왜 wordvector가 필요한가 ?
Representing words as discrete symbols
전통적인 NLP에서는 words를 discrete symbol로 표현한다.
다음은 두 단어를 one-hot vector로 표현한 symbols
motel= [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel= [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
여기서 vector의 dimension은 number of words in vocabulary
예를 들어 전체 단어 수가 10만 개라면 10만 개의 차원을 가진 벡터에서 “motel”에 해당하는 위치만 1이고 나머지는 0인 벡터가 됨
Problem with words as discrete symbols
이러한 방식의 문제점은 단어 간의 유사성을 파악하기가 힘들다.
예를 들면 만약 유저가 “Seattle motel”을 검색했다면 우리는 “Seattle hotel”을 포함한 문서들을 매칭시켜줘야한다.
그러나 one-hot vector 로 표현된 저 두 벡터는 완전히 다른 벡터가 된다.
왜냐하면 벡터 내적을 계산하면 0이 되어 두 단어는 수학적으로 전혀 관련이 없는 “orthogonal”인 상태가 된다.
** 내적- 같은 차원에 있는 성분의 곱으로 내적 값이 클수록 유사도가 높다고 판단함
Solution
Representing words by their context
Distributional semantics(분포 의미론): 단어의 의미는 그 단어와 함께 자주 나타나는 주변 단어들에 의해 결정된다.
텍스트에서 라는 단어가 나타날 때 fixed-size window 안에 함께 나타나는 단어들을 의 context 라고 한다.
이처럼 document에서 수많은 의 contexts를 모아서 를 대표하는 벡터(임베딩)를 만든다.
임베딩 공간: 단어들을 고차원 공간의 한 위치에 임베딩하는 것으로 간주하며 공간의 차원은 벡터의 길이
**임베딩(embedding)- 어떤 대상을 숫자로 표현하는 것
여기선 각 단어들을 의미적 유사성을 반영한 벡터 형태로 바꾸는 것 !!

가 나올 때마다 context들의 벡터를 관찰하고 그 벡터들과 의 벡터를 같은 방향으로 만들어간다.
→ loss를 줄이면서 의 위치를 업데이트한다.
Problem:
여러 문장에서 반복적으로 등장하는 모든 를 하나의 로 통계적 평균적 의미를 담는 한계가 있다.
예를 들어 'bank'라는 단어가 '금융 기관'일 때와 '강둑'일 때의 의미를 구분하지 못한다.
Vectors
목표: 각 word에 대해 dense vector를 만드는 것이다. 이 벡터는 비슷한 context에서 나타나는 단어들의 벡터와 유사하도록 설계된다.
그렇다면 어떻게 similarity를 측정할까 ?
벡터간의 유사성은 “vector dot product”를 통해 측정된다. 내적 값이 클수록 두 단어의 벡터가 비슷한 방향을 향하기 때문
WordVector는 word embeddings 또는 neural word representations 라고도 불린다.

Word2Vec란 ?
Word2Vec
Word2Vec는 word를 vector로 학습하기 위한 프레임워크이다.
- Corpus (말뭉치) : 아주 큰 Corpus (a long list of words) 가 주어진다.
- Vocabulary (어휘집) : 등장하는 모든 단어를 고정된 집합으로 관리한다. 여기에 있는 모든 단어들은 벡터로 표현된다.
- Vector Representation (단어 벡터 표현) : 각 단어를 하나의 벡터로 나타낸다.
text에서 각 위치를 라고 하고 차례로 살펴보면, 에는 center word()와 context word인 outside word() 가 존재한다.
center word와 context word 벡터 간의 similarity를 이용하여 중심단어가 주어졌을때 주변단어가 등장할 확률을 높이도록 단어 벡터를 조정한다.
