NLP
1.[NLP] Word2Vec- Skipgram (1)

왜 wordvector가 필요한가 ? Representing words as discrete symbols 전통적인 NLP에서는 words를 discrete symbol로 표현한다. 다음은 두 단어를 one-hot vector로 표현한 symbols motel=
2025년 12월 16일
2.[NLP] Word2Vec- Skipgram (2)
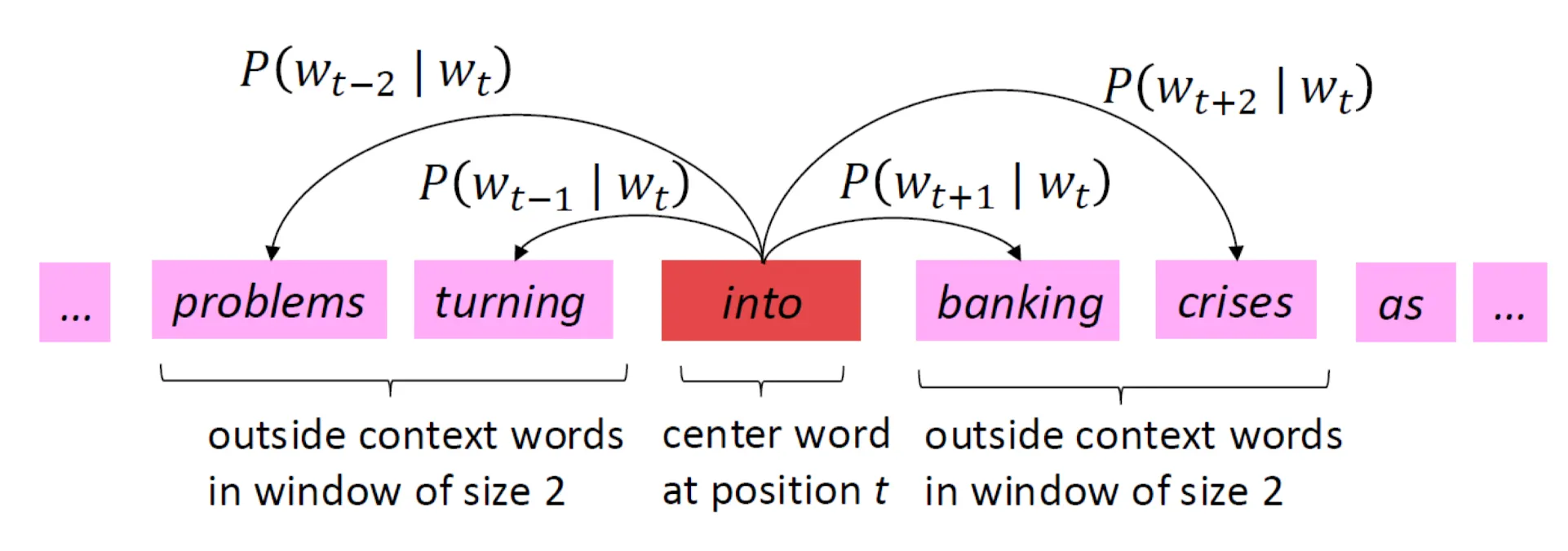
context word $w\_{t+j}$ 가 center word $w_t$의 context에 나타날 확률이다.모델이 실제 학습하는 확률은 중심단어가 주어졌을 때 그 주변 단어들이 함께 등장할 확률을 최대화하는 것이다.이 확률은 어떻게 구할까 ??Conditional
2025년 12월 16일
