📌 [KDD 2021] A Transformer-based Framework for Multivariate Time Series Representation Learning
😎 Transformer가 표현 추출하기에 제일 좋아 ❗ ❗

-
<Unsupervised pre-training과 Supervised fine-tuning> 과정으로 이루어짐.
-
unsupervised pre-training을 통해 representation을 학습할 수 있는 모델인 Transformer 사용함.
-
Transformer의 multi-head attention을 통해 시계열의 multiple periodiciteis를 학습함.
-
Representation 추출을 위해 Masking 기법을 사용함.
-
Transformer로 표현 추출하는 것이 다양한 downstream task에 사용되는 데 도움이 된다고 함.
- Transformer를 사용하는 것의 장점에 대해 19p에서 언급함.
-
'예측'을 이용한 Representation 추출
📌 [ICLR 2022 (spotlight)] Anomaly Transformer: Time Series Anomaly Detection with Association Discrepency
😎 Context류의 Anomaly Detection도 중요해 ❗ ❗
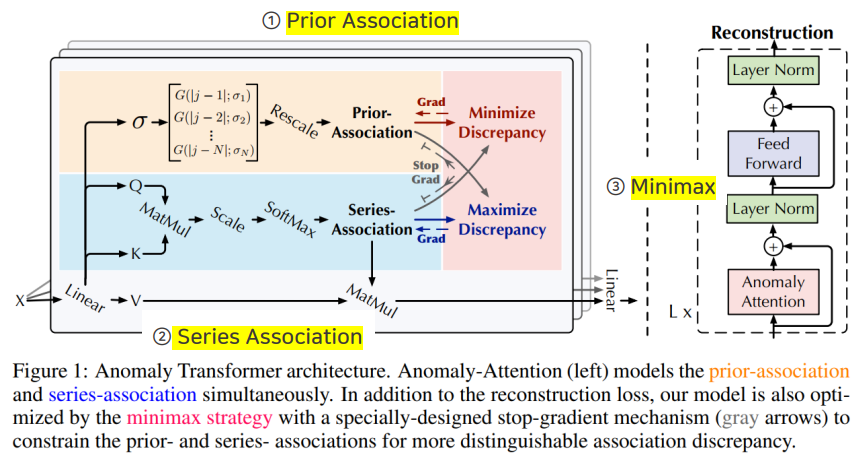
-
이상치는 rare하기 때문에, 전반적인 시계열에 약한 상관관계 (association)을 가짐. [global]
-
하지만, 인접한 영역에 대해서는 강한 상관관계 (association)을 가짐 [local]
-
이러한 이상치의 특징으로, association 기반 normal과 abnormal point를 구분하고 Association Discrepancy라고 함.
-
Association Discrepancy는 time point와 prior assocation과 series asscociation의 거리(= 유사도의 반대 개념) 사용함.
-
local한 정보를 사용하는 prior association은 가우시안을 활용하고, global한 정보를 사용하는 series association은 attention을 활용함.
-
최종적인 Association Discrepancy가 포함된 Loss식을 최적화하기 위해 Minimax Strategy를 활용함.
-
'복원'을 이용한 Representation 추출
😀 "결론"
- 데이터의 분포를 직접적으로 사용하기 때문에, 유사한 형태의 정상과 이상을 구분하는데 효과적인 방법일 거라 생각됨.
- 논문에서도 Normal과 Abnormal의 차이를 극대화하기 위해 최종 loss term에 Association Discrepancy Term 추가
-> Anomaly-Attention 모듈 가져와서 사용하면 좋을듯- 대부분의 Loss에 예측/복원 정확도를 추가하는 듯함.
- 논문에서도, 복원을 잘할수록 이상이 더 높은 anomaly score를 갖는다고 언급함.
- 가장 큰 Contribution은 다양한 유형의 이상치를 모두 탐지할 수 있다는 점임.
