Faster R-CNN 요약 및 느낀점
논문(번역기 사용) 및 여러가지 블로그, 유튜브를 읽고 보면서, 제가 느낀대로 써보았습니다. 틀린점이 있다면 댓글로 알려주세요!
참고한 곳
논문
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드 - 인프런 | 강의
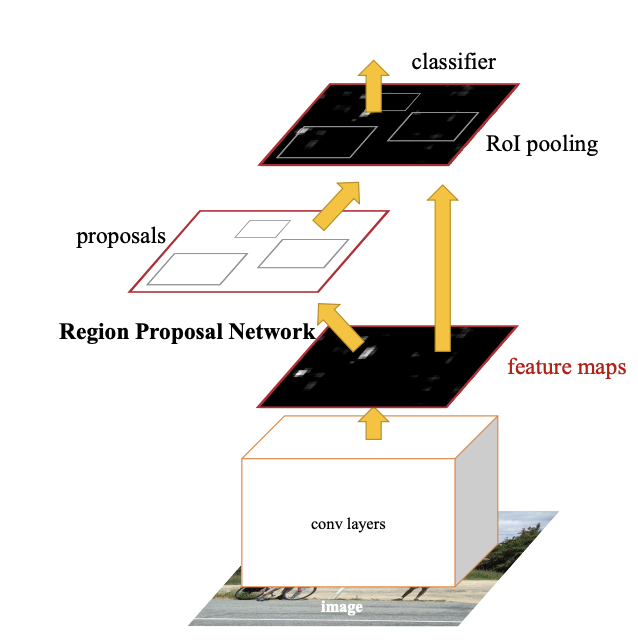
Faster R- CNN = RPN + Fast R-CNN
핵심 사항
- RPN이란?
- Anchor Box RoI를 이용한 object detection



1. 이미지에 닻(anchor)을 나둔다(실제로는 feature map에 한다)
2. 위의 2번 째 이미지 처럼 닻 1개당 9개의 box를 친다.
3. 영역 추천을 한다.논문 제목: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(Faster R-CNN: 지역 제안(Region Proposal ) 네트워크를 통한 실시간 개체 감지를 향하여)
저자: Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
발표: 2015년 6월 4일 제출(v1), 2016년 1월 6일 최종 수정(v3)
읽고 느낀점

- 어떻게 하면 모델의 성능을 올릴 수 있는지 많은 고민과 실험을 했다는 걸 느꼈다. VGG와 ZF은 모델만 다를 뿐인데 성능차이가 매우 크게나서 놀랐다. 내가 배우기로는 한 때는 VGG가 응용하기 쉬워서 많이 사용했고, 요즘은 구글의 Google Inception Model. 이나 MS의 ResNet이 논문과 코드를 공개해서 많이 쓴다고 들었다. MMdetection만해도 Faster R-CNN 모델이 VGG가 아닌 RestNet으로 학습을 한다. 추후에 ConvNeXt나 swin을 사용하면 더 성능이 향상될 수있지 않을까?
- 나중에 주석에 적힌 논문도 몇 개 읽어야겠다고 느꼈다. R-CNN, SPP 등의 논문에서 DPM, HOG, SIFT, ZF 등의 모델 성과를 비교하는 표가 나온적이있다. 몇몇을 class를 제외하고 R-CNN이 압도적으로 높고, deep learning을 배울 때 따로 언급이 안되어서 굳이 찾아보지 않았다. 그런데 Faster R-CNN에서 ZF, DPM의 모델을 여러번 언급이 한다. 그래서 읽어는 보아야겠다는 생각이 들었다.
- end-to-end(딥러닝)이 가능하다고 계속 강조하는 느낌이었다.
색인 용어
- RPN(Region Proposal Network) = 저자가 만든 모델, 앵커(Anchor) 개념을 알면 거의 다 알았다고 볼 수 있다.
- end-to-end = 딥러닝
- SS(Seletive Search)와 EB(Seletive Search)
- Attention = NLP(자연어 처리)에서 쓰는 기법
Abstract(초록)
- RPN(Region Proposal Network)을 도입하여 비용이 거의 들지 않는 영역 제안을 가능하게 한다. RPN은 각 위치에서 객체 범위와 객체성 점수를 동시에 예측하는 완전 컨벌루션 네트워크이다.
- 엔드-투-엔드(딥러닝)로 훈련한다.
- "주의(attention)" 메커니즘이 있는 신경망의 최근 인기 용어를 사용하여 RPN 구성 요소는 통합 네트워크에 어디를 볼지 알려준다.
(내생각) attention은 NLP에만 쓰는 줄 알았는데 CV에서 비슷한 개념을 만들었다고 해서 놀랐다. 이후에 나올 NLP의 Transformer도 그렇고 방향이 달라서 그렇지 같은 뉴런 네트워크이다 보니 응용이 된다는 점이 신기하다.
1. INTRODUCTION(소개)
-
RPN(Region Proposal Networks)을 소개합니다. 테스트 시간에 컨볼루션을 공유함으로써 제안 컴퓨팅의 한계 비용이 적다(예: 이미지당 10ms).
-
RPN은 일종의 FCN(full convolutional network)이며 특히 탐지 제안을 생성하는 작업을 위해 end-to-end(딥러닝) 훈련할 수 있다.
-
여러 배율과 종횡비에서 참조 역할을 하는 새로운 "앵커" 상자를 소개한다.
-
은 테스트 시 선택적 검색의 거의 모든 계산 부담을 면 제합니다. 제안을 위한 효과적인 실행 시간은 10밀리초에 불과하다.
-
GPU에서 5fps(모든 단계 포함)의 프레임 속도를 가지므로 속 도와 정확도 측면에서 실용적인 객체 감지 시스템이다.
2. RELATED WORK(관련된 일)