3.[NLP] Word2Vec- Skipgram (3)
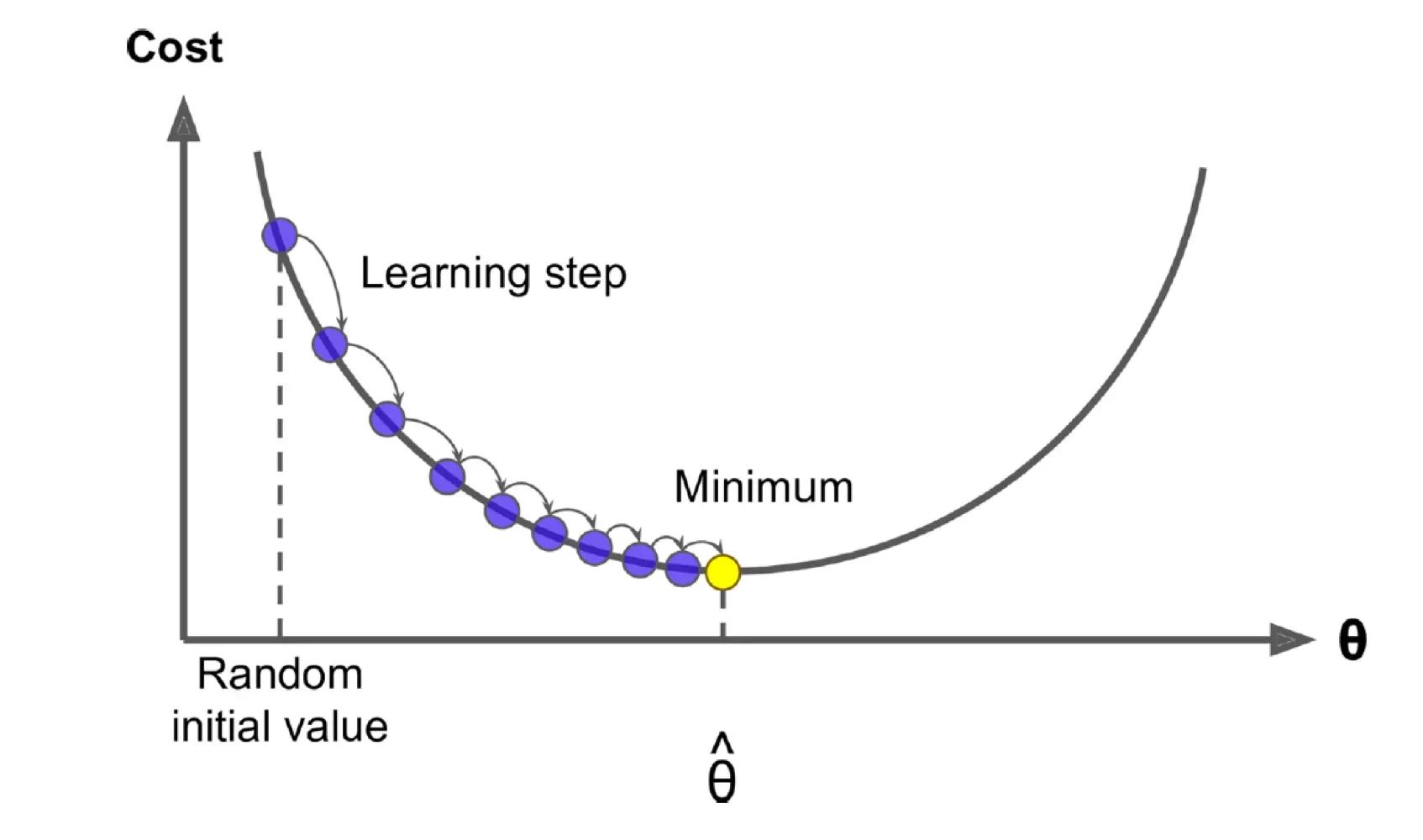
$\\theta$를 최적화하기 위해 Gradient Desent 방법을 사용한다. → 모든 벡터의 gradient를 계산해야한다.모델이 cost function $J(\\theta)$를 줄이는 방향으로 조금씩 이동하면서 벡터를 업데이트현재 파라미터 값 $\\theta
2025년 12월 16일
4.[NLP] Word2Vec- Skipgram 코드

주어지는 것A collection of documents (str objects)해야할 것문서를 단어 단위로 쪼개기 → tokens_list각 문서 문자열을 단어 단위로 나눈다.Generate a list of tokens for each document- 토큰 목록
2025년 12월 17일