
11.1 클러스터링이란
: 특성이 비슷한 데이터끼리 묶어 주는 머신러닝 기법. 딥러닝을 적용한다면 성능 향상 가능
11.2 클러스터링 알고리즘 유형
K-평균 군집화
원리
Step 1: 군집화의 기준이 되는 중심을 구성하려는 군집 개수만큼 정함(임의의 점 K개)
Step 2: 각 데이터는 가장 가까운 곳에 위치한 중심점의 클러스터에 할당
Step 3: 소속이 결정되면 군집 중심점을 소속된 데이터의 평균 중심으로 이동함
Step 4: 클러스터 할당이 변경되지 않을 때까지 반봅
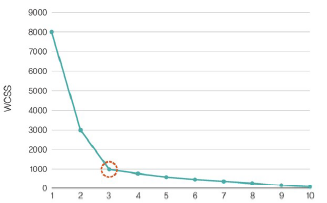
WCSS(Within Cluster Sum of Square)
: 모든 클러스터에 있는 각 데이터가 중심까지의 거리를 제곱하여 합을 게산한 것

- 이를 최소화하는 것이 이상적
- elbow graph를 사용하여 찾음
딥러닝이 적용된 K-평균 군집화 에제
# 특성 추출
model = tf.keras.applications.MobileNetV2(include_top=False, weights='imagenet', input_shape=(224, 224, 3))
predictions = model.predict(images.reshape(-1, 224, 224, 3))
pred_images = predictions.reshape(images.shape[0], -1)
# 클러스터링 구성
k = 2
kmodel = KMeans(n_clusters=k, n_jobs=-1, random_state=728)
kmodel.fit(pred_images)
kpredictions = kmodel.predict(pred_images)
shutil.rmtree('../chap11/data/output')
for i in range(k):
os.makedirs("../chap11/data/output" + str(i))
for i in range(len(paths)):
shutil.copy2(paths[i], "../chap11/data/output"+str(kpredictions[i]))
# 실루엣 계수로 K값 결정
sil = []
kl = []
kmax = 10
for k in range(2, kmax+1):
kmeans2 = KMeans(n_clusters = k).fit(pred_images)
labels = kmeans2.labels_
sil.append(silhouette_score(pred_images, labels, metric = 'euclidean'))
kl.append(k)
plt.plot(kl, sil)
plt.ylabel('Silhoutte Score')
plt.ylabel('K')
plt.show() 가우시안 혼합 모델
: 가우시안 분포가 여러 개 혼합된 클러스터링 알고리즘

- 현실의 복잡한 형태의 확률 분포를 가우시안 분포 K개를 혼합하여 표현
- K: 하이퍼파라미터
가우시안 혼합 모델을 이용한 분류
: 주어진 데이터 xn에 대해 이 데이터가 어떤 가우시안 분포에 속하는지 찾는 것

- znk = 1: xn이 K번째 가우시안 분포에 속함
znk = 0: xn이 K번째 가우시안 분포에 속하지 않음 - K개의 γ(znk)를 계산해서 가장 높은 값의 가우시안 분포를 선택
- πk: zk=1일 때 사전확률 값
- γ(znk): 관찰 데이터 x가 주어졌을 때의 사후 확률 값(or 성분 K에 대한 책임 값)
모델 구현
from sklearn.mixture import GaussianMixture
# GMM 생성
gmm = GaussianMixture(n_components=2) # n_components: 가우시안 개수
gmm.fit(X_train)
print(gmm.means_)
print('\n')
print(gmm.covariances_)
X, Y = np.meshgrid(np.linspace(-1, 6), np.linspace(-1,6))
XX = np.array([X.ravel(), Y.ravel()]).T
Z = gmm.score_samples(XX)
Z = Z.reshape((50,50))
plt.contour(X, Y, Z)
plt.scatter(X_train[:, 0], X_train[:, 1])
plt.show()자기 조직화 지도(SOM)
: 신경 생리학적 시스템을 모델링한 것으로, 입력 패턴에 대해 정확한 정답을 주지 않고 스스로 학습하여 클러스터링하는 알고리즘
구조
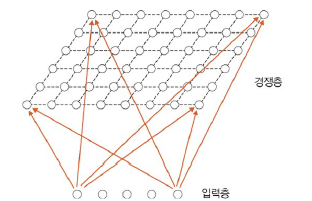
- 입력층과 경쟁층(2차원 격자로 구성)
- 가중치: 연결 강도, 0~1 사이의 정규화된 값 사용
진행 과정
Step 1: 초기화
- 모든 연결 가중치는 작은 임의의 값으로 초기화
Step 2: 경쟁
- 경쟁 학습을 이용하여 입력층과 경쟁층 연결
- 승자 독점 방식: 연결 강도 벡터가 입력 벡터와 얼마나 가까운지 계산하여 가장 가까운 뉴런이 승리

