Fast R-CNN 요약 및 느낀점
논문 및 여러가지 블로그, 유튜브를 읽고 보면서, 제가 느낀대로 써보았습니다. 틀린점이 있다면 댓글로 알려주세요!
참고한 곳
논문
SVD(유튜브)
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드 - 인프런 | 강의
논문 제목: Fast R-CNN
저자: Ross Girshick, Microsoft Research
발표: 2015년 4월 30일에 제출(v1), 2015년 9월 27일에 최종 수정됨(v2)
읽고 느낀점
- 신문 광고글 같았다. 논문 길이가 9쪽이고 계속 빠르고 정확하다면서 자랑하고 QnA(5번 소목차들의 의문형)가 있어서 더 그렇게 느꼈다.
- 자꾸 R-CNN보다 빠르다면서 R-CNN을 무시하는 느낌이었다.
- 순간 저자가 다른 사람인가 싶어서 찾아보니 이번 논문은 Ross Girshick만 같고 Microsoft Research와 함께했다.
- 마지막으로 굉장히 친절하다고 느꼈다. 처음에는 광고글 같아서 피식 거리면서 읽었는데 요약 및 정리를 하니 버릴 문장이 없고, 만약 논문 구현 및 실험을 하면 어떻게하면 좋을지도 친절하게 잘 적어놓았다는 걸 느꼈다.(물론 그렇다고 당장 전부 이해되고 구현하는게 가능한 건 아니다)
- 읽을 때는 단순히 Faster R-CNN을 거처가는 단계라고 생각했고 RoI 외에는 큰 의미가 없다고 생각했다. 하지만 읽으니 Truncated SVD이용한 시간단축 아이디어, sparse object proposals를 실험하기 좋다고 말했고 2020년에 논문으로 구현이 된 게 신기했다. 그리고 좀 더 다양하게 읽을 필요가 있다고 느꼈다.
Abstract(초록)
우리는 Fast R-CNN보다 9배, SPPnet보다 3배 더 빠르게 train한다. 아래의 링크에 가면 구현된 코드를 볼 수있다(참고로 더이상 사용하지 되지 않는다. MMdetection같은 라이브러리를 이용하거나 직접 구현해서 써야한다)
GitHub - rbgirshick/fast-rcnn: Fast R-CNN
1. Introduction(소개)
- 런타임에 감지 네트워크(detection network)는 0.3초 안에 이미지를 처리한다.
- (객체 제안 시간(object proposal time) 제외).
R-CNN의 단점
- 학습 파이프라인이 너무 길다(Training is a multi-stage pipeline)
- select search → convNet→ SVM
- 시간과 공간(메모리)를 너무 잡아먹는다.(Training is expensive in space and time.)
- 는 VOC07 trainval 세트의 5k 이미지에 대해 2.5 GPU 일이 걸립니다. 이러한 기능에는 수백 기가바이트의 스토리지가 필요하다.
- 물체감지가 너무 느리다(Object detection is slow.)
SPPnet은
- R-CNN을 10~100배 가속합니다. 더 빠른 제안 기능 추출로 인해 학습(train) 시간도 3배 단축된다
- 그러나 R-CNN과 마찬가지로 학습 파이프라인이 너무 길다.
- (내 생각) 찾아보니 그냥 SPP-net을 추가한 R-CNN이다. 그래서 R-CNN과 마찬가지다.
- fine-tuning 알고리 즘 은 공간 피라미드 풀링에 선행하는 컨볼루션 레이어를 업데이트할 수 없다.
- (내 생각)CNN을 한 것을 한 번 더 나누어서 pooling(SPP) 역전파가 안된다는 의미인가?
- 이 제한(spatial pyramid pooling(SPP)은 매우 깊은 네트워크의 정확도를 제한합니다.
Fast R-CNN은 다음과 같은 장점이 있다
- R-CNN, SPPnet보다 높은 검출 품질(mAP)
- 학습은 다중 작업 손실을 사용하는 단일 단계입니다
- 교육은 모든 네트워크 계층을 업데이트할 수 있습니다.
- 2, 3번 SVM을 안 쓰고 softmax + Multi-task Loss 함수 사용해서 모델 전체가 딥러닝(역전파 등)이 가능하다.
- 피쳐 캐싱(feature caching)을 위해 디스크 저장소가 필요하지 않습니다
- (내 생각)피쳐 캐싱을 검색을 해보았으나 정확하게는 모르겠다.
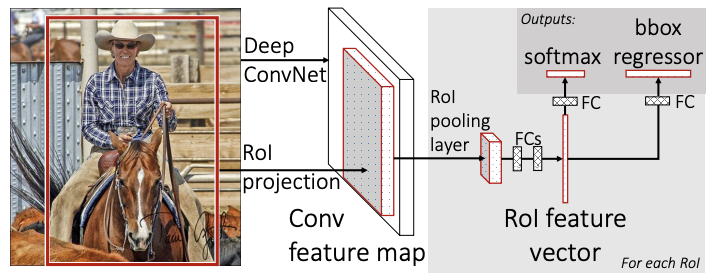
2. Fast R-CNN architecture and training(Fast R-CNN의 아키텍처 (구조) 및 학습)
- 네트워크
- 먼저 여러 컨벌루션(conv) 및 최대 풀링 레이어로 전체 이미지를 처리하여 conv 기능 맵을 생성한다.
- 각 개체 제안에 대해 관심 영역(RoI) 풀링 레이어가 특징 맵에서 고정 길이 특징 벡터를 추출한다.
- 각 특징 벡터는 완전히 연결된(fc) 계층의 시퀀스에 입력되어 최종적으로 두 개의 형제 출력 계층으로 분기됩니다
- 하나는 K 객체 클래스에 대한 소프트 맥스 확률 추정을 생성하고 포괄적인 "백그라운드" 클래스와 4개를 출력하 는 다른 계층입니다
- K 객체 클래스 각각에 대한 실수 값. 4개 값의 각 세트 는 K 클래스 중 하나에 대해 정제된 경계 상자 위치를 인코딩합니다.