- (참고) NeurlPS-TS (NeurlPS 2021 Time Series Benchmark), 2021 데이터셋
📌 [IJCAI 2021] Time-Series Representation Learning via Temporal and Contextual Contrasting
😎 시계열 대조학습으로 Representation Learning 진행한 근본 논문 ❗ ❗
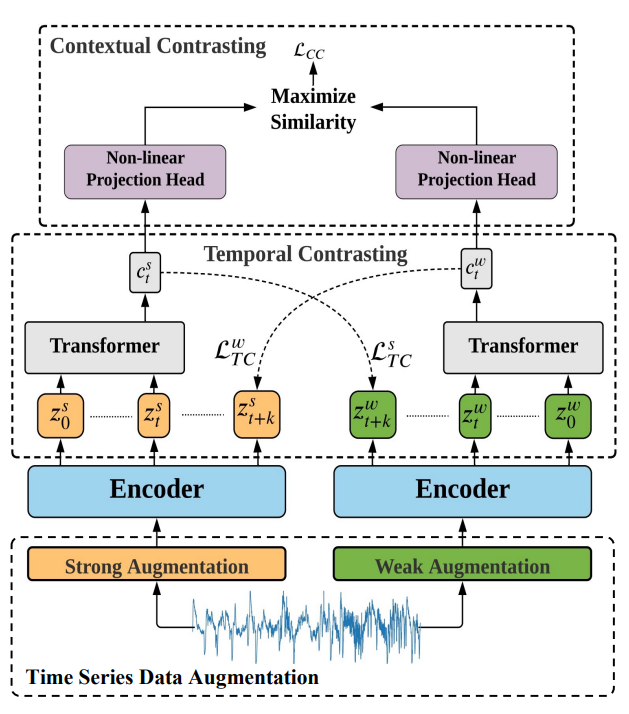
- TS-TCC는 모델의 generalization을 위해 모든 시계열 데이터에 적용 가능한 간단하고 효과적인 augmentation 기반 contrative learning을 활용함.
-
weak/strong augmentation을 적용한 결과를 활용하여 representation을 학습할 수 있는 아래 두 모듈을 제안함.
- Temporal contrasting: cross-view prediction task를 통해 모델이 robust time series representation을 학습하도록 함
- Contextual contrasting: context vector에 대한 contrastive loss를 통해 모델이 discriminative time series representation을 학습할 수 있도록 함.
-
Temporal과 Contextaul관점에서 시계열 데이터 분석
-
'예측'을 이용한 Representation 추출
😀 "결론"
- 여기서도 Transformer 사용함
- Robustness를 원하면, Strong Aug와 Weak Aug 사용해보면 좋을듯
- Ablation Study 결과로는, Robust 뿐만 아니라 성능에도 영향을 끼침 (하지만, 데이터셋마다 차이가 있음)
- 간단하면서 일반화를 타겟으로 한 것이 배울 점이라고 생각함.
- 단순화하면, (예측 + 대조학습) 틀에 Weak Aug & Strong Aug 활용한 것임!
📌 [NeurlPS 2022] Self-Supervised Contrastive Pre-Training for Time Series via Time-Frequency Consistency
😎 시계열은 Time 뿐만 아니라 Frequency에도 정보가 많아 ❗ ❗
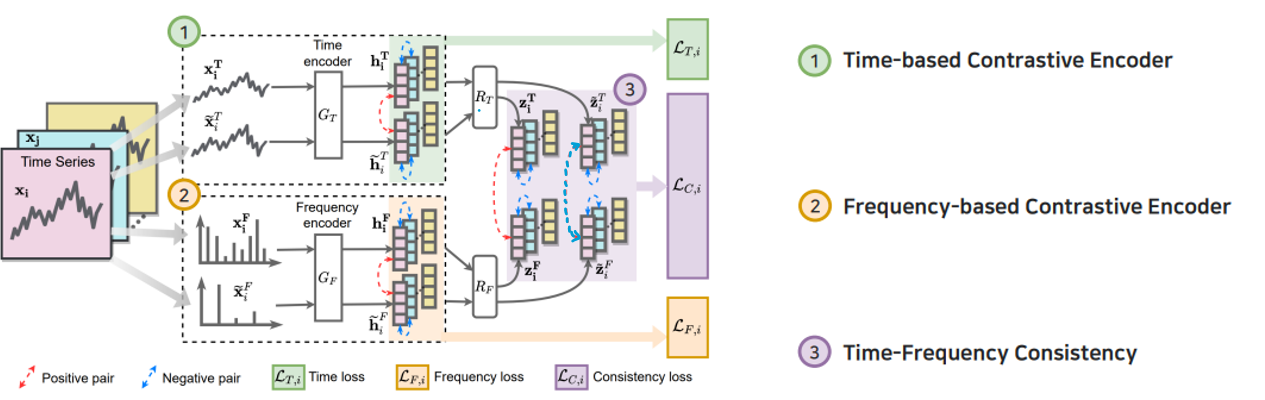
-
학습된 time-based 및 frequency-based representation이 다른 샘플의 representation보다 time-frequency 공간에서 더 가깝도록 지정
-
위와 같이 풍부한 스펙트럼 정보를 활용하고, 시계열에서 time-frequency consistency를 탐색
-
Encoder → Conv1D를 3개 쌓은 구조 (time, frequency 둘 다)
