-
기존의 instance discriminator모델들이 negative samples를 사용한 이유는 다음과 같음
다양한 관점의 positive sample들이 학습 과정에서 관점과 관계없이 동일한 representation을 생성하지 않도록 하기 위함
- 즉, Augmentation을 통해 이미지의 다양한 요소를 representation에 녹여내려 했지만,
- Positive samples만 사용할 경우 인코더가 Augmentation을 무시하고 context-level의 representation을 만들어냄.
- 이를 방지하기 위해 전혀 다른 context를 가지는 이미지를 가져와 Negative Samples로 삼는 분류문제로 전환한 것임.
-
하지만, 이를 위해서는 많은 Negative Samples이 필요하며, 적절한 Augmentation 방법이 개발되어야 함.
-
기존 대조학습 방법들은 negative pair를 잘 선택해줘야 함.
-
이를 위해 customoized mining 전략 등이 제안됨.
-
많은 memory bank가 필요함
-
또한 굉장히 큰 batch size에서 학습을 시켜야 하고, 학습에 사용된 image augmentation option에도 성능 편차가 크다는 점 등 아직까지 안정적으로 학습시키기에 고려해야 할 요소가 많다는 문제점들이 있었음
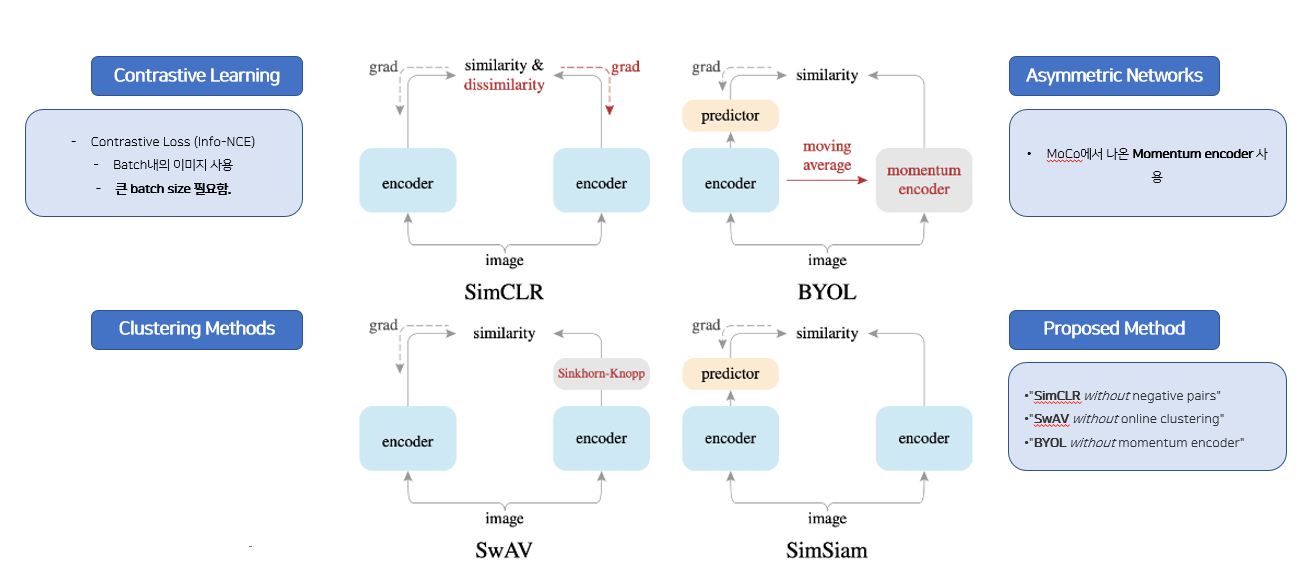
1. Bootstrap Your Own Latent (BYOL)
Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., ... & Valko, M. (2020). Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33, 21271-21284. (2661회 인용)
음의 쌍을 사용하면 생기는 문제
- 이러한 방법은 큰 배치 크기 [8, 12], 메모리 뱅크 [9] 또는 사용자 정의 마이닝 전략 [14, 15]에 의존하여 음의 쌍[13]을 신중하게 처리해야 함.
→ BYOL은 positive pair만 사용함.- 대조학습 방법 중에 미니 배치에서 Negative Samples를 도출하는 방법은 배치 크기가 줄어들면 성능이 저하됨.
→ BYOL은 Negative Samples를 사용하지 않으며, 그것이 더 작은 배치 크기에 더 robust할 것이라고 주장함.
배경
- image를 2개 사용하는 방식 대신, network를 2개 사용하는 방식을 떠올림.