- RoI 풀링 계층

-
RoI 풀링 계층은 최대 풀링을 사용하여 유효한 관심 영역 내부의 기능을 H × W(예: 7 × 7)의 고정된 공간 범위를 갖는 작은 기능 맵으로 변환한다
-
(내 생각)인터넷 강의로 듣기로는 14X7를 RoI를하면 2X1로 pooing을 해서 7X7을 만들 수있고, 8X4 같은 경우는 보간법을 이용해서 7X7을 할 수있다고 한다. 그러면 R-CNN 당시에는 보간법으로 resize하는게 덜 보편적이었던걸까?
-
(내 생각) 이때는 padding이란 개념은 언제부터 나온걸까? 보간법으로 resize 중 뭐가 더 좋을까? SPP는 average gloval conv를 썼으니까 padding을 하면 성능이 떨어졌을테고. 이건 max pooling을하니 padding이 더 높은 성과를 낼 수도 있지 않을까?
-
여기서 H 및 W는 계층 하이퍼 매개변수입니다. 특정 RoI와는 독립적이다.
-
이 백서에서 RoI는 conv 기능 맵에 대한 직사각형 창(window)이다.
- 각 RoI는 왼쪽 위 모서리(r, c)와 높이 및 너비(h, w)를 지정하는 4개의 튜플(r, c, h, w)로 정의됩니다. -
RoI 최대 풀링은 h × w RoI 창을 대략적인 크기 h/H × w/W의 H × W 하위 창 그리드로 나눈 다음 각 하위 창의 값을 해당 출력 그리드로 최대 풀링하는 방식으로 작동한다.
2.2. Initializing from pre-trained networks(사전 훈련된 네트워크에서 초기화)
- 우리는 각각 5개의 최대 풀링 레이어와 5~13개의 conv 레이어 가 있는 3개의 사전 훈련된 ImageNet 네트워크로 실험한다.
- 아래의 3가지 변화를 거친다.
- 마지막 최대 풀링 레이어는 네트워크의 첫 번째 완전 연결 레이어 와 호환되도록 H 및 W를 설정하여 구성된 RoI 풀링 레이어로 대체됩니다 (예: VGG16의 경우 H = W = 7).
- 네트워크의 마지막 완전 연결 계층과 소프트 맥스(1000-way ImageNet 분류를 위해 훈련됨)는 앞에서 설명한 두 형제 계층((K + 1 범주 및 category-specific bounding-box regressors에 대한 완전 연결 계층(fully connected ) 및 softmax 사용).
- 네트워크는 두 개의 데이터 입력을 받도록 수정됩니다.
2.3 Fine-tuning for detection(감지를 위한 미세 조정)
- 학습 중 특징 공유를 활용한 보다 효율적인 학습 방법을 제안합니다. Fast R CNN 훈련에서 SGD(stochastic gradient descent) 미니 배치는 먼저 N개 이 미지를 샘플링한 다음 각 이미지에서 R/N RoI를 샘플링하여 계층적으로 샘플링됩니 다
- 동일한 이미지의 RoI는 정방향 및 역방향 패스에서 계산 및 메모리를 공 유합니다. N을 작게 만들면 미니 배치 계산이 줄어듭니다. 예를 들어, N = 2 및 R = 128을 사용하는 경우 제안된 훈련 방식은 128개의 서로 다른 이미지(즉, RCNN 및 SPPnet 전략)에서 하나의 RoI를 샘플링하는 것보다 대략 64배 더 빠르다.
- 이 전략에 대한 한 가지 우려는 동일한 이미지의 RoI가 상호 관련되어 있기 때 문에 느린 훈련 수렴을 유발할 수 있다는 것입니다. 이 문제는 실질적인 문제가 아 닌 것으로 보이며 R-CNN보다 적은 SGD 반복을 사용하여 N = 2 및 R = 128로 좋 은 결과를 얻습니다
- 계층적 샘플링 외에도 Fast R-CNN은 세 개의 개별 단계에서 softmax 분류 기, SVM 및 회귀자를 교육하는 대신 softmax 분류자와 경계 상자 회귀자를 공동 으로 최적화하는 하나의 미세 조정 단계로 간소화된 교육 프로세스를 사용합니다 . 9, 11]. 이 절차의 구성 요소(손실, 미니 배치 샘플링 전략, RoI 풀링 레이어를 통 한 역전파, SGD 하이퍼 매개변수)는 아래에 설명되어 있습
- 백그라운드 RoI의 경우 ground-truth 개념이 없습니다.

