어떻게 학습하여 WordVector를 만들까 ?
의 의미
context word 가 center word 의 context에 나타날 확률이다.
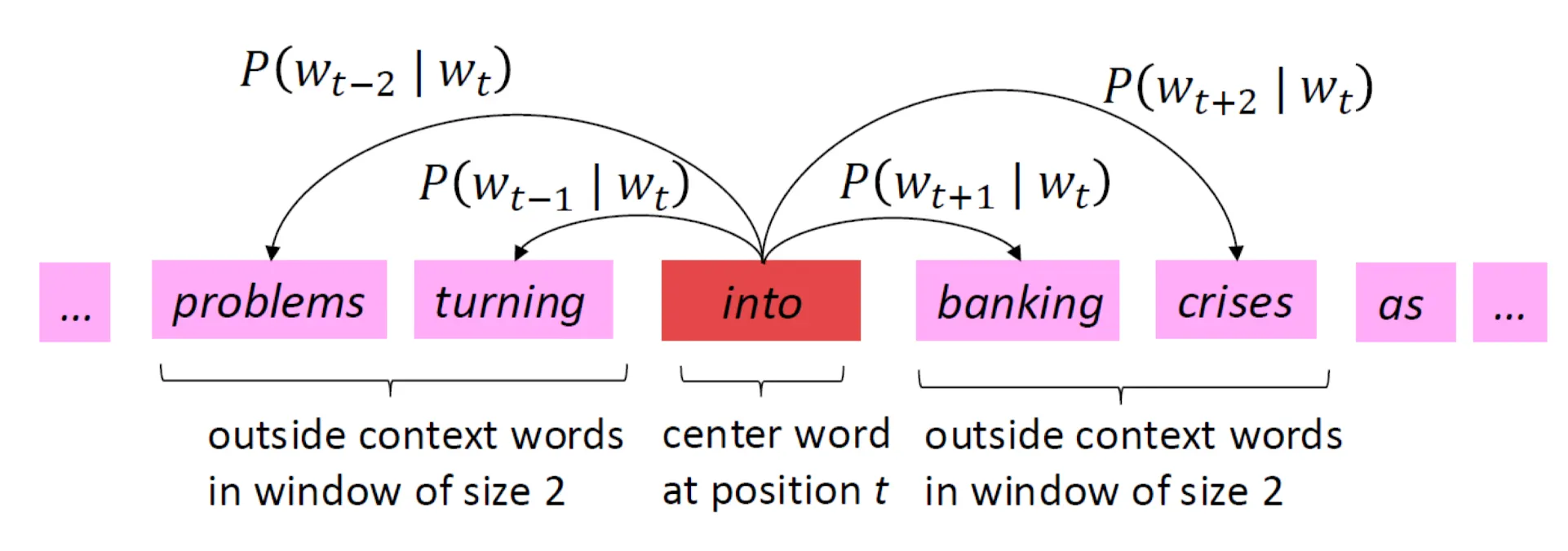
모델이 실제 학습하는 확률은 중심단어가 주어졌을 때 그 주변 단어들이 함께 등장할 확률을 최대화하는 것이다.
이 확률은 어떻게 구할까 ??
Conditional Independence Assumption(조건부 독립 가정)을 사용 → 주변 단어들이 서로에게 영향을 주지 않고 독립적으로 등장한다.
이렇게 개별 확률들을 곱해서 주변 단어들이 함께 등장할 확률을 계산한다.
Word2Vec: objective function
window of fixed size , center word , 각 위치 에서 context words를 예측한다.
→ 여기서 목적함수는 Datalikehood를 최대화 하는 것이다.
| 기호 | 의미 |
|---|---|
| 모델 파라미터 θ가 주어졌을 때, 전체 데이터의 likelihood | |
| 말뭉치의 모든 위치 t (모든 중심 단어)에 대해 곱함 | |
| 각 중심 단어 주위의 “윈도우 크기 m” 내 모든 주변 단어들에 대해 곱함 | |
| 중심 단어 가 주어졌을 때, 주변 단어 가 등장할 확률 (θ로 계산됨) |
주변 단어 확률의 곱을 최대화하는 대신 로그를 취한 후(곱셈 → 덧셈) 음의 평균 로그 우도를 최소화하는 형태로 변환하여 경사 하강법 기반 학습을 가능하게 한다.
여기서 가 의미하는 것은 ?
모델의 학습 파라미터 → 단어 벡터 자체를 포함한 모든 가중치를 의미한다.