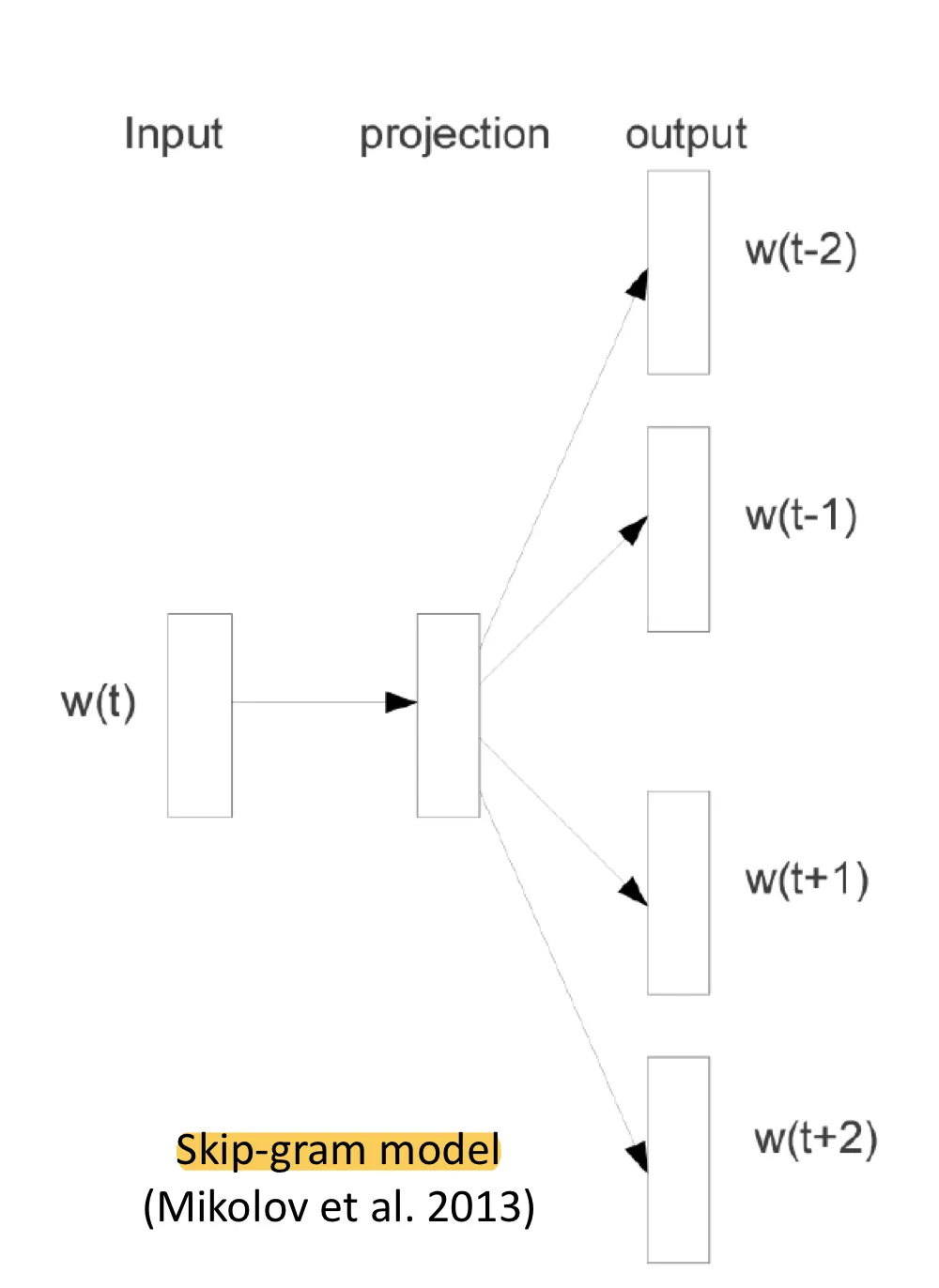
Skip-gram model은 중심단어 w(t)가 입력으로 들어오면
그 주변단어들 w(t-2), w(t-1), w(t+1), w(t-2)를 예측한다.
- 중심단어 하나 → 여러 개의 주변단어 예측

