우리의 최종목표
Word2Vec: objective function with negative sampling
Word2Vec의 Objective function는 전체 코퍼스(document)의 모든 단어에 대한 평균 손실을 최소화 하는 것
: 전체 문서(copus)에 등장하는 단어 수 = total tokens
: 윈도우 크기
: 중심 단어–주변 단어 쌍에 대한 개별 loss
Word2Vec 모델은 단어 임베딩을 학습하기 위해 모든 (center word, context word) 쌍이 의미적으로 가까운 관계를 가지도록 학습한다.
= 중심 단어 와 실제 주변 단어 의 내적 는 크게 만들고 & 중심 단어 와 무관한 단어(negative samples) 들의 내적 는 작게 만든다.
이 때 k개의 negative samples를 만들 때에는 unigram distribution를 이용한다.
값을 작게 만드는 방향으로 학습한다.
파라미터 최적화
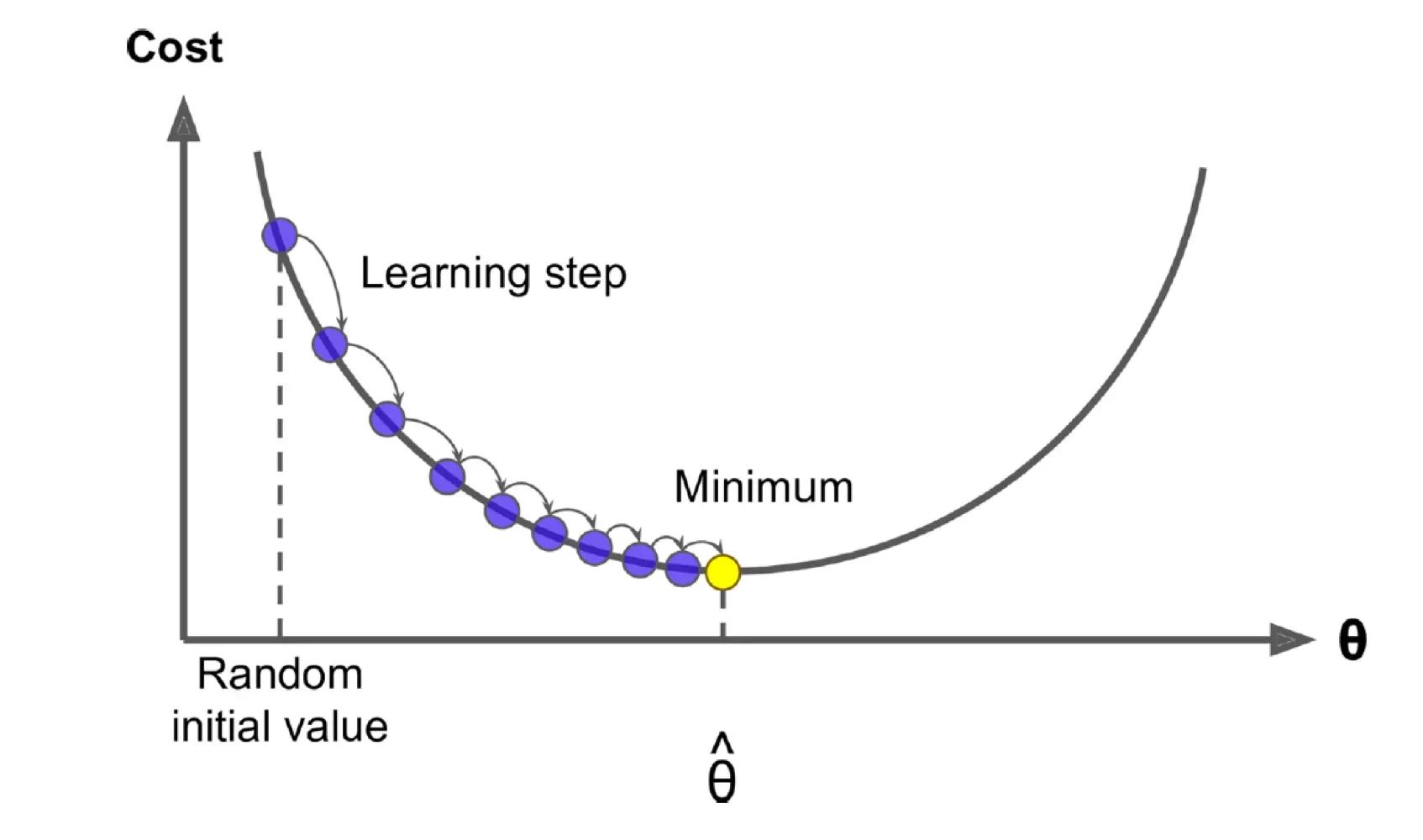
Optimization: Gradient Descent
를 최적화하기 위해 Gradient Desent 방법을 사용한다. → 모든 벡터의 gradient를 계산해야한다.
