"Novelty detection"
학습 분포와 벗어나는 샘플을 찾는 것
1. CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances (NeurIPS 2020, 358회 인용)
- hard augmentation을 활용하는 방식으로 contrastive learning 적용
- rotation과 같은 hard augmentation을 positive pair로 두면 오히려 성능 하락함
- 이러한 hard augmentation을 (distribution-)shifting transformation 이라고 정의함
- 참고로 이 방법은 standard clsasification의 representation을 개선시키지는 않는다.
- 단지 OOD detection의 representation의 성능을 개선시킬 뿐이다.
2. Contrastive Training for Improved Out-of-Distribution Detection (Deep Mind 2020, 154회 인용)
[Abstract]
- OOD(Out-of-Distribution) 입력의 신뢰할 수 있는 탐지는 기계 학습 시스템 배치의 전제 조건으로 점점 더 이해되고 있음 (중요성 ↑)
- 이 논문은 OOD 탐지 성능을 향상시키기 위한 Contrastive Learning의 사용을 제안함
- 실제로 수집하기 어려울 수 있는 레이블이 지정된 OOD를 요구하지 않고, 이상값 및 이상값 데이터 세트의 유사성을 포착하여 OOD 탐지 작업의 난이도를 정량화하는 CLP(Confusion Log Probability) 점수를 도입함
- 우리의 방법이 특히 이전 방법에 대한 까다로운 설정인 '근거리 OOD' 클래스에서 성능을 향상시킨다는 것을 보여줌.
[Introduction]
- 테스트 세트에서 높은 정확도를 얻는 잘 훈련된 심층 신경망 f는 낯선 분포에서 도출된 입력에 노출될 때 여전히 임의로 나쁜 예측을 할 수 있음.
- 의료 진단과 같은 안전에 중요한 애플리케이션에서는 기계 학습 시스템을 사용하여 잠재적으로 부정확한 예측을 하는 것보다 // 별도의 처리를 위해 훈련된 네트워크에 익숙하지 않은 입력을 탐지하는 것이 더 바람직할 것입니다.
- 네트워크 f는 분류에 필요한 최소치를 학습하도록 장려되므로, Oiler Exposure, RP 등을 활용해 일반적으로 학습되는 것 이상의 중간 특징 공간을 풍부하게 함
- 하지만, 이는 라벨이 있는 데이터를 필요로 하고, 가정에 의존함 - 분류 모델(네트워크 f)은 분류에 필요하지 않는 차원을 무시하지만, 대조학습은 두 차원 모두에서 민감하게 유지하도록 학습함
- OOD를 구별할 정량적 평가가 중요함
[Related Work]
Representations from classification networks.
- maximum softmax probability (MSP)
- ODIN by using temperature scaling and input pre-processing
- standard Gaussian density
- Gram matrices
Alternative training strategies.
- MSP scoring
- confidence loss, auxiliary objectives, margin loss, outlier exposure
- metric learning
Bayesian approaches.
- Bayesian paradigm -> model uncertainty
- Monte-Carlo dropout sampling
Generative and hybrid models.
