같음
- 장기적으로 최적화된 정책에 수렴
- 욕심쟁이 정책 발전: 에이전트가 할 수 있는 행동들의 행동-가치 함수를 비교, 가장 큰 함수 값을 가진 행동 취하는 것
가치 이터레이션
: 최적의 정책을 가정하고 벨만 최적 방정식을 이용하여 순차적으로 행동 결정

- 정책 발전이 필요하지 않음
- 한 번의 정책 평가 과정을 거치면 최적의 가치 함수와 최적의 정책이 구해져 MDP 문제를 풀 수 있음
12.4 큐-러닝
큐-러닝
: 큐-함수를 사용하여 최적화된 정책을 학습하는 강화 학습 기법
- 큐-함수: 에이전트가 주어진 상태에서 행동을 취했을 경우 받을 수 있는 보상의 기댓값 예측
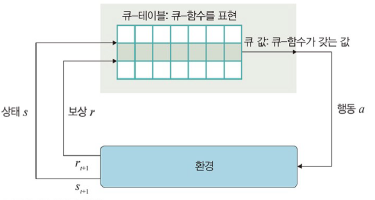
- 여러 실험을 반복하여 최적의 정책을 학습
- 매 실험에서 각 상태마다 행동을 취함. 이때 행동은 랜덤한 선택
- 가보지 않은 곳을 탐험하면서 새로운 좋은 경로를 찾으려고 함
- 0~1 사이로 랜덤하게 난수 추출, 그 값이 특정 임계치보다 낮으면 랜덤하게 행동을 취함
- 임계치는 학습이 진행되면서 점점 낮은 값을 갖음
- 학습이 수만 번 진행되면 임계치는 0에 수렴
- 행동을 취하고, 보상을 받고, 다음 상태를 받아 현재 상태와 행동에 대한 큐 값을 업데이트하는 과정을 무수히 반복
활용과 탐험
- 활용: 현재까지 경험 중 현 상태에서 가장 최대의 보상을 받을 수 있는 행동을 하는 것
- 탐험: 다양한 경험을 쌓기 위한 새로운 시도
- 활용과 탐험 사이의 균형이 필요
- 학습 절차
- Step 1: 초기화
큐 테이블에 있는 모든 큐 값을 0으로 초기화 - Step 2: 행동 a를 선택, 실행
- Step 3: 보상 r과 다음 상태 s' 관찰
- Step 4: 상태 s'에서 가능한 모든 행동에 대해 가장 높은 큐 값을 갖는 행동인 a'를 선택
- Step 5: 큐 값 업데이트

- Rt+1: 현재 상태 s에서 어떤 행동 a를 취했을 때 얻는 즉각적 보상
- maxQ(s', a'): 미래에 보상이 가장 클 행동을 했다고 가정하고 얻은 다음 단계의 가치
- 두번째 항: 목표값
- 첫번째 항: 목표값과 실제 관측치의 차이 -> 이만큼 업데이트 진행
- Step 6: 위 과정 반복
- Step 1: 초기화
단점
- 에이전트가 취할 수 있는 상태 개수가 많은 경우 큐 테이블 구축에 한계가 있음
- 데이터 간 상관관계로 학습이 어려움
딥 큐-러닝
: 합성곱 신경망을 이용하여 큐 함수를 학습하는 강화 학습 기법
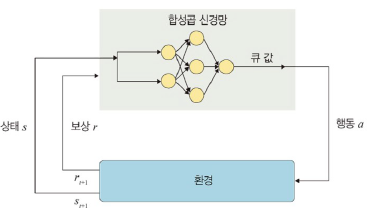
- 큐 러닝 방법의 단점 보완
- 합성곱층을 깊게 하여 훈련할 때 큐 값의 정확도를 높이는 것을 목표로
특징
- 강화 학습을 위한 시뮬레이션 환경 제공
- reset(): 환경 초기화, 초기화될 때는 관찰 변수(상태 관찰 정보)를 함께 반환
- step(): 에이전트에 명령
- 가장 많이 호출됨
- 관찰 변수, 보상 및 게임 종료 여부 등 변수 반환
- render(): 화면에 상태를 표시
- 타깃 큐-네트워크
- 큐 러닝에서 큐 함수가 학습되면서 큐 값이 계속 바뀌는 문제를 해결하기 위해 사용
- 큐-네트워크 위에 별도로 타깃 큐-네트워크를 둠
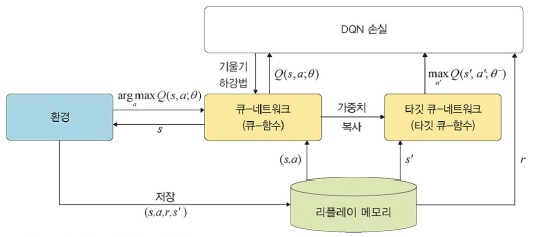
- 주기적으로 한 번씩 업데이트
- 훈련 수행 시 손실 함수로 MSE 사용
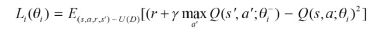
- 리플레이 메모리: 에이전트가 수집한 데이터를 저장해 두는 저장소
- 에이전트 상태가 변경되어도 즉시 훈련시키지 않고 일정 수의 데이터가 수집되는 동안 기다림
- 일정 수의 데이터가 쌓이게 되면 랜덤하게 데이터 추출, 미니 배치를 활용하여 학습(하나의 데이터에 상태, 행동, 보상, 다음 상태 저장)
- 합성곱 신경망을 활용
예제
택시가 승객을 랜덤한 위치에서 태워 목적지까지 이동
- 승객 위치 5개
- 승객 현재 위치 및 목적지 정보 4개
- 에이전트가 취할 수 있는 행동 6개
########## 에이전트 구현
class Agent:
def __init__(self, env, optimizer): # 상태와 행동 초기화
self._state_size = env.observation_space.n
self._action_size = env.action_space.n
self._optimizer = optimizer
self.expirience_replay = deque(maxlen=2000) #과거 행동 기억 초기화
self.gamma = 0.6 # 할인율 초기화
self.epsilon = 0.1 # 탐험 비율 초기화