모델이 cost function 를 줄이는 방향으로 조금씩 이동하면서 벡터를 업데이트
현재 파라미터 값 에 대해 의 기울기를 계산하고 그 기울기의 반대 방향으로 아주 조금 이동하고 이 과정을 반복한다.
| 기호 | 의미 |
|---|---|
| 현재 파라미터 (현재 단어 벡터, 가중치 등) | |
| 업데이트 후 새로운 파라미터 | |
| 손실 함수 | |
| 손실이 가장 빠르게 증가하는 방향과 증가하는 정도를 나타내는 벡터 (gradient) | |
| 손실이 가장 빠르게 감소하는 방향 | |
| 학습률 (learning rate, step size) — 한 번에 얼마나 이동할지 조절하는 상수 |
Stochastic Gradient Descent (SGD)
문제: corpus의 모든 window에 대해 그 수가 매우 많다면 의 기울기를 한 번 계산 하는데도 엄청난 연산량이 발생한다.
해결:
SGD(확률적 경사 하강법) -”하나의 단어쌍만 본다!”
전체 데이터 대신 하나의 window (=sample) 만 랜덤하게 뽑아 그 sample 에 대한 기울기만 계산하고 바로 업데이트한다.
Mini Batch Gradient Descent - “5명 정도 묶어서 본다!”
한 번에 하나의 window가 아니라 작은 묶음(batch) 의 windows를 사용해서 평균 기울기를 구하여 업데이트한다.
Example
The cat sits on the mat.
여기서 중심 단어 “cat” 볼 차례라고 하자 주변 단를 “the”, “sits”, “on” 으로 둡니다.
→ 우리가 학습할 하나의 window는
-
일반 Gradient Descent (배치 학습) : corpus 전체의 모든 window를 보고 나서 딱 한 번 업데이트한다.
-
The cat sits on the mat.
-
The dog sits on the rug.
-
The bird flies over the tree.
…
이 모든 문장에서 가능한 윈도우들을 다 뽑으면 10만 개쯤 된다고 하면
- 모든 윈도우 10만 개에 대해 확률 를 계산하고
- 전체 손실 의 평균을 구하고
- gradient를 한 번 계산한 뒤 → 단 한 번 를 업데이트.
2. SGD (Stochastic Gradient Descent, 확률적 경사하강법) : 모든 윈도우를 기다리지 말고 하나의 윈도우만 보고 바로 업데이트한다.
- 전체 윈도우 중 하나를 랜덤하게 뽑는다.
- 이 윈도우를 선택했다고 하면
- 이 하나만 가지고 손실을 계산한다.
- 그다음 바로 벡터를 업데이트 한다.
이 과정을 window 전체를 다 볼 때까지 매번 랜덤하게 하나씩 선택해서 반복한다.
매 스텝에서 빠르게 업데이트되므로 매우 빠른 학습 BUT 각 윈도우가 랜덤이기 때문에 학습 그래프가 진동하면서 감소한다.
흥미롭게도 신경망 분야에서는 시스템에 노이즈를 주입하는 것이 최적화에 도움이 되어 SGD가 실제로 더 잘 작동하는 경향이 있다.
- Mini-Batch Gradient Descent (미니배치 경사하강법)
하나만 보긴 불안정하고 전부 보긴 너무 느리고 적당히 여러 개를 한 묶음으로 보고 업데이트한다.
barch size를 3으로 한다면
| Batch | 포함된 윈도우들 |
|---|---|
| Batch 1 | (cat, the), (dog, sits), (bird, flies) |
| Batch 2 | (cat, sits), (dog, on), (bird, tree) |
| … | … |
- 각 윈도우별 손실 계산
- 평균을 내서 하나의 “평균 기울기” 계산
- 그 평균 기울기로 파라미터 업데이트
Stochastic gradients with negative sampling
각 window마다 SGD를 사용할때 반복적으로 gradient들을 구한다.