-
Data Augmentation → Jittering, Scaling, Permutation와 같은 기본적인 Aug 기법 사용함
-
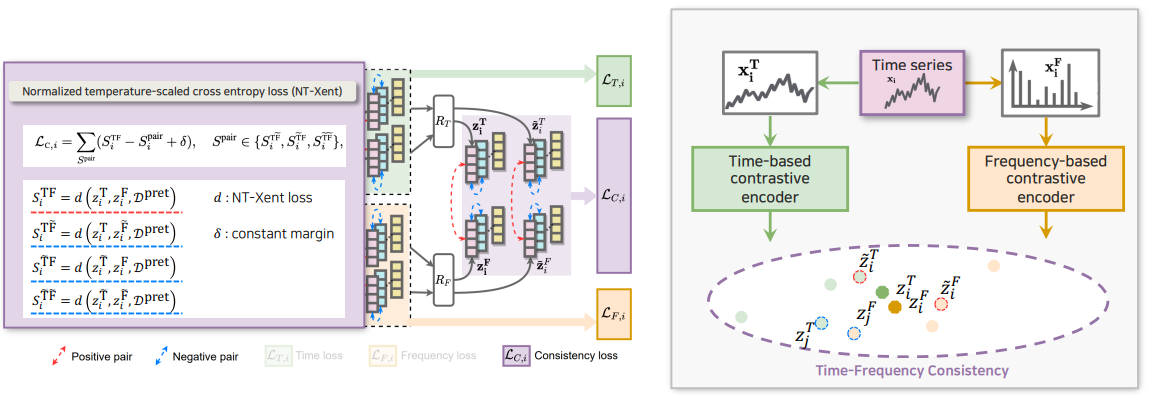
Contrastive Loss → SimCLR에서 사용한 NT-Xent 사용함
-
8가지 Frequency Augmentation Strategy에 대한 성능 비교 실험
-
Time-Frequency Consistency
😀 결론
- 일반적인 Representation Learning보다 Transfer Learning에 더 초점을 맞춤
- 논문에서 우수하다고 입증된 Frequency Augmentation 방법 사용하면 좋을듯
- time과 Frequency를 하나의 embedding space에 넣는 것이 인상깊었음. (서로 다른 형태를 띄고 있을 텐데)
- 실험적으로도 consistency의 실효성을 입증함.
- Future directions에도 언급이 되어 있지만, downstream task가 classification에 초점이 맞춰진 embedding 전략이라고 함.
-> Embedding 전략에 따라 적합한 downstream task가 있다는 걸 알게 됨
-> Forecasting은 local context까지 학습하는 embedding이 필요하고, Classification은 global information을 학습하는 embedding으로도 충분함.
-> 저자는 Classification task에 Anomaly Detection도 포함시켰는데, AD 성능을 높이기 위해 더 잘 구분되게 하는 추가적인 기법을 적용하면 좋을 듯함.- 다른 논문들에서 보이는 예측/복원 기반 Loss가 없음
-> 추가 모듈로 도입하는 방안 생각해보기
🤔 생각할 점
- contrastive loss를 계산할 때는 같은 데이터에서 Augmentation되면 positive pair 취급했는데, Consistency Loss에서는 Aug끼리 Negative Pair로 보는 게 맞는지
- 대조학습 loss만으로 학습하는 것은 한계가 있다는 논문 결과가 많으므로, Reconstuction loss 같은 추가 loss가 도입되면 좋을듯함
📌 [Information Sciences 2022] Contrastive autoencoder for anomaly detection in multivariate time series
Information Sciences IF : 8.233
😎 Attention, 2가지 접근의 대조학습, Time과 Freq의 Siamese Encoder ❗ ❗
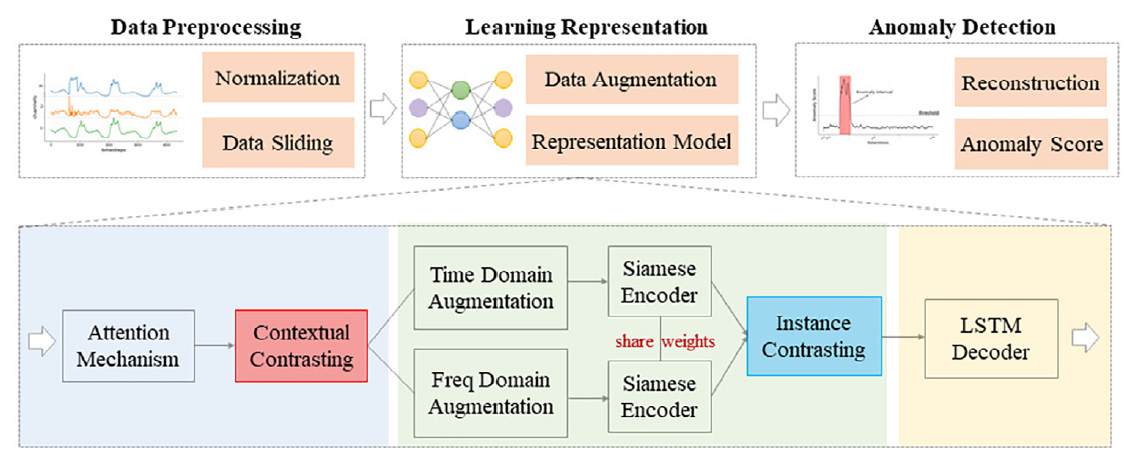
-
비지도 다변량 시계열 데이터의 표현 추출이 목표임.