self.q_network = self.build_compile() # 큐 네트워크 구성
self.target_network = self.build_compile() # 타깃 큐 네트워크 구성
self.target_model()
def store(self, state, action, reward, next_state, terminated):
self.expirience_replay.append((state, action, reward, next_state, terminated))
def build_compile(self): # 네트워크 구성을 위한 함수
model = Sequential()
model.add(Embedding(self._state_size, 10, input_length=1))
model.add(Reshape((10,)))
model.add(Dense(50, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(self._action_size, activation='linear'))
model.compile(loss='mse', optimizer=self._optimizer)
return model
def target_model(self): # 가중치 적용하기 위한 함수
self.target_network.set_weights(self.q_network.get_weights())
def act(self, state): # 탐험을 위한 함수
if np.random.rand() <= self.epsilon: # 탐험(이동방향) 결정하는 방법: 임의의 랜덤 값을 선택하여 행동을 취하는 방법 선택
return env.action_space.sample()
q_values = self.q_network.predict(state)
return np.argmax(q_values[0])
def retrain(self, batch_size): # 큐 네트워크 훈련에 대한 함수
minibatch = random.sample(self.expirience_replay, batch_size) # 리플레이 메모리에서 랜덤한 데이터 선택
for state, action, reward, next_state, terminated in minibatch:
target = self.q_network.predict(state)
if terminated:
target[0][action] = reward
else:
t = self.target_network.predict(next_state)
target[0][action] = reward + self.gamma * np.amax(t)
self.q_network.fit(state, target, epochs=1, verbose=0) # 큐 네트워크 훈련
########## 훈련 준비
optimizer = Adam(learning_rate=0.01)
agent = Agent(env, optimizer)
batch_size = 32
num_of_episodes = 10
timesteps_per_episode = 10
agent.q_network.summary()
########## 모델 훈련
for e in range(0, num_of_episodes):
state = env.reset() # 환경 재설정
state = np.reshape(state, [1, 1])
reward = 0 # 보상 변수 초기화
terminated = False
for timestep in range(timesteps_per_episode):
action = agent.act(state)
next_state, reward, terminated, info = env.step(action) # 에이전트가 단계별 행동을 취함
next_state = np.reshape(next_state, [1, 1])
agent.store(state, action, reward, next_state, terminated)
state = next_state
if terminated:
agent.target_model()
break
if len(agent.expirience_replay) > batch_size:
agent.retrain(batch_size)
if (e + 1) % 10 == 0:
print("**********************************")
print("Episode: {}".format(e + 1))
env.render()
print("**********************************") 12.5 몬테카를로 트리 탐색
몬테카를로 트리 탐색 원리