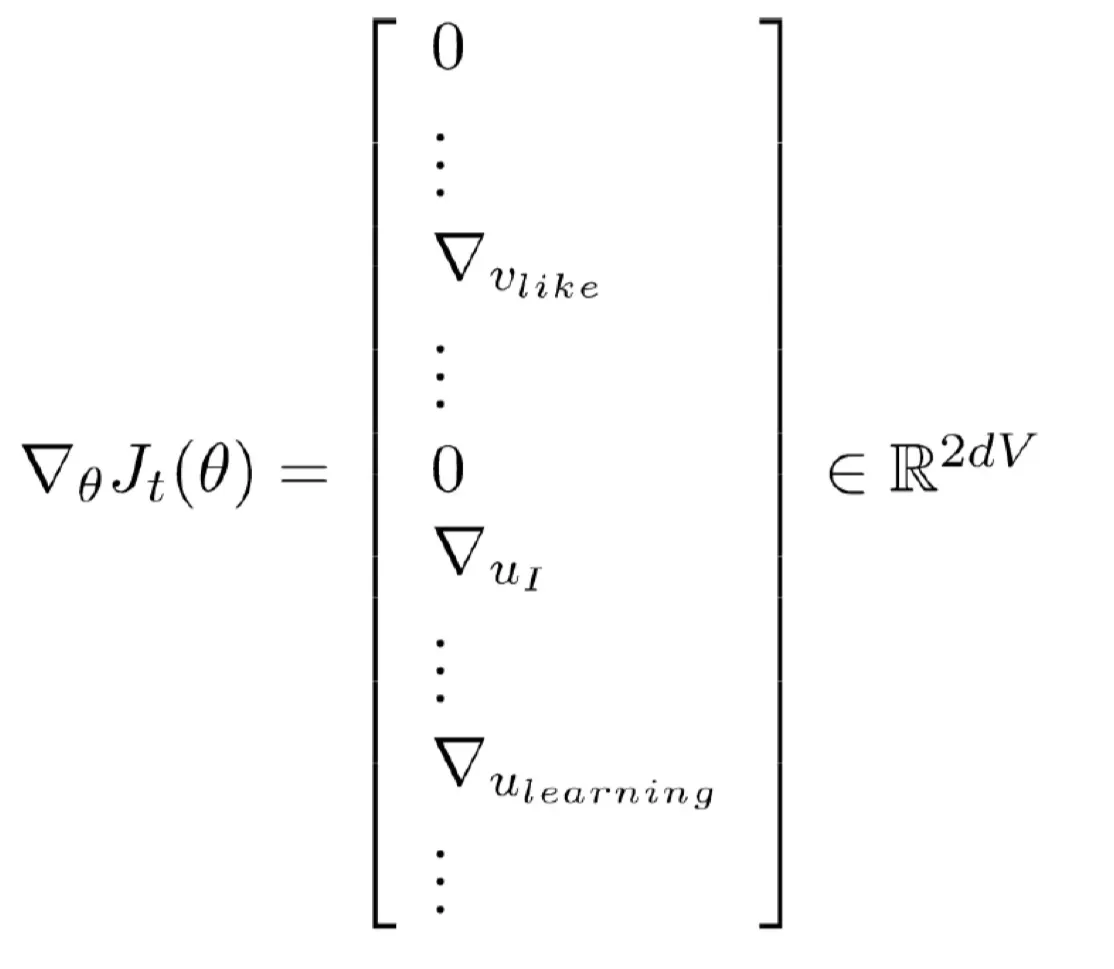
각 윈도우에서 우리는 2+1 (context 안에 있는 word, 은 window size) + 2 (outside word 하나 볼때 k개의 negative words 같이 봄) 개의 단어들만 업데이트한다.
문장 전체를 한 번에 학습하는 게 아니라 window로 나눠서 학습하므로 전체 데이터가 아니라 일부 샘플만 보고 업데이트한다. 한 번의 학습에 쓰이는 단어는 아주 일부 !
→ 전체 단어 V개 중 2m+1+2km개의 단어만 gradient를 가지고 나머지 단어는 이번 step에서 업데이트 되지않는다.
벡터는 대부분이 0 이고 일부단어만 gradient값이 존재하므로 매우 sparse한 백터임
Problem: window에 등장한 단어들의 임베딩 벡터만 업데이트하고 나머지 단어들의 벡터는 그대로 두는 것이 훨씬 효율적일 것
Solution:
-
두 행 U(outside words), V(center words)의 일부 행만 업데이트한다. - 희소 행렬 연산
전체 행렬 업데이트 대신 해당 단어의 인덱스(row)에 해당하는 부분만 계산해서 바꾼다.
-
단어 벡터를 hash 자료구조로 관리해야한다.
hash 는 key-value 쌍으로 데이터를 저장하는 구조 ( ex: { "bank": [0.13, -0.21, 0.78, ...] } )
행렬 전체를 다루는 대신 등장한 단어들만 빠르게 접근할 수 있도록 (단어 : 벡터) 형태의 해시맵으로 관리