- R-CNN 및 SPPnet에서 사용되는 L2 손실 보다 이상값에 덜 민감한 강력한 L1 손 실입니다. 회귀 대상이 제한되지 않은 경우 L2 손실을 사용한 교육은 기울기 폭발 을 방지하기 위해 학습 속도를 신중하게 조정해야 할 수 있습
- 미니 배치 샘플링. 미세 조정 중에 각 SGD 미니 배치는 N = 2 이미지로 구성되며 균 일하게 무작위로 선택됩니다(일반적인 관행과 같이 실제로 데이터 세트의 순열을 반 복함). R = 128 크기의 미니 배치를 사용하여 각 이미지에서 64개의 RoI를 샘플링 합
- SGD 하이퍼 매개변수. 소프트맥스 분류 및 경계 상자 회귀에 사용되는 완전 연결 계 층은 표준 편차가 각각 0.01 및 0.001인 제로 평균 가우시안 분포에서 초기화됩니 다. 편향은 0으로 초기화됩니다. 모든 계층은 가중치에 대해 1, 편향에 대해 2의 계층 당 학습률과 0.001의 전역 학습률을 사용합니다
- VOC07 또는 VOC12 trainval에서 훈련할 때 우리는 30k 미니 배치 반복에 대해 SGD를 실행한 다음 학습 속도를 0.0001로 낮추고 또 다른 10k 반복에 대해 훈련 합니다. 더 큰 데이터 세트에서 훈련할 때 나중에 설명하는 것처럼 더 많은 반복을 위 해 SGD를 실행합니다. 모멘텀 0.9와 매개변수 감쇠 0.0005(가중치 및 편향)가 사 용됩니다.
3. Fast R-CNN detection(Fast R-CNN 디텍션)
3.1 Truncated SVD for faster detection
- 전체 이미지 분류의 경우 완전 연결 계층을 계산하는 데 소요되는 시간은 conv 계층에 비해 적습니다. 반대로 감지를 위해 처리할 RoI의 수가 많고 순방향 통과 시 간의 거의 절반이 완전 연결 계층을 계산하는 데 사용됩니다.
- 이 간단한 압축 방법은 RoI 수가 많을 때 좋은 속도 향상을 제공합니다
- (내생각) SVD 관련 동영상을 보고 왔는데도 이해가 안된다. 좀 더 공부가 필요하다.
4. Main results(주요 실적)

-
VOC07, 2010, 2012의 최첨단(State-of-the-art) mAP
-
R-CNN, SPPnet에 비해 빠른 교육 및 테스트
-
VGG16의 미세 조정 conv 레이어로 mAP 향상
4.4. Training and testing time(학습 및 테스트 시간)
- VGG16의 경우 Fast RCNN은 truncated SVD가 없는 R-CNN보다 146배 빠르고 R-CNN을 사 용하면 213배 더 빠르게 이미지를 처리한다. 교육 시간이 84시간에서 9.5 시간으로 9배 단축된다.
- SPPnet과 비교하여 Fast R CNN은 VGG16을 2.7배 더 빠르게(9.5시간 대 25.5시간) 훈련하고 잘린 SVD 없이 7배 더 빠 르게 또는 10배 더 빠르게 테스트한다.

5. Design evaluation
5.4. Do SVMs outperform softmax?(SVM이 softmax를 능가합니까?)

- (내 생각) FRCN(Faster R-CNN)이 당연히 R-CNN보다 높을 줄 알았는데 의외의 결과여서 놀랐다. 그리고 FRCN에서는 SVM을 써도 큰차이가 없다는 걸 알았다. 속도 등을 생각하면 굳이 SVM을 넣을 필요는 없지 싶다.

6. Conclusion(결론)
- 특히 희소 개체 제안(sparse object proposals)은 검출기 품질을 향상시키는 것으로 보이다. 이 문제는 과거에 조사하기에 는 시간이 너무 많이 들었지만 Fast R-CNN을 사용하면 실용화할 수 있다. 물론 조밀한 상자가 희박한 제안뿐만 아니라 수행할 수 있도록 하는 아직 발견 되지 않은 기술이 있을 수 있습니다. 이러한 방법이 개발되면 객체 감지를 더욱 가속화하는 데 도움이 될 수 있다.
- (내 생각)sparse object proposals이 뭔가 싶어서 검색을 했더니 Sparse R-CNN(2020년 논문)이 나와서 깜짝 놀랐다. "기존 모델들인 RetinaNet, Faster R-CNN에 대비해서 더 좋은 성능을 달성했음을 보실 수 있습니다. 그리고 최근에 트랜스포머 기반으로 Object detection을 수행했던 DETR보다 훨씬 빠른 수렴속도를 자랑하는 모델입니다."라고 설명을 해줘서 더 깜짝놀랐다.