: 입력층에서의 단어 벡터 (center word vector)
: 출력층에서의 단어 벡터 (context word vector)
: 어휘집(vocabulary)
은 어떻게 구할까 ?
Word2Vec: prediction function
중심 단어 c 가 주어졌을 때 특정 단어 o 가 주변 단어로 등장할 개별 확률 → 두 단어 벡터 간 유사도 (내적)을 이용하여 계산
-
두 단어 벡터 간 유사도 계산
→ 중심 단어와 주변 단어 벡터가 비슷할수록 값이 크다.
-
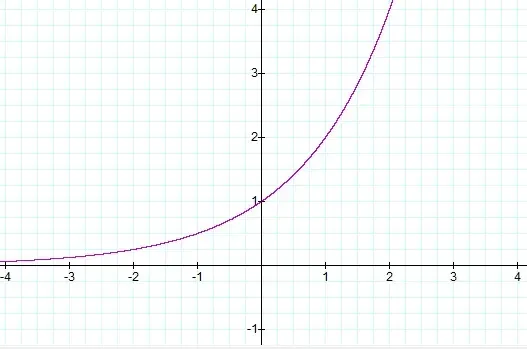
지수화 (exp)
→ 유사도를 양수로 만들고 값이 클수록 확률이 기하급수적으로 커지게 만들어 강조한다.
음수(= 낮은 유사도) → 0에 가까운 작은 값
큰 양수(= 높은 유사도) → 매우 큰 값
-
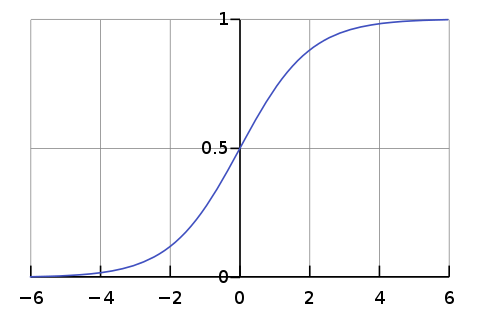
정규화 (Softmax)
→ 전체 단어의 지수합으로 나누어 모든 단어 확률의 합이 1이 되게 한다.
입력값들이 아무리 크거나 작아도 결과는 항상 (0, 1) 사이의 값으로 바뀌고 전체의 합은 1이 된다.
“Max” → 큰 값을 더욱 극대화시켜 주는 역할
“Soft” → 하지만 가장 작은 값들에게도 조금의 확률을 남겨줌 (↔ hard max는 1과 0으로 나눔)
💡 모델을 학습한다는 건 결국 loss 를 minimize 하게 하도록 parameter 를 최적화하는 과정이다. 여기서 전체의 파라미터를 하나의 긴 벡터 로 표현한다.
V개의 단어에 대하여 각각 D 차원의 벡터로 표현을 하고 각 단어마다 2개의 벡터를 가지므로 모델이 학습해야할 파라미터의 개수 즉 의 dimensionality =
** |V|= 어휘집 크기, D= 임베딩 차원
왜 2개의 벡터를 가질까 ?
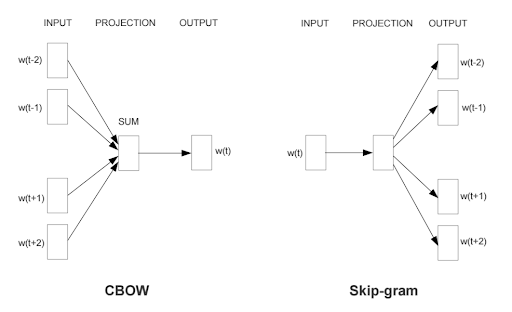
Two model variants
각 단어는 두개의 벡터를 가진다. (Input 벡터와 output 벡터)
더 쉽게 학습을 optimization하기 위해서 !! 훈련 후에는 두 벡터의 평균을 쓴다.