- generative model
- ensemble approach
- likelihood ratios
- residual flow network
[Proposed Method]
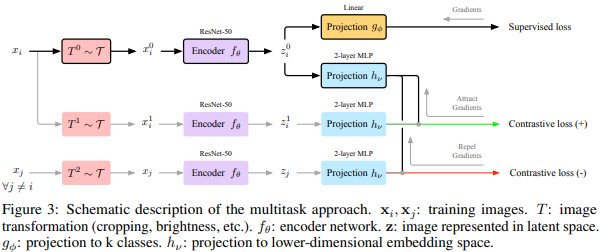
3. Open-Set Fault Diagnosis via Supervised Contrastive Learning With Negative Out-of-Distribution Data Augmentation (IEEE Transactions on Industrial Informatics 2022, 10회 인용)
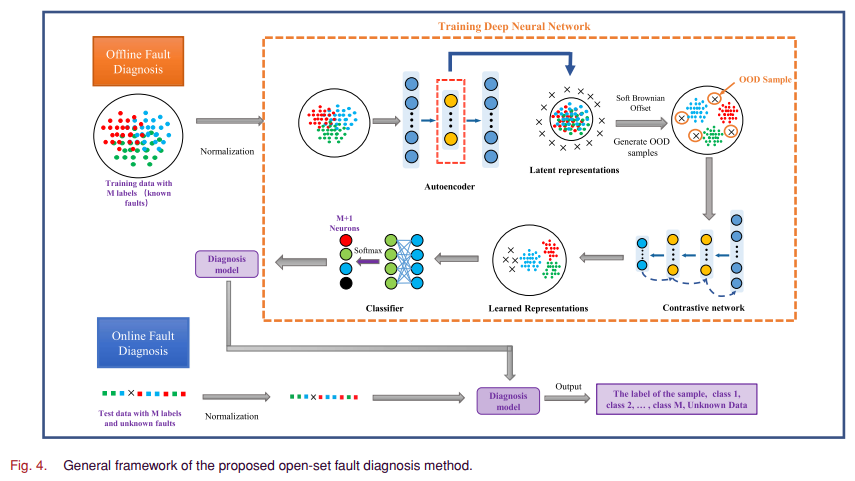
4. Out-of-Distribution Detection with Deep Nearest Neighbors (PMLR 2022, 78회 인용)
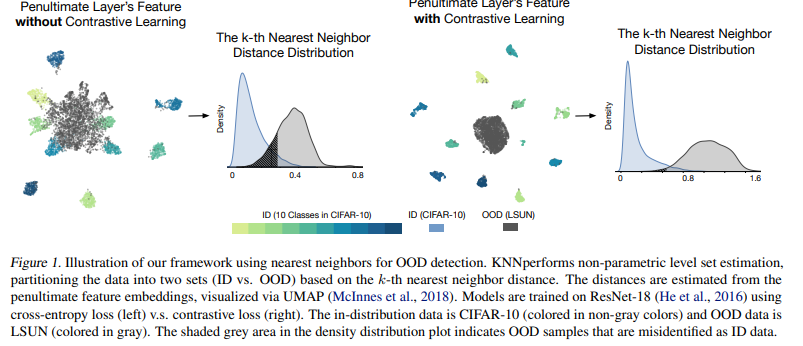
- KNN에 Contrastive Learning 적용한 방법
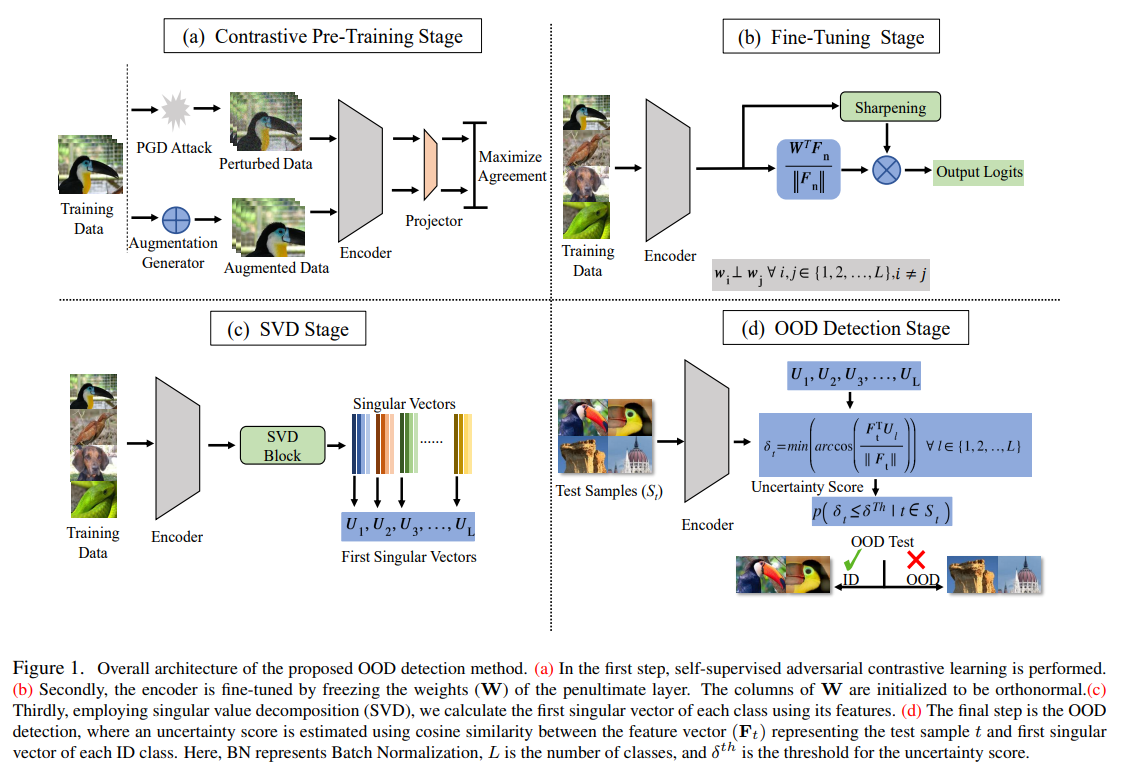
5. RODD: A Self-Supervised Approach for Robust Out-of-Distribution Detection (CVPRW 2022, 5회 인용| 5위)
- uncertainty score 정의해서, ID와 OOD 구분
