[2021 IJCAI] Time-Series Representation Learning via Temporal and Contextual Contrasting
Paper review
목록 보기
13/21
Abstract
- 라벨이 없는 시계열 데이터에서 적절한 representation을 학습하는 것은 중요함.
- 비지도 시계열 표현학습 TS-TCC을 제안함.
- 서로 다르지만 상관성 있는 관점으로 보기 위해 → 원본 시계열에 weak/strong aug
- 강건한 temporal 표현을 학습하기 위해 → cross-view prediction task
- discriminative 표현을 학습하기 위해 → contextual contrasting
- 결과적으로 분류, few-labeled, transfer learning 시나리오에서 좋은 성능을 보임.
1. Introduction
- 라벨 부족 등의 이유로 Self-supervised learning 등장
- pretext tasks ex) solving puzzles
- pretext task는 일반성이 떨어진다는 한계점 있음
- 회전시킨 이미지를 분류하는 것은 색깔이나 물체의 위치 등의 특징을 해칠 수 있음.
- Contrastive Learning 등장
- augmented data로부터 invariant representation 학습
- 그러나, image-based constrastive learning은 시계열 데이터에 적합하지 않음.
- temporal dependencies를 다룰 수 없음.
- color distortion과 같은 augmentation tech는 시계열 데이터에 적합하지 않음.
- 본 논문에서는, 시계열 데이터에 적합한 대조학습을 사용해 robust한 representation을 추출하고자 함.
3. Methods
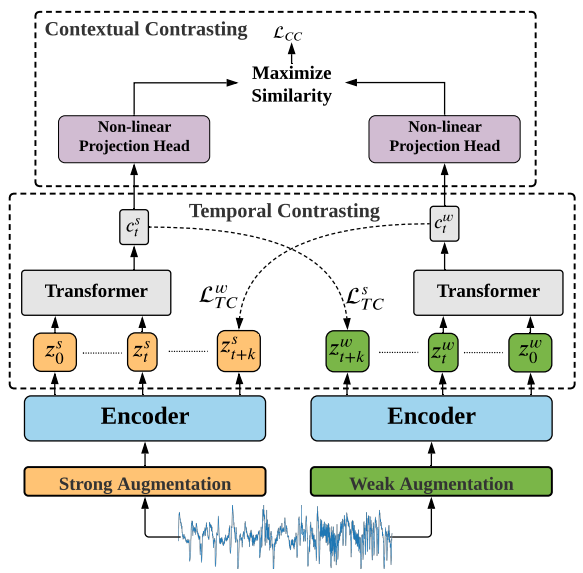
3.1. Time-Series Data Augmentation
" 서로 다른 augmentations는 학습된 표현의 robustness를 향상시킬 것이다. "
1. weak augmentation → jitter-and-scale strategy
2. strong augmentation → permutation-and-jitter strategy
3.2. Temporal Contrasting
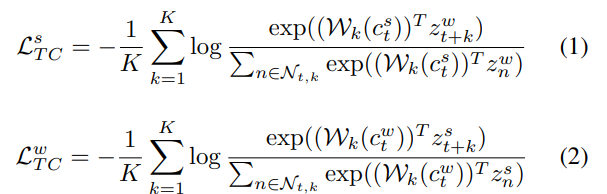
- latent representation z가 주어졌을 때, autoregressive model은 를 context vector 로 요약함.
- 이 context vector 는 부터 까지의 timestep을 예측함.
- 단, 본 논문에서는 strong augmentation의 context vector를 weak augmentation에서 나온 z 예측을 위해 사용
- 즉 cross-prediction 전략 사용함.
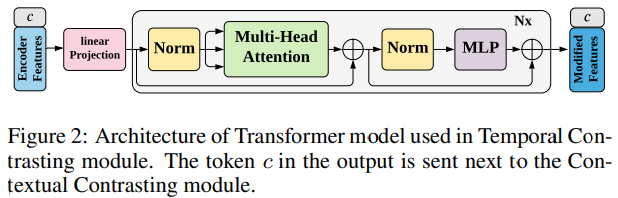
- 효율성과 속도를 위해 transformer의 encoder 사용함.
- Multi-Head Attention 사용 후, MLP block으로 사용함.
- MLP block은 two fully-connected layers with a non-linearity ReLU function and dropout으로 구성됨.
- stable gradient를 위해 pre-norm residual connection 사용함.
- BERT model에서 차용해, token c를 input에 더함
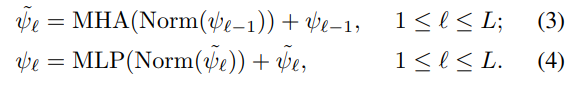
3.3. Contextual Contrasting
- positive pair와 negative pair를 정의함.
- 같은 데이터에 strong aug 적용한 context, weak aug 적용한 context를 양의 쌍으로 정의함.
- 나머지 쌍을 음의 쌍으로 정의함.
- 양의 쌍끼리는 가깝게, 음의 쌍끼리는 멀게 학습하도록 손실함수 구성
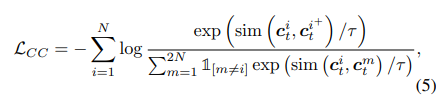
[최종 Loss]
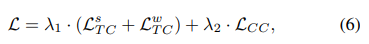
4. Experimental Setup
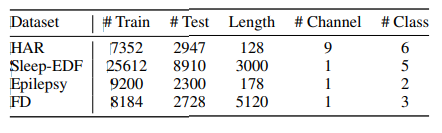
- Human Activity Recognition (HAR)
- Sleep Stage Classification
- Epilepsy Seizure Prediction
- Fault Diagnosis (FD) -> trasnferability 평가
5. Results
5.1. Comparison with Baseline Approaches
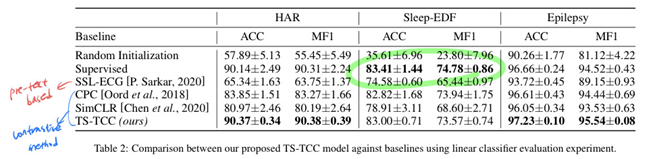
(1) Random Initialization: 랜덤 초기화된 encoder + linear classifier
(2) Supervised: supervised encoder + supervised classifier
(3) SSL-ECG: pretext-learning → 대조학습으로 invariant features를 잘 학습함.
(4)-(6): contrastive learning → temporal features 학습의 중요성
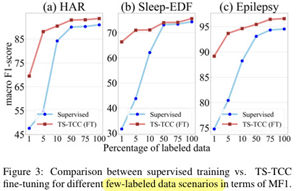
5.2. Semi-supervised Training
: pretraining with few labeled samples -> fine-tuning
5.3. Transfer Learning Experiment
: train on source domain -> test on target domain

5.4. Ablation Study
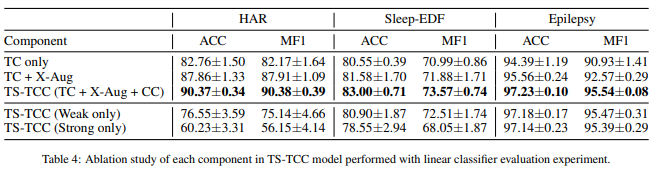
(1) TC: Temporal Contrasting module (cross-view prediction task X)
(2) TC + X-aug : TC module with cross-view prediction task
*Epilepsy 데이터는 augmentation 하나라도 좋은 성능을 보임.

to be data scientist