Object Proposals(개체 제안)
- 객체 제안 방법에는 그룹화 슈퍼 픽셀(예: 선택적 검색, CPMC, MCG) 및 슬라이딩 윈도우(예: 윈도우의 객체성(objectness in windows), EdgeBoxes)에 기반한 방법이 포함된다.
Deep Networks for Object Detection(객체 감지를 위한 딥 네트워크)

- Faster R-CNN은 은 객체 감지를 위한 단일 통합 네트워크입니다.
- RPN 모듈은 이 통합 네트워크의 'Attention' 역할을 합니다.3. FASTER R-CNN
- 두 개의 모듈로 구성됩니다.
-
첫 번째 모듈은 영역을 제안하는 심층 완전 합성곱 네트워크(deep fully convolutional network)이고,
-
모듈은 proposed regions을 사용하는 Fast R-CNN detector이다.
3.1 Region Proposal Networks(지역 제안 네트워크)
- 궁극적인 목표는 Fast R-CNN 객체 감지 네트워크와 계산을 공유하는 것이므로 두 네트워크가 공통된 컨볼루션 레이어 세트를 공유한다고 가정합니다.
- 실험에서 우리는 5개의 공유 가능한 컨볼 루션 레이어가 있는 Zeiler 및 Fergus 모델32과 13개의 공유 가능한 컨볼루션 레이어가 있는 Simonyan 및 Zisserman 모델3을 조사합니다.
(내생각) 위의 그림을 보면 RPN과 RoI pooling이 있다. RPN도 학습하고, RoI도 학습을 하는데 따로따로 할 수없으니 함께 학습하도록 하겠다.
3.1.1 Anchors