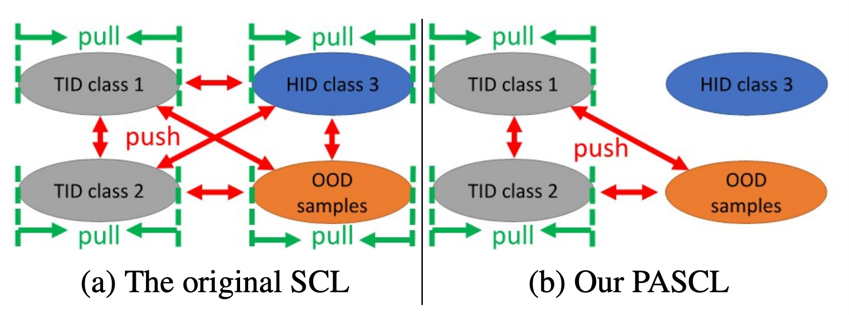
6. Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition (ICML 2022, 11회 인용) Code
- Real world datset에서 흔하게 나타나는 Long-tailed distribution을 다루고자 함
- Long-tailed distribution은 class imbalance의 imbalance ratio가 극심한 경우로, sample 수가 dominant한 class를 head-class(HID)라고 하며, sample 수가 scarce한 class를 long-tail-class(TID)라고 함
- 불량 감지, 질병 진단, 자율 주행 차 사고 감지, 사이버 보안 등 - OOD에서는 Tail-class In-Distribution(TID) sample을 오분류하는 case가 많음.
- TID sample 수가 적고 variance가 작아, 학습시 under-represented 되어 DNN 모델이 OOD sample과의 decision boundary를 잘 찾지 못함. - 기존 SCL과 달리, TID sample과 OOD sample의 feature들이 더 잘 구분될 수 있도록 Contrastive Learning을 진행하는 방법론 제안함.