-
다변량 데이터 표현 추출은 1. Temporal dependency 2. Dynamic variability 특징을 학습하는 것이 중요함.
-
대조학습 Loss는 robust한 representation 추출에 도움을 주고, MSE Loss는 재구성 정보의 세부적인 학습에 도움을 줌,
-
단, CSE-AD는 학습시 정상 데이터만을 사용함.
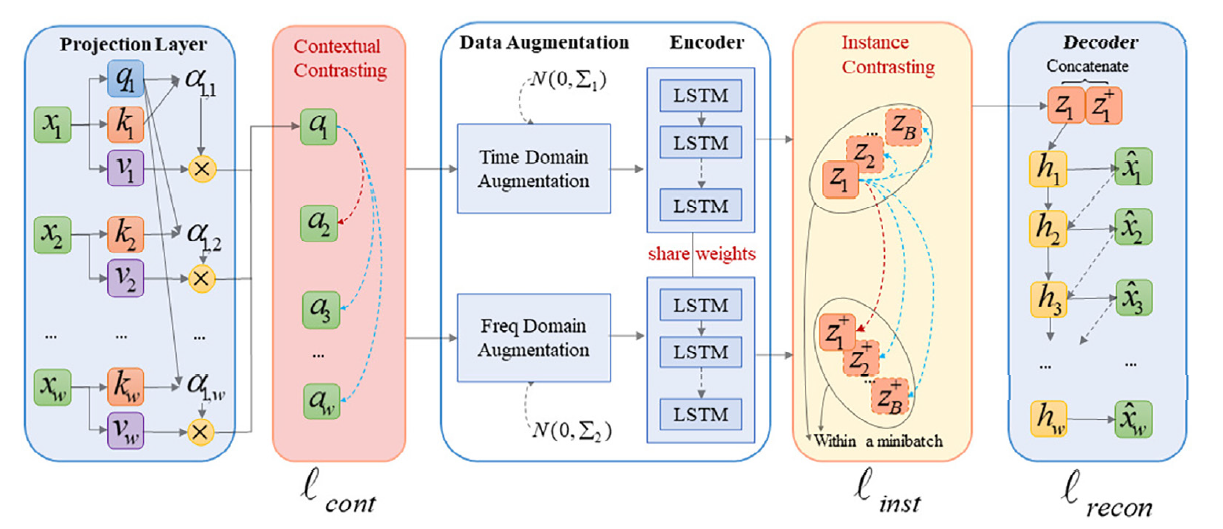
- 따라서 CAE-AD 모델은 크게 5가지 기법을 도입함.
- Attention mechanism → temporal dependency
- Contextual contrasting method → position information
- Augmentation in the time and frequency domain → different views of the same segment
- LSTM Shared-weight encoder →
- Instance contrasting method → local invariant characteristics of latent variables
😀 결론
- Transformer의 positional encoding하는 기법에서 위치를 sin/cos값 더하기로 표현하는 것에 의문이 있었는데 이를 대조학습으로 새롭게 접근함.
→ 바로 옆 시점의 embedding 가 가장 높은 유사도 가진다는 주장할 만한 근거가 부족해 보임
→ 하지만 실험적으로 증명되긴 함.
🤔 생각할 점
- Simese encoder에 대해 알아봐야 할듯
- 서로 다른 데이터를 하나의 Encoder로 학습시키는 게 맞는건가?
→ 근데 다른 논문에서도 T와 F에 대해서 하나의 Embedding 공간에서 학습시킴.- 하나의 Encoder에서 나와서 Time과 Freq가 구분없이 로 들어가는 건가? 구분을 안해도 되나?
- decoder의 구조도 어떤 모델을 따온건지, 밑도 끝도 없이 걍 이렇게 한다 설명만 있음
- 변수간의 관계 학습되는 거 맞나?
- 적절한 Augmentation 기법인가?
❗ 전체적인 결론 ❗
- 다변량 데이터의 representation 추출의 핵심은 변수간/변수내 특징 추출인 것 같은데
-> 변수들간의 관계를 고려하는 방법이 드물어 보임.