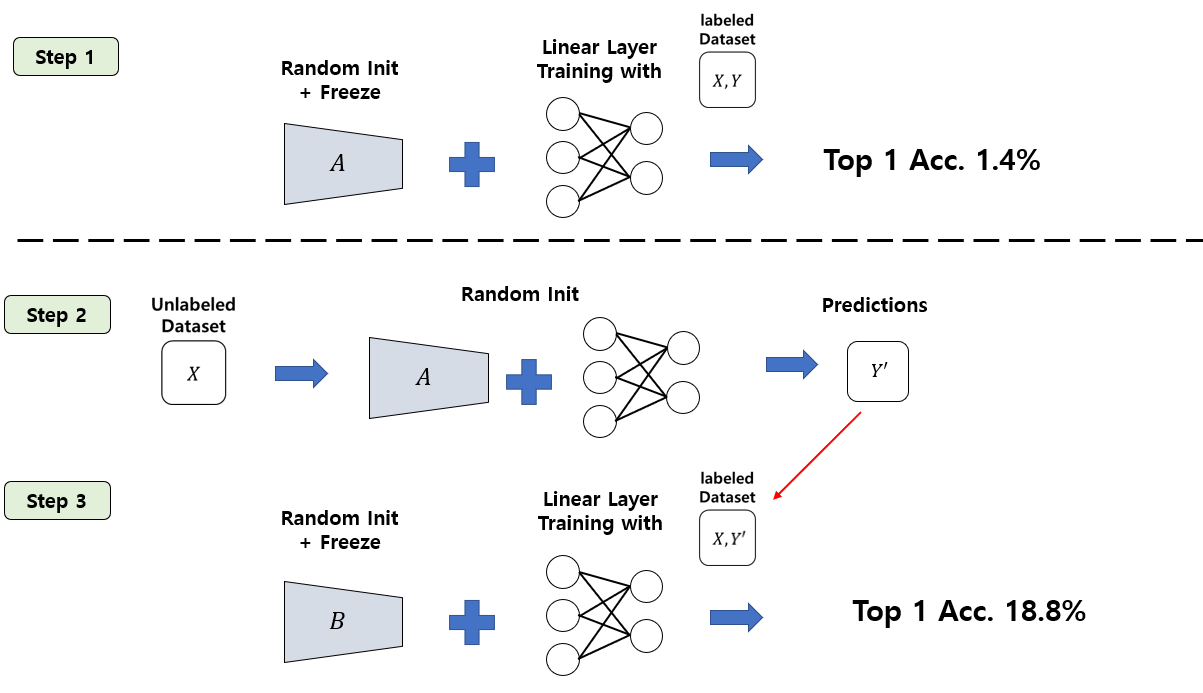
- Step 1으로 A라는 network를 random initialization 시킨 뒤 weight을 고정시킴.
- 여기에 Self-Supervised Learning의 evaluation protocol인 linear evaluation protocol을 통해 ImageNet 데이터셋에 대한 정확도 측정함.
- 즉, random init후 freeze 시킨 feature extractor에 1개의 linear layer를 붙여서 ImageNet 데이터셋으로 학습시킨 뒤 정확도를 측정.
- 이 경우 feature extractor가 아무런 정보도 배우지 않은 채 linear layer만 붙였기 때문에 좋은 성능을 얻을 수 없고, 1.4%의 정확도 달성함.
-
Step 2로 unlabeled dataset을 random initialized A network + MLP에 feed forward 시켜서 prediction들을 얻어냄.
-
Step 3에서는 B라는 network를 하나 준비함.
-
B도 random initialization 시키는데, 바로 linear evaluation을 수행하지 않고, image들을 A network에 feed forward 시켜서 뽑아낸 prediction을 target으로 하여 이 target을 배우도록 학습시킴.

-
놀랍게도, B network는 A network가 내뱉은 부정확한 prediction들을 배우도록 학습한 뒤 linear evaluation을 하였을 때 18.8%라는 높은 성능을 얻음. (큰 폭으로 성능 증가함)
[참고] https://hoya012.github.io/blog/byol/
2. Variance-Invariance-Covariance Regularization for Self-Supervised Learning (VICReg)
Bardes, A., Ponce, J., & LeCun, Y. (2021). Vicreg: Variance-invariance-covariance regularization for self-supervised learning. arXiv preprint arXiv:2105.04906. (247회 인용)
음의 쌍을 사용하면 생기는 문제
- 큰 배치 크기를 필요로 함.
-> ViCReg는 Negative comparisons을 제거하고, 분산에 대한 명시적인 제약으로 대체하며 벡터 사이에서 음의 항의 역할을 효율적으로 수행함.
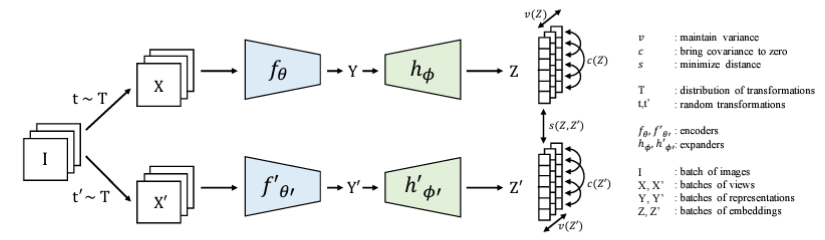
[feature space에서 어떻게 유사도를 비교하려 했던 거지?]