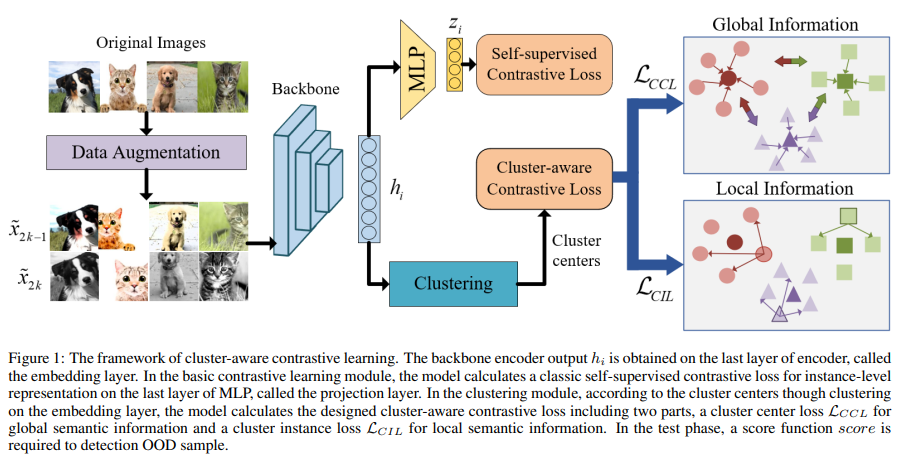
7. Cluster-aware Contrastive Learning for Unsupervised Out-of-distribution (2023)
- Unsupervised out-of-distribution (OOD) Detection 목적
- 대조학습이 OOD detection을 위한 discriminative representation에 도움을 줌
- 그러나, instance-level 관계에 초점을 맞춰 진행되어, 같은 semantics를 공유하는 samples간의 관계에 대한 관심이 적었음
- 따라서 논문에서는, instance-level과 semantic-level information을 모두 고려하는 U-OOD를 제안함
- 성능 면에서 조금 부족함..
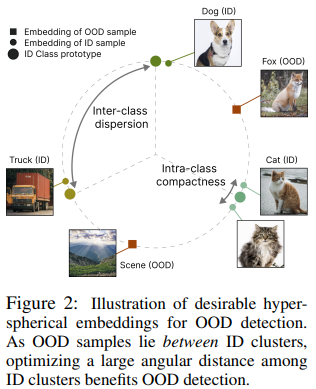
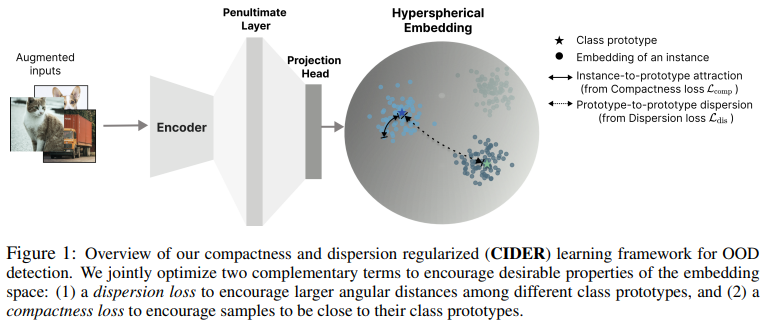
8. HOW TO EXPLOIT HYPERSPHERICAL EMBEDDINGS FOR OUT-OF-DISTRIBUTION DETECTION? (ICLR 2023, 5회 인용) Code
-
Hyperspherical embeddings for OOD detection
- von Mises-Fisher (vMF) distribution 활용
: a classical and important distribution in directional statistics (Mardia et al., 2000)
-
2 losses to promote strong ID-OOD separability
- a dispersion loss (that promotes large angular distances among different class prototypes)
- a compactness loss (that encourages samples to be close to their class prototypes)
+ SupCLR
- in-distribution의 class를 예측하는 extension을 함께 제안함
- classification의 confidence를 높일 수 있는 confidence-calibrated calssifier을 학습하고자 함
- SimCLR와 다르게 각 sample을 instance-wise가 아닌 class-wise하게 대조함
- 같은 class에 속한 sample들을 positive라고 두고, 다른 class에 속한 sample들을 negative라고 둠

to be data scientist