-
Skip-grams (SG)
중심 단어로부터 주변 단어를 예측하는 모델
Input: center word (ex: dog)
Output: context words (ex: barks, runs, tail)
-
Continuous Bag of Words (CBOW)
주변 단어들로부터 중심 단어를 예측하는 모델
Input: context words (ex: barks, runs, tail)
Output: center word (ex: dog)
계산 과정
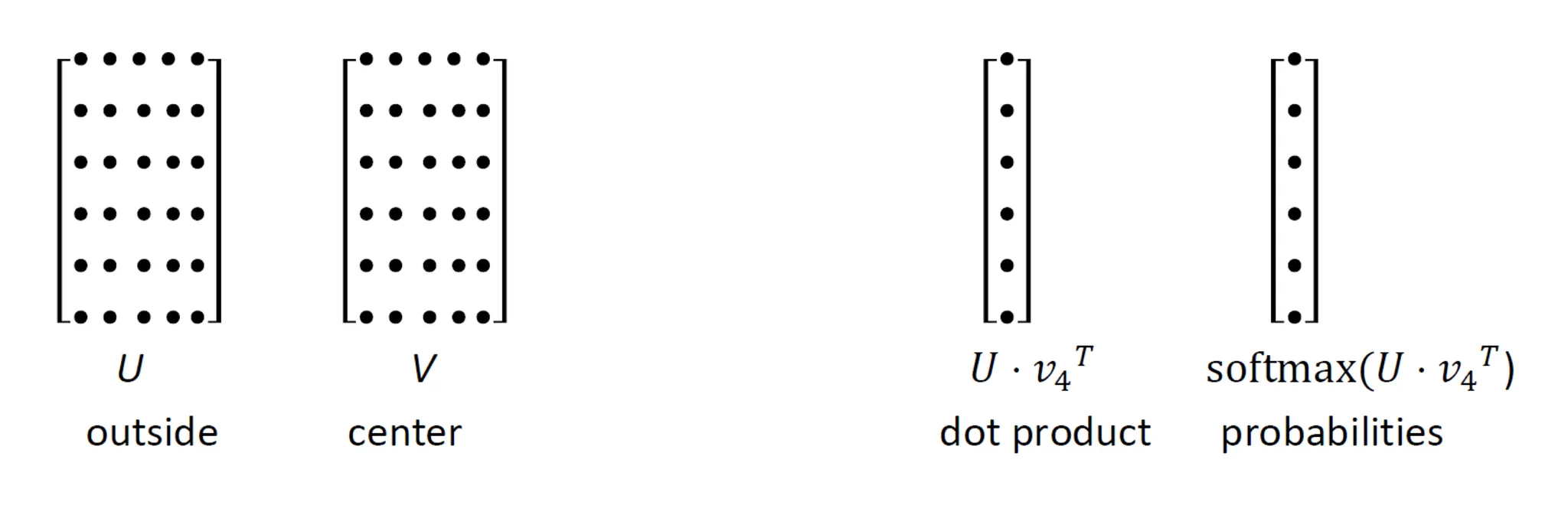
Center–Context Probability Computation Visualization
-
임베딩 행렬 2개: U 와 V
기호 의미 U outside words (문맥 단어)의 임베딩 행렬 V center words (중심 단어)의 임베딩 행렬 각각의 행은 하나의 단어에 해당하는 임베딩 벡터
ex)
V[bank] = v_bank,U[money] = u_moneyWord2Vec에서는 중심 단어와 주변 단어에 대해 따로 임베딩을 가짐 → 그래서 U와 V는 다름
단어가 문장에서 두 가지 역할 : “내가 중심일 때”의 의미 & “내가 주변일 때”의 의미
-
중심 단어의 임베딩 선택
중심 단어가 예를 들어 4번째 단어라면, v₄ 벡터 (V의 4번째 행)를 선택함 → 이 벡터는 center word vector로 사용됨
-
U · v₄ᵀ (dot product)
V의 중심 단어 벡터 v₄와 U의 모든 행들(= 모든 outside word vector)을 내적 → 결과는 "모든 **단어별 **점수 **벡터"**
ex) “bank”라는 단어가 각 단어(u₁, u₂, …)와 얼마나 관련이 있는지를 점수로 계산 → 점수가 높을수록, 그 단어는 “bank”의 주변에 등장할 확률이 높습니다.
-
Softmax 적용
softmax(U · v₄ᵀ) = 모든 단어에 대해 확률로 변환 → v₄가 중심단어일 때 U에서 각 단어가 context에 **나올 **확률
Word2vec의 손실함수
Loss functions for taining
-
Naïve softmax
간단하지만 분모에서 모든 단어 (V개)에 대해 확률을 계산해서 너무 expensive한 연산
-
Hierarchical softmax
트리 구조를 활용해서 트리의 루트에서 정답으로 가는 경로만 계산하도록함
-
Negative Sampling
실제로 같은 context에 등장한 중심단어, 주변단어 쌍 (ex: bank, money)을 true pair 로 구분하고
중심단어와 무작위로 뽑은 단어들을 noise pair 로 구분하도록 binary logistic regression(이진 로지스틱 회귀)를 학습시키는 것
Negative Sampling
true pair → 모델이 이 두 단어의 벡터 내적 값을 크게 만들어야한다.
noise pair → 모델이 이 쌍의 내적 값을 작게 만들어야한다.