- 각 슬라이딩 윈도우 위치에서 여러 지역 제안을 동시에 예측합니다. 여기서 각 위치에 대해 가능한 최대 제안 수는 k로 표시됩니다.
- 우리는 3개의 축척과 3개의 종횡비를 사용 하여 각 슬라이딩 위치에서 k = 9개의 앵커를 생성합니다. 크기 W × H(일반 적으로 ~2,400)의 컨볼루션 특징 맵의 경우 총 W Hk 앵커가 있습니다.
Translation-Invariant Anchors(변환 불변 앵커)
- MultiBox 방법[27]은 k-평균을 사용하여 변환 불변이 아닌 800개의 앵커를 생성합니 다. 따라서 MultiBox는 개체가 번역된 경우 동일한 제안이 생성되는 것을 보장하지 않는다.
- 변환 불변 속성은 또한 모델 크기를 줄입니다. MultiBox에는 (4 + 1) × 800 차원의 완전 연결 출력 레이어가 있는 반면, k = 9 앵커의 경우 우리 방법 에는 (4 + 2) × 9 차원의 컨볼루션 출력 레이어가 있습니다. 결과적으로 출력 레이어에는 2.8 × 104 매개변수(VGG-16의 경우 512 × (4 + 2) × 9)가 있 으며 6.1 × 106 매개변수(1536 × (4 + 1 ) × MultiBox의 GoogleNet의 경우 800). 기능 프로젝션 레이어를 고려하는 경우 제안 레이어에는 여전히 MultiBox6보다 훨씬 적은 매개변수가 있다 .
- 우리는 우리의 방법이 PASCAL VOC와 같은 작은 데이터 세트에 과적합될 위험이 적 을 것으로 기대한다.
Multi-Scale Anchors as Regression References(회귀 참조로서의 다중 척도 앵커)
- 우리의 앵커 설계는 여러 척도(및 종횡비)를 처리하기 위한 새로 운 체계를 제시한다.
- 첫 번째 방법은 예를 들 어 DPM 및 CNN 기반 방법에서 이미지/기능 피라 미드를 기반으로 합니다. DPM에서 서로 다른 종횡비의 모델은 서로 다른 필터 크기(예: 5×7 및 7×5)를 사용하여 개별적으로 학습한다.
- 두 번째 방법은 일반적으로 첫 번째 방법과 공동으로 채택된다.
- 이에 비해 우리의 앵커 기반 방법은 더 비용 효율적인 앵커 피라미드를 기반 으로 합니다.
- 우리의 방법은 여러 크기와 종횡비의 앵커 박스를 참조하여 경계 상자를 분류 하고 회귀합니다. 단일 스케일의 이미지 및 기능 맵에만 의존하며 단일 크기의 필터(기능 맵의 슬라이딩 창)를 사용합니다. 실험을 통해 여러 척도 및 크기를 처리하기 위한 이 체계의 효과를 보여줍니다(표 8).
- 단일 스케일 이미지에서 계산된 컨벌루션 기능을 간단히 사용할 수 있습니다. 멀티 스케일 앵커의 설계는 스케일을 처리하기 위 한 추가 비용 없이 기능을 공유하기 위한 핵심 구성 요소입니다.
3.1.2 Loss Function(손실 함수)


