[2022 Information Sciences] Contrastive autoencoder for anomaly detection in multivariate time series
Paper review
목록 보기
14/21
Abstract
- MTS의 dependencies와 dynamics를 파악하기 힘듦.
- multi-grained contrasting methods를 사용한 CAE-AD 제안
- temporal dependency를 파악하기 위해 → contextual cotrasting method
2.time-domain and frequency-domain data augmentation- local invariant 특징을 학습하기 위해 → instance contrasting method
1. Introduction
- 비지도 학습을 이용한 MTS에서의 이상 탐지를 목적으로 함.
- 하지만, temporal dependency and dynamic variability 때문에 어려움을 겪음.
- 본 논문에서는, MTS에서의 이상 탐지를 위한 contrastive autoencoder를 제안함.
- 대조 학습은 다양한 도메인에서 transformation-invariant representation을 학습함.
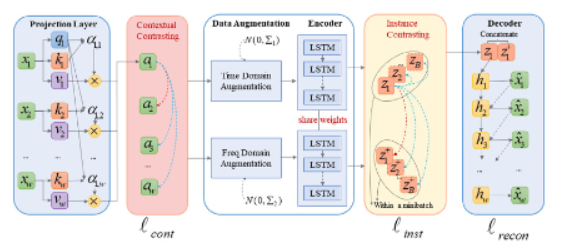
3. Methods
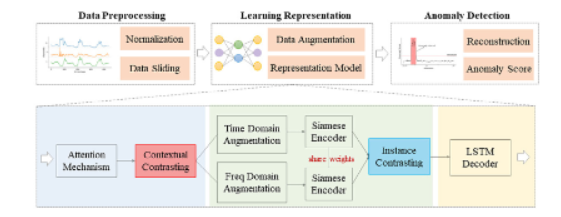
3_1. Preprocessing
normalization -> sliding window (temporal dependency 파악을 위해)
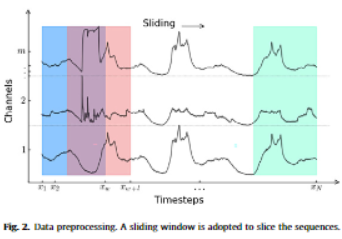
3_2. Projection Layer
- 기존 시계열 augmentation을 위해서는 cropping, flipping, jittering 같은 방법이 사용됨.
- 그러나, 이는 시계열의 특성을 해칠 수 있기에, 적절하지 않음.
- 따라서 projection layer를 사용함.
- 또한 temporal dependency를 파악하기 위해 projection layer로 attention mechanism을 도입함.
- 이때 마스킹을 통해 미래 값을 가려줌.
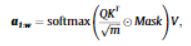
3_3. Contextual Contrasting
- attention mechanism을 거치고 나온 embeddings는 position information을 포함하지 않음.
- 따라서 position information을 포함하기 위해, contextual contrasting을 제안함.
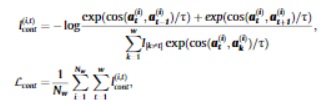
- embedding 는 이웃 타임스텝인 과 과 높은 유사성이 있을 것이라는 가정하에 진행
3_4. Data Augmentation
[Time Domain]
- Gaussian noise를 더함.
[Frequency Domain]
- 2차원 DFT를 수행한 후, amplitude spectrum 과 phase spectrum 각각에 Gaussian noise를 더함.
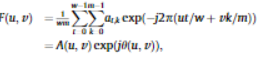
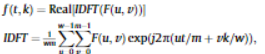
3_5. Instance Contrasting
- 증강된 데이터가 LSTM siamese encoder로 전달됨.
- 이후 같은 window에 있는 데이터는 positive pair로, 다른 window에 있는 데이터는 negative pair로 대조학습 진행
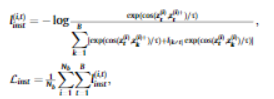
3_6. LSTM Decoder
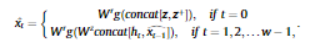
- 처음에는, latent variables를 concat한 뒤 LSTM cell에 적용함.
- 이후부터는, (t-1)시점에 재복원된 데이터와 t시점의 hidden state를 concat하여 사용함.
[최종 Loss]
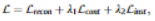
4. Experiments
[데이터 설명]