이렇게하면 Softmax 분모의 모든 단어를 계산할 필요 없어서 훨씬 빠름 !!
- 단어의 출현 확률을 기반으로 k개의 ”negative samples” 을 뽑는다.
- 실제 주변 단어가 등장할 확률은 최대화 무작위 단어가 등장할 확률은 최소화한다.
- 다음 Lossfunction을 최소화한다.
: 실제 주변 단어(outside word)의 벡터
: 중심 단어(center word)의 벡터
: 무작위로 선택된 부정 샘플 단어(noise words)의 벡터
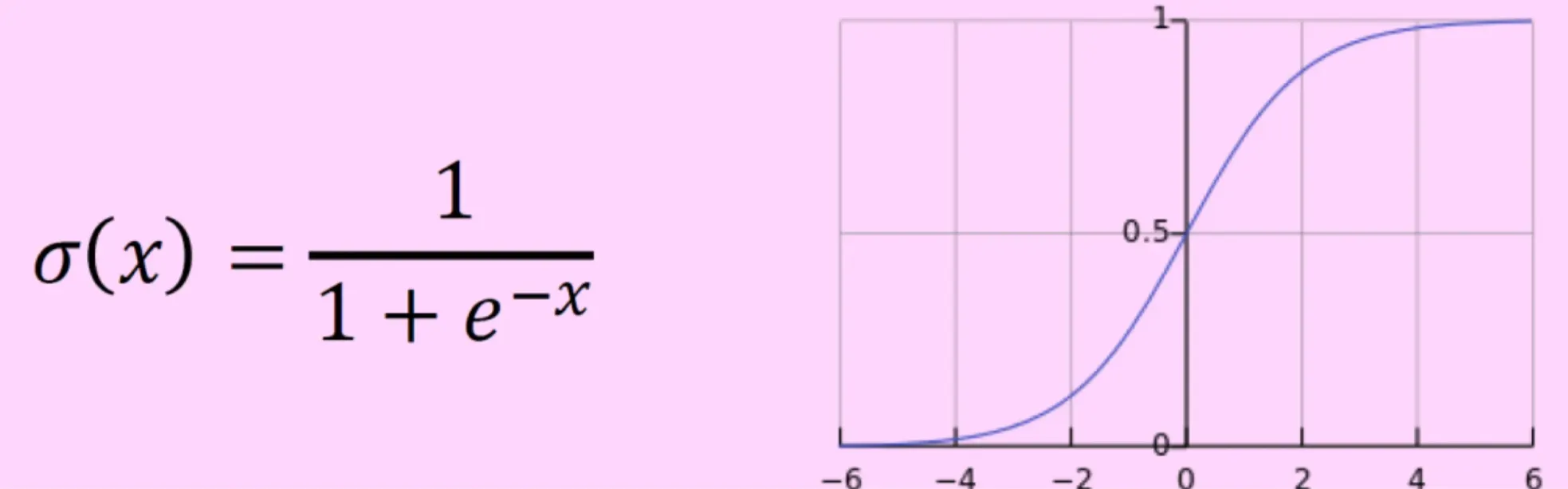
: 시그모이드(sigmoid) 함수
첫 항(-)은 진짜 단어 쌍이 진짜(1)라고 예측하도록 함 → 가 클수록 값이 1에 가까워짐
두 번째 항(-)은 가짜 단어 쌍은 가짜(0)라고 예측하도록 함 → 가 작을수록 값이 1에 가까워짐
즉 각 중심단어에 대해 실제 문맥 단어 1개, 랜덤하게 뽑은 단어 k개를 비교한다.
Unigram distribution
negative samples을 뽑을 때 모든 단어가 동일 확률로 뽑히면 너무 자주 등장하는 단어 (ex: the, a)가 너무 자주 선택됨
→ 자주 나오는 단어는 덜 자주, 희귀 단어는 좀 더 자주 샘플되게 조정하는 분포이다.
: 단어의 빈도 확률
3/4: 경험적으로 가장 효율적인 지수
: 정규화 상수
