SPP 논문 리뷰
논문 및 여러가지 블로그, 유튜브를 읽고 보면서, 제가 느낀대로 써보았습니다. 틀린점이 있다면 댓글로 알려주세요!
SPP 논문 요약 및 느낀점
논문 제목: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
저자: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
발표: 2014년 6월 18일에 제출(v1), 2015년 4월 23일에 최종 수정됨, 리뷰 버전은 v4이다.
참고한 곳
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드 - 인프런 | 강의
[논문 리뷰] SPPnet (2014) 리뷰, Spatial Pyramid Pooling Network
[논문요약] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPP를 공부하고 느낀점
- 논문은 영어 능력이 안되서 번역기를 돌리면서 읽었다. + 아직 지식이 부족해서 제대로 이해하지 못했다.
- 논문을 읽기 전 정보: R-CNN까지는 직사각형의 이미지는 학습할 수없다. 왜냐하면 FC layer 때문이다. SPP는 이 문제를 해결했다.
- 논문을 읽은 후(혼란 가득)
- (질문)어떻게 직사각형을 해결한거지? padding을 이용한 건가? 그러면 1개와 3개(피라미트 맵)로 한 거에 차이가 있는 건가? 1개로는 padding을 해도 못 만드는 건가?
- 논문은 단일한 sliding window를 사용했다. 내가 봤을 때 이건 정사각형이다. 그리고 180X180, 240X240이야기가 나온다....직사각형은 어떻게 구한거지? padding으로 한 건가?
- 아니면 직사각형도 padding을 할 수 있었던건가? 단지 FC layer 크기를 맞출 수 없었을 뿐인가? 그래서 피라미드 맵으로 만들어서 FC layer의 크기를 맞출 수있었던 건가?
- (질문)어떻게 직사각형을 해결한거지? padding을 이용한 건가? 그러면 1개와 3개(피라미트 맵)로 한 거에 차이가 있는 건가? 1개로는 padding을 해도 못 만드는 건가?
Abstract
- 기존에는 CNN(합성곱)을 할려면 입력 이미지를 224 X 224(정사각형)로 해야했다. 그렇지 않으면 학습을 할 수없기 때문이다. 왜냐하면 FC layer를 할 수없기 때문이다.
- 하지만 정사각화하는 것은 좋지 않다. 왜냐하면 비율과 모양이 이상하게 되면서 정확도가 떨어질 수있다. 그러므로 나는 "spatial pyramid pooling(공간 피라미드 풀링, 직역함)”라는 기법을 소개하고자 한다.
- ::(내 생각) 이 때는 padding(부족한 공간에 0으로 채우기)이 아직 안 만들어진건가?::
색인
Convolutional Neural Networks(CNN) = 합성곱(Conv)과 pooling(크기줄이기)과 FC layer로 구성된 모델, http://taewan.kim/post/cnn/
Spatial Pyramid Pooling = 이 논문의 저자가 만든 것
Image Classification = 모델이 mnist처럼 이미지를 감별함
Object Detection = 2개 이상의 물체를 감지함
1. INTRODUCTION


- 기존의 CNN 순서와 방식.
- 위의 crop과 warp 기법을 사용했다. 위의 그림과 같이 crop을 하면 이미지 중 일부가 잘린다. warp은 모양과 특징이 바뀐다.

- 우리가 제안한 방식. 정사각형으로 만드는 이유는 FC layer 때문이다. "spatial pyramid pooling"을 이용하면 직사각형으로도 학습이 가능하다.
- 우리는 이 새로운 네트워크 구조를 SPP-net이라고 지었다.
이 방법은 3가지 장점이 있다.
- SPP는 입력 크기(input size)에 관계없이 고정 길이 출력을 생성할 수 있다. 즉, 직사각형 이미지도 학습이 가능하다.
- SPP는 다중 레벨 공간 빈(SSP uses multi-level spatial bins)을 사용하는 반면 슬라이딩 윈도우 풀링은 단일 윈도우 사이즈(only a single window size.)만 사용합니다.
- ::(내생각)SSP uses multi-level spatial bins는 무슨 말인지 모르겠다.::
- ::(내생각)이 논문을 읽기 전 정보로는 img 하나당 CNN을 한번만 된다고 들었다. 그런데 sliding window는 여러 크기의 box로 객체 탐지를하지 않나? 단일하게 해도 나중에 Conv와 pooing으로 특징 추출를 하면 되니까 단일 sliding window를 쓰는 건가?::
- SPP는 입력 스케일의 유연성 덕분에 다양한 스케일에서 추출된 기능을 풀링할 수 있습니다. 실험을 통해 우리는 이러한 모든 요소가 딥 네트워크(deep networks)의 인식 정확도를 높인다.
우리는 R-CNN은 보다 100배 이상 빠르다. 그리고 SPP-net기반 시스템(파이프라인은 R-CNN)은 24~102배 더 빠르고, 비슷한 거나 높은 정확도를 가진다.