: 모든 트리 노드를 대상으로 탐색하는 대신 게임 시뮬레이션을 이용하여 가장 가능성이 높아 보이는 방향으로 행동 결정하는 탐색 방법
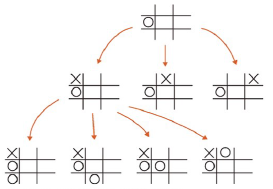
- 경우의 수가 많을 때 무작위 방법 중 가장 승률이 높은 값을 기반으로 시도
- 학습 과정

- Step 1: 선택
루트 R에서 시작, 현재까지 펼쳐진 트리 중 가장 승산 있는 자식 노드 L 선택

- Step 2: 확장
노드 L에서 게임이 종료되지 않으면 자식 노드를 생성, 그 중 하나의 노드 C 선택 - Step 3: 시뮬레이션
노드 C에서 랜덤으로 자식 노드 선택, 게임 반복 진행 - Step 4: 역전파
시뮬레이션 결과, C, L, R 값 업데이트
- Step 1: 선택
- 트리에서 랜덤 시뮬레이션을 이용하여 최적의 선택 결정
- ex. 알파고, 보드게임, 실시간 비디오 게임, 포커
몬테카를로 트리 검색을 적용한 틱택토 게임 구현
비어있는 보드 생성 후 플레이어에게서 입력을 받아 승리 조건 확인하고 승자를 선언하거나, 전체 보드가 채워졌음에도 아무도 이기지 않으면 결과 동점으로 선언
########## 보드 생성
boarder = {'1': ' ' , '2': ' ' , '3': ' ' ,
'4': ' ' , '5': ' ' , '6': ' ' ,
'7': ' ' , '8': ' ' , '9': ' ' }
board_keys = []
for key in boarder:
board_keys.append(key)
########## 화면 출력 함수 정의
def visual_Board(board_num):
print(board_num['1'] + '|' + board_num['2'] + '|' + board_num['3'])
print('-+-+-')
print(board_num['4'] + '|' + board_num['5'] + '|' + board_num['6'])
print('-+-+-')
print(board_num['7'] + '|' + board_num['8'] + '|' + board_num['9'])
########## 보드 이동 함수 정의
def game():
turn = 'X'
count = 0
for i in range(8):
visual_Board(boarder)
print("당신 차례입니다," + turn + ". 어디로 이동할까요?")
move = input()
if boarder[move] == ' ':
boarder[move] = turn
count += 1
else:
print("이미 채워져있습니다.\n어디로 이동할까요?")
continue
if count >= 5: # 플레이어가 다섯 번 이동 후 이겼는지 확인
if boarder['1'] == boarder['2'] == boarder['3'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['4'] == boarder['5'] == boarder['6'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['7'] == boarder['8'] == boarder['9'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['1'] == boarder['4'] == boarder['7'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['2'] == boarder['5'] == boarder['8'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['3'] == boarder['6'] == boarder['9'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['1'] == boarder['5'] == boarder['9'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
elif boarder['3'] == boarder['5'] == boarder['7'] != ' ':
visual_Board(boarder)
print("\n게임 종료.\n")
print(" ---------- " +turn + "가 승리했습니다. -----------")
break
if count == 9: # 동점인 경우
print("\n게임 종료.\n")
print("동점입니다")
if turn =='X': # 움직임이 있을 때마다 플레이어 변경
turn = 'Y'
else:
turn = 'X'
if __name__ == "__main__":
game()
너무 유익한 내용이네요~