-
서로 다른 이미지로부터 나온 representation은 다를 것이고, 같은 이미지에서 augmentation된 것은 유사할 것이다.
-
feature의 각 dimension끼리도 서로 연관이 없어야 한다.
-
즉, 이 벡터를 구성할 때 하나 하나 특징 요소들이 서로간의 관련이 없어야, 좀 더 분별력이 있는 특징만을 갖고 있을 것이다.
-
이러한 목적으로 새롭게 목적함수를 정의하고 feature에서 불필요한 정보를 제거하는 것이 redundancy reduction 방법론임.
-
그 중 VICReg가 대표적인 것.
-
regularization term을 이용해서 loss로 줘서 explicit한 constraint를 주고, 위의 그림 참고
Main idea (1). Variance regularization
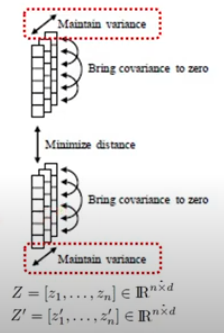
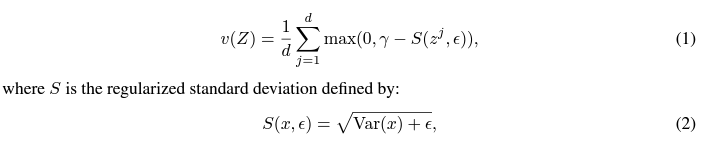
- projector를 지나고 나온 벡터 Z는 nxd 차원을 가지게 됨.
- 한 배치 내에 각 차원의 분산이 유지되게 하는 것
- 샘플 내의 하나의 차원의 분산을 유지하도록 하는 constraint 준다.
- 실험에서는 gamma라는 target value에 맞게 유지되도록 하는 constraint이기 때문에 1로 고정함.
- 각 차원의 표준편차가 너무 작으면, 해당 요소는 되게 작은 범위내에서만 표현될거고, 다른 특징에 비해서 분별력이 떨어질 수 있음
- 따라서, 명시적으로 target gamma(=1)값만큼 표준편차는 유지되도록 해주었고, 이게 collapsed representation을 방지할 수 있음.
Main idea (2). Covariance regularization
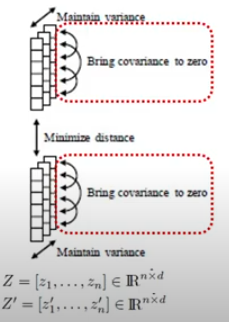

- 한 배치 내에서 projection vector들의 공분산 행렬을 구하고, 그 공분산의 대각선 요소를 제외하고 나머지 것들 요소들이 0의 값으로 수렴하도록 constraint를 주는 것
- 어떤 두 벡터나 특징 차원을 갖는 것들의 공분산 행렬을 구함.
- 행과 열에 각각의 벡터가 나열되어 있는 것이고, 벡터의 각 요소끼리의 관계성을 공분산 행렬이 나타냄.
- 그때 대각선 요소는 지들끼리의 분산만 나타내고, 대각선 요소 말고 다른 부분은 서로 간의 연관관계를 나타내고, 이들의 절댓값이 커지면 양 또는 음의 방향으로 관계를 가진다.
- 이들을 0으로 하는 것이 목적이므로, 서로 간의 관계를 끊겠다는 목적!
Main idea (3). Invariance regularization
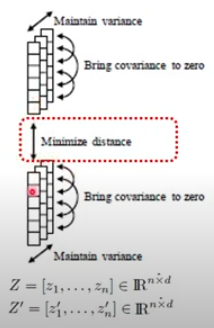

- 같은 이미지 샘플로부터 augment된 프로젝터들이 서로 가깝게 해주기 위함
- 위 그림도 같은 이미지에서 나온 다른 augmentation 애들을 의미함.
장점
-
negative pair 없이도 학습이 가능함
- variance regularization term의 효과로
- 다른 contrastive learning 방법(SimCLR, SwAV)에 비해 작은 배치 사이즈로도 안정적인 성능 보임
-
설명되지 않던 부분을 ablation study를 통해 보여줌.
-
공분산, 분산, 불변에 대한 것만 regularization term을 주었는데, 추가적인 redundancy reduction을 추가할 동기가 있었다.
-
공분산 행렬의 계산을 줄이기 위한 방법 언급
3. Exploring Simple Siames Representation Learning (SimSiam)
Chen, X., & He, K. (2021). Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 15750-15758).(1512회 인용)
음의 쌍을 사용하면 생기는 문제
- 음의 쌍까지 고려하는 것은 모델의 복잡성을 높임.
-> SimSiam은 positive pair만으로도 학습이 가능한 간단한 모델이며, 성능도 뛰어남.
관련 논문리뷰
https://bo-10000.tistory.com/157