[성능 평가]
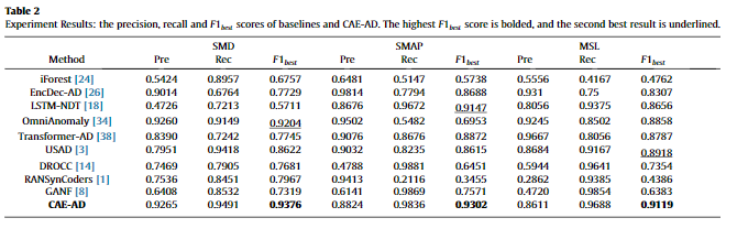
[이상 탐지 성능 평가]
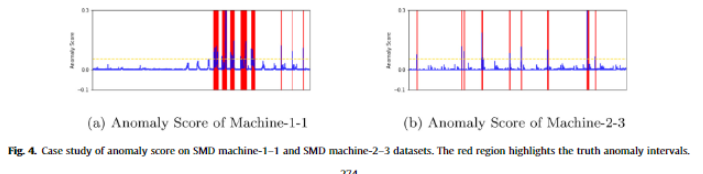
[Ablation Study]
: contextual contrasting과 instance contrasting의 효과 입증

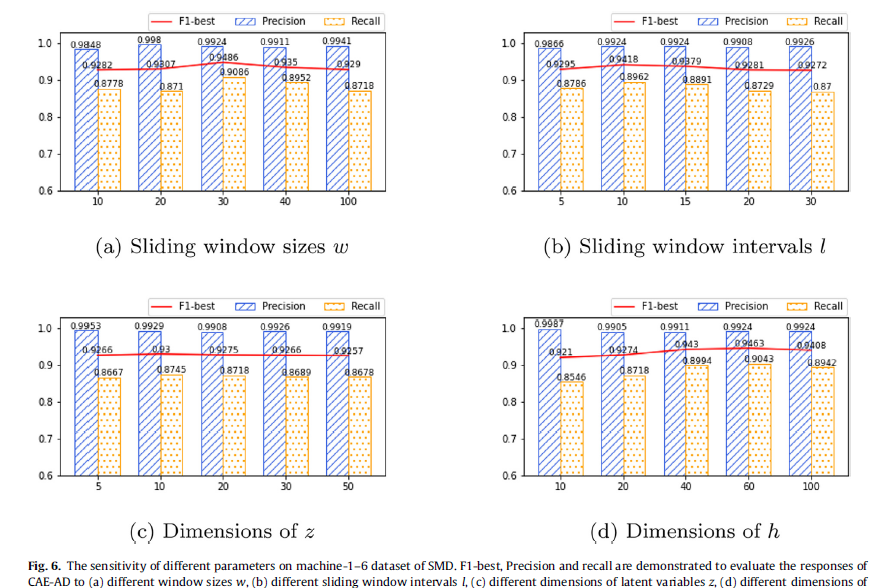
[Parameter Sensitivity]
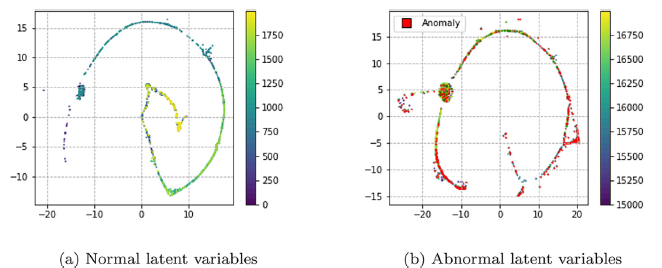
[Visualization]
5. Discussion
- MSE loss가 이상치에 민감함 -> 따라서 대조학습이 invariant information을 학습할 수 있는 것임.
- 그렇다면 contrastive loss만 사용하는 것이 충분할까?
- 와 간의 mutual information는 강한 상관관계가 있기 때문에, 가 positive sample로 잘못 분류될 수 있음.
- MSE Loss를 추가함으로써 이를 해결할 수 있음.
- 즉, contrastive loss만으로 정상 패턴을 학습하기에 충분하지 않음.

to be data scientist