- d 값이 작을수록 가까운 노드
- 연결 강도는 아래 식을 사용하여 새로운 값으로 업데이트

- 연결 강도 벡터와 입력 벡터가 가자 ㅇ가까운 뉴런으로 계산되면 그 뉴런의 이웃 뉴런들도 학습(제한된 만큼의 뉴런만 학습)
Step 3: 협력
- 승자 뉴런은 네트워크 토폴로지에서 가장 좋은 공간 위치를 차지, 승자와 함께 학습할 이웃 크기를 정의
Step 4: 적응
- 승리한 뉴런의 가중치와 이웃 뉴런 업데이트
Step 5: 원하는 횟수만큼 위 과정 반복

구현
from minisom import MiniSom
from pylab import plot,axis,show,pcolor,colorbar,bone
# MiniSom 알고리즘 적용
som = MiniSom(16,16,64,sigma=1.0,learning_rate=0.5)
som.random_weights_init(data)
print("SOM 초기화.")
som.train_random(data,10000)
print("\n. SOM 진행 종료")
bone()
pcolor(som.distance_map().T)
colorbar()MiniSom
- 16 = x축에 대한 차원
- 16 = y축에 대한 차원
- 64 = 입력 벡터 개수
- sigma = 이웃 노드와의 인접 반경

- learning_rate: 한 번 학습할 때 얼마만큼의 변화를 주는지에 대한 상수

labels[labels == '0'] = 0
labels[labels == '1'] = 1
labels[labels == '2'] = 2
labels[labels == '3'] = 3
labels[labels == '4'] = 4
labels[labels == '5'] = 5
labels[labels == '6'] = 6
labels[labels == '7'] = 7
labels[labels == '8'] = 8
labels[labels == '9'] = 9
markers = ['o', 'v', '1', '3', '8', 's', 'p', 'x', 'D', '*']
colors = ["r", "g", "b", "y", "c", (0,0.1,0.8), (1,0.5,0), (1,1,0.3), "m", (0.4,0.6,0)]
for cnt,xx in enumerate(data):
w = som.winner(xx) # 승자 노드 식별
# MiniSom 알고리즘을 이용하여 모든 가중치 벡터의 데이터 공간에서 유클리드 거리를 측정하여 승자 식별
plot(w[0]+.5,w[1]+.5,markers[labels[cnt]],
markerfacecolor='None', markeredgecolor=colors[labels[cnt]],
markersize=12, markeredgewidth=2)
show()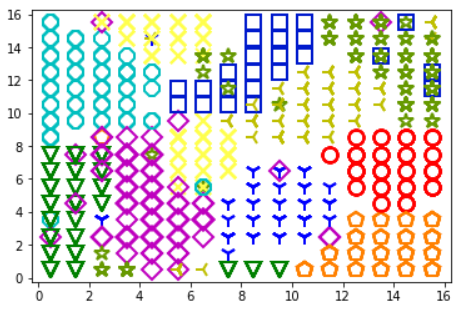

Data Analyst | Statistics