- R-CNN 방식

- SPP-net을 적용시킨 방식
2. DEEP NETWORKS WITH SPATIAL PYRAMID POOLING

- ::(내생각) 제대로 이해하지 못했다. 그러니까::
- ::(a) 이미지를 넣는다::
- ::(b) 필터(filter)이다. 이 필터는 CNN으로 Feature Extraction(특징 추출)을 했다.::
- ::(c) 단일한 sliding window를 이용해서 쪼갰다. 그 중 가장 강한 영역에 초록색으로 box친 곳은 가장 높은 반응을 일으킨 곳이다( strongest responses of the corresponding filters).::

- Bag-ofWords(BoW) 방식 사용했다고한다.
(내 생각, 이해안 됨)
어느 블로그에서 설명하기를
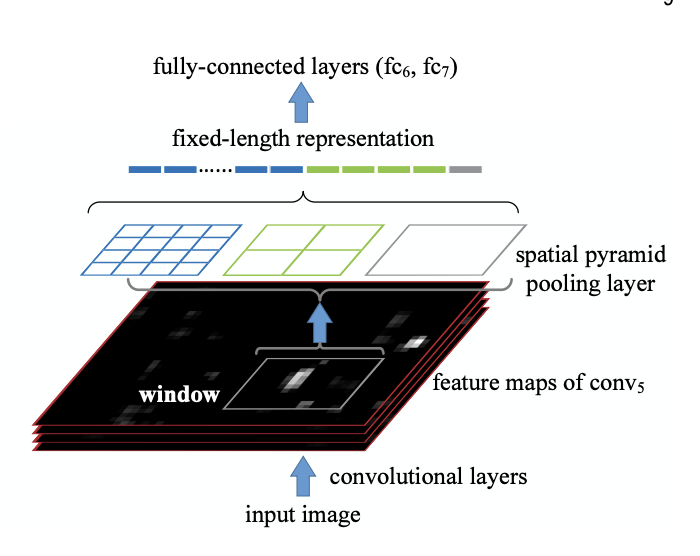
- ::이미지를 넣는다::
- ::Conv layer로 피쳐맵(feature map)을 만든다::
- ::피라미드 맵을 만든다(피쳐맵의 영역을 나눈다. 그림에서는 4X4, 2X2, 1X1 ⇒ 16+4+1 =21개 빈(bin))::
- ::피라미드의 한 칸을 bin이라고 부르며, 각 bin에 대해서 max pooling 연산을 적용한다.::
- ::max pooling의 결과를 이어 붙여 FC layer로 만든다.::
::입력(feature map)의 크기가 k, bin의 개수를 M이라고 한다면 SPP의 최종 출력은 kM차원의 벡터이다.::
::즉, 입력의 크기에 상관없이 사전에 설정한 bin의 개수와 채널값으로 SPP의 출력이 정해지기에 항상 동일한 크기의 출력을 생성한다고 할 수 있다.::
::라고 했다.::
- ::논문에서 말하길 "입력 이미지의 크기를 임의의 스케일(예: min(w, h)=180, 224, ...)로 조정하고 동일한 딥 네트워크를 적용할 수 있다"고 했다.::
- ::(의문) 사진을 보면 정사각형의 slice window까지는 이해가 되는데 직사각형은 어떻게 한 거지? 나중에 밑을 읽어보니까 180X180, 240X240이렇게 2가지 크기를 고려한다고 적혀있던데.::
- ::(질문 1)아무리 읽어도 정사각형에서 특징을 추출해서 맞추는 것 같은데 어떻게 R-CNN(selective search로 직사각형 모양)에 적용한거지?::
- ::(질문 2) 내가 배우기로는 pooling은 정사각형이 되야하고 이를 위해서 padding이 필요하다고 했다. 직사각형일 때 padding을 이용한 걸까?::
- ::(질문 3) 만약 padding을 사용했다는 가정하에, 1개의 feature map을 pooling하는 것보다 여러개의 feature map(피라미드 맵)을 pooling하는게 더 정확도가 높을까?::
3. SPP-NET FOR IMAGE CLASSIFICATION
- R-CNN에 SPP 모델을 함께 함께 사용했다 + 결과
- R-CNN은 컨볼루션을 위해 이미지당 14.37s인 반면, 우리 버전은 이미지당 0.053s만 사용한다. 따라서 우리는 R-CNN보다 270배 빠르다. 우리의 5-스케일 버전은 컨볼루션을 위해 이미지당 0.293s를 사용하 므로 R-CNN보다 49배 더 빠릅니다
4. SPP-NET FOR OBJECT DETECTION

- 우리 속도도 빠르고 정확도도 높다
- ILSVRC 2014 Detection에서 2등했다.
5. CONCLUSION
- 우리는 공간 피라미드 풀링 레이어로 심층 네트워크를 훈련시키는 방법을 제안했 습니다.
- 이러한 문제는 시각적 인식에서 다양한 크기와 비율 등이 중요하지만 딥 네트워크의 맥락에서 거의 고려되지 않았다. 하지만 이제는 SPP-net을 이용해서 다양한 scale,size, 종횡비를 처리할 수 있다. 이는 컴퓨터 비젼 영역에서 중요한 역할을 할 수 있음을 보여준다.