3.1.3 Training RPNs
- PN RPN은 역전파(back propagation) 및 확률적 경사하강법(SGD)을 통해 딥러닝(end-to-end)을 한다.
3.2 Sharing Features for RPN and Fast R-CNN(RPN 및 Fast R-CNN의 피쳐(Features, 특징) 공유)
(내 생각) Faster R-CNN은 RPN + Fast R-CNN이다. RPN + Fast R-CNN 둘 다 각각 딥러닝이 가능하다. 이 파트에서는 동일한 CNN의 Features를 사용한다는 것같다. (Sharing Features)
- 기능 공유 지금까지 이러한 제 안을 활용할 지역 기반 객체 감지 CNN을 고려하지 않고 지역 제안 생 성을 위한 네트워크를 훈련하는 방법을 설명했습니다.
- 독립적으로 훈련된 RPN과 Fast R-CNN은 서로 다른 방식으로 컨 벌루션 레이어를 수정합니다. 따라서 우리는 컨볼루션 레이어를 공유 할 수 있는 기술을 개발해야 한다.
- (i) 교대 훈련.(Alternating training)
- 이 솔루션에서는 RPN이 먼저 Train한다. 그리고 proposals(영역 제안)을 사용하여 Fast R-CNN(RoI)을 train합니다.
- (ii) 대략적인 합동 훈련(Approximate joint training)
- 역전파(backward propagated)는 평소와 같이 발생한다. 공유 레이어(shared layers)의 경우 RPN 손실과 Fast RCNN 손실 모두에서 역방향 전파 신호가 결합된다.
- 실험에서 우리는 이 솔버가 근 접한 결과를 생성하지만 교대 훈련에 비해 훈련 시간을 약 25-50% 단축 한다는 것을 경험적으로 발견했다.
- (iii) 대략적이지 않은 합동 훈련.
(내생각) 이해를 하지 못했다.
- 4단계 교대 훈련(Non-approximate joint training.)
- 4-Step Alternating Training(4단계 학습 알고리즘)
- 1단계에서 섹션 3.1.3에 설명된 대로 RPN을 교육합니다
- 2단계에서는 1단계 RPN에서 생성된 proposals(영역 제안)을 사용하여 Fast R-CNN으로 별도의 탐지 네트워크를 훈련합니다
- 3단계에서 we use the detector network to initialize(초기화) RPN training
- but 공유 컨벌루션 레이어를 수정하고 RPN 고유의 레이어(layers unique to RPN)만 수정한다.
- ⇒ 두 네트워크는 컨벌루션 계층을 공유한다.
- 마직막 4단계에서 공유 컨벌루션 레이어(shared convolutional layers)를 고정된 상태로 유지하면서 Fast R-CNN의 고유한 레이어를 fine-tune한다.
- 두 네트워크는 동일한 컨벌루션 계층을 공유하고 통합된 네트워크를 형성합니다. 더 많은 반복을 위해 유사한 교 대 교육을 실행할 수 있지만 미미한 개선이 관찰되었습니다.
- (ii) 대략적인 합동 훈련(Approximate joint training)
- 이 솔루션에서는 RPN이 먼저 Train한다. 그리고 proposals(영역 제안)을 사용하여 Fast R-CNN(RoI)을 train합니다.
3.3 Implementation Details(구현 세부 정보)
- 앵커의 경우 상자 영역이 1282 2562 인 3가지 척도를 사용합니다. 앵커의 경우 상자 영역이 1282 2562 인 3가지 종횡비.
- 이미지 경계를 가로지르는 앵커 상자는 주의해서 다루어야 합니다. 학 습하는 동안 우리는 모든 교차 경계 앵커를 무시하므로 손실에 기여하지 않습니다. 일반적인 1000 × 600 이미지의 경우 대략 총 20000(≈ 60 × 40 × 9) 앵커가 있습니다. 교차 경계 앵커를 무시하면 훈련을 위한 이 미지당 약 6000개의 앵커가 있습니다. 훈련에서 경계 교차 이상값을 무시 하지 않으면 목적에 크고 수정하기 어려운 오류 항이 도입되고 훈련이 수 렴되지 않습니다. 그러나 테스트하는 동안 우리는 여전히 전체 이미지에 완전 컨벌루션 RPN을 적용합니다. 이렇게 하면 이미지 경계에 클립되는 교차 경계 제안 상자가 생성될 수 있습니다.
4. EXPERIMENTS(실험)

- PASCAL VOC 2007
- 이 데이 터 세트는 20개 개체 범주에 대한 약 5k개의 trainval 이미지와 5k 개의 테스트 이미지로 구성됩니다
- Fast R-CNN 프레임워크에서 SS는 mAP가 58.7%이고 EB 는 mAP가 58.6%입니다.
(내생각) train 이미지와 test 이미지의 개수가 같아서 신기했다. 공부를 할 때는 아무리 train 이미지가 많아도 test는 100~500개만 했기 때문이다.
(내생각)아래와 같이 여러가지 실험과 시도 했고, 결과가 있다. 하지만 뭔가 적기 애매해서 쓰지는 않았다.
- Performance of VGG-16.
- Sensitivities to Hyper-parameters.
- Analysis of Recall-to-IoU.
- One-Stage Detection vs. Two-Stage Proposal + Detection.
4.2 Experiments on MS COCO
- Faster R-CNN in ILSVRC & COCO 2015 competitions
4.3 From MS COCO to PASCAL VOC
5. CONCLUSION(결론)
- 효율적이고 정확한 지역 제안 생성을 위해 RPN을 제시했습니다
- 다운스트림 감지 네트워크가 있는 기능을 사용하면 지역 제안 단계는 거의 비용이 들지 않습니다. 우리의 방법은 통합된 딥 러 닝 기반 물체 감지 시스템이 거의 실시간 프레임 속도로 실행되도 록 합니다. 학습된 RPN은 또한 영역 제안 품질을 향상시켜 전반 적인 객체 감지 정확도를 향상시킵니다
