Paper review
1.[2020 International Journal of Forecasting] DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Abstract Probabilistic forecasting: 주어진 과거 데이터를 기반으로 미래 시계열 값의 확률 분포 예측 DeepAR은 auto-regressive recurrent network model을 사용하여 정확도 높은 Probabilistic for
2.[2020 preprint] Multivariate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows

Abstract 다변량 시계열 예측에서는 변수간의 독립성을 가정함. 하지만 변수간의 통계적 의존성을 모델링하는 것은 정확도를 향상시킴. > 그러나 다변량 모델에서 종종 단순한 parametric 분포를 가정하고 고차원을 다루지 않음. > 따라서 본 논문에서는 조건부 n
3.[2020 대한산업공학회] 반도체 계측 데이터 기반 군집화를 활용한 개선된 품질 예측 방법론
\\반도체 제조공정 순서실리콘 잉곳(Ingot)에서 얻은 원형의 웨이퍼(Wafer)에서 시작해FAB(Fabrication) 공정에서 반도체 회로 형성프로브 테스트(Probe Test) 및 패키지 테스트(Package Task) 공정에서 특성을 테스트하여 정상인지 판단패
4.[2020 대한산업공학회] 반도체 패키지 검사 공정의 데이터 변화 감지를 통한 불량 예측 모델의 갱신

패키지 테스트를 거치고도 제품에 결함이 발견되는 경우 있음.이러한 문제를 보완하기 위해 최종 단계에서 각 로트(lot)로부터 표본을 추출하여 패키지 품질 보증 검사(package quality assurance)를 진행함.패키지 품질 보증 검사는 고객의 요구에 따라 다
5.[2021 Confluence] Workload Prediction over Cloud Server using Time Series Data
1. Introduction 클라우드 제공자는 다음 시간대의 workload를 조정하기 위해 computing resources를 예측하는 것이 중요함 따라서 시계열 분석을 하면 클라우드의 traffic data의 패턴을 파악할 수 있음 시계열 분석은 다양한 분야에서
6.[2021 한국정보과학회] SVR을 이용한 가상머신 자원 이용률 예측 기법의 성능 분석
클라우드 컴퓨팅: 컴퓨팅 리소스를 인터넷을 통해 서비스로 사용할 수 있는 주문형 서비스일정 수준 이상의 자원 이용률은 서비스 수준 계약을 위반하고, 낮은 자원 이용률은 에너지 효율성 및 수익 감소로 이어짐따라서 최적의 자원 이용률을 유지하는 것은 중요하고 이를 위한 동
7.[2019 IEEE transactions on cybernetics] Recurrent Reconstructive Network for Sequential Anomaly Detection
Abstract 이상탐지에서는 imbalanced sample distribution으로 어려움을 겪기 때문에, one-class classification이 널리 사용되고 있음. 최근에는 RAE(recurrent autoencoder)가 sequential anoma
8.[2022 ICML] Iterative Bilinear Temporal-Spectral Fusion for Unsupervised Representation Learning in Time Series
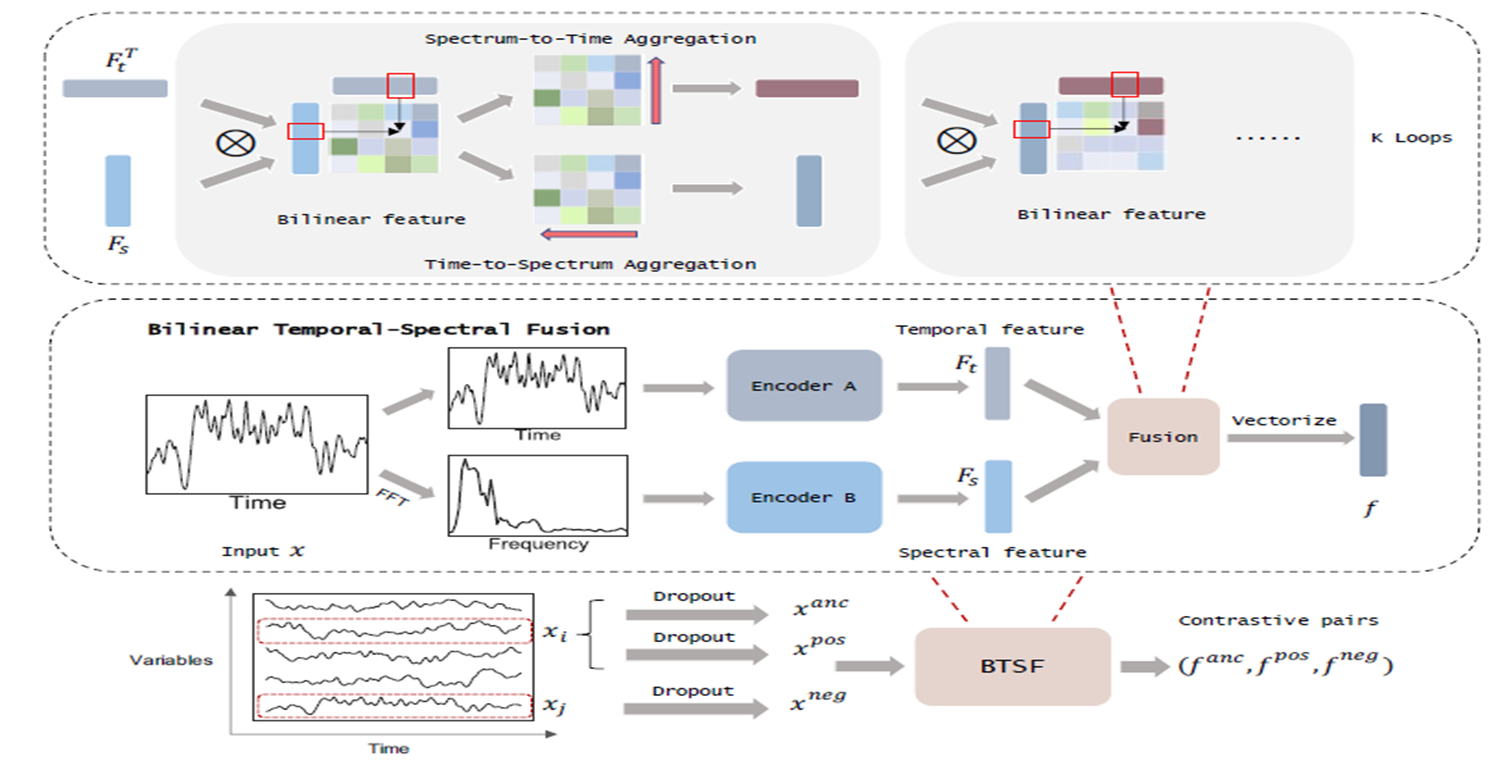
Abstract 다변량 시계열 데이터를 위한 비지도 표현학습은 어려움 Complex Dynamics Sparse Annotations 그래서 보통 data augmentation을 활용해 positive/negative sample을 만들고 contrastive
9.What are Diffusion Models?

Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.잠재 변
10.[2022 PMLR] Domain Adaptation for Time Series Forecasting via Attention Sharing (8회 인용)
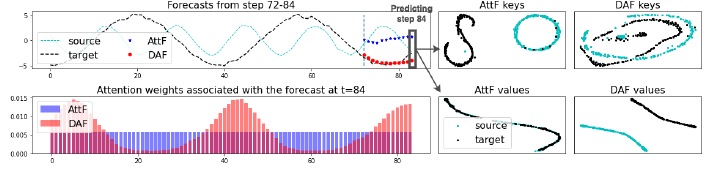
시계열 예측 모델의 효과는 충분한 양의 데이터가 있는 경우에만 나타남. 따라서 데이터 부족 문제에 대처하기 위해 새로운 Domain Adaptation 프레임워크인 DAF(Domain Adaptation Forecast)를 제안함. DAF는 풍부한 데이터 샘플(Sour
11.[2017 CVPR] Adversarial Discriminative Domain Adaptation (3867회 인용)
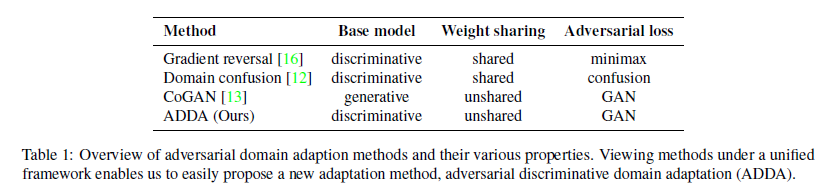
\-> robust한 네트워크 훈련 가능\-> 복잡한 샘플 생성 가능\-> domain distribution간의 차이 줄일 수 있고, 일반화 가능함.\-> 설득력 있는 시각화 보여주지만, 작은 shift만 다룰 수 있음.\-> 큰 shift를 처리할 수 있지만, 모델
12.[2020 Signal Processing] Multi-Layer Domain Adaptation Method for Rolling Bearing Fault Diagnosis
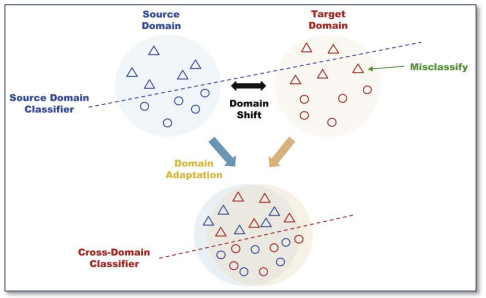
1) 기존 고장 진단을 위한 방법은 훈련과 테스트 데이터가 동일한 분포를 따른다는 가정 하에 수행됨. \- 그러나 실제 상황에서는 Domain-Shift 때문에 해당 가정이 성립하지 않음. \- 이는 일반화 능력을 저하시킴. 2) 타겟 도메인에서 유효한 레이블
13.[2021 IJCAI] Time-Series Representation Learning via Temporal and Contextual Contrasting
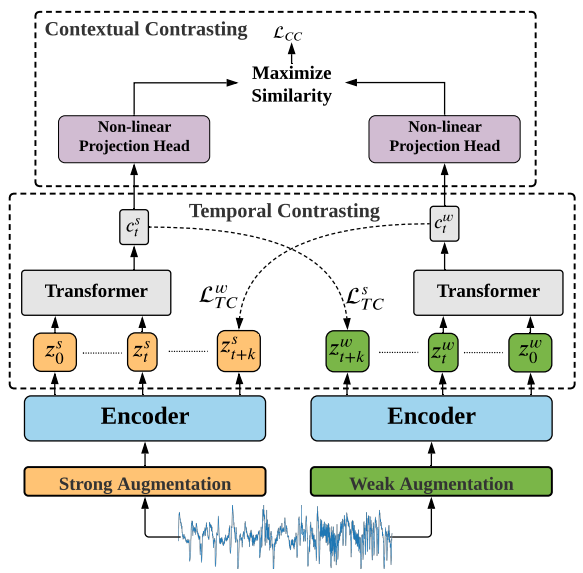
라벨이 없는 시계열 데이터에서 적절한 representation을 학습하는 것은 중요함. 비지도 시계열 표현학습 TS-TCC을 제안함. 서로 다르지만 상관성 있는 관점으로 보기 위해 → 원본 시계열에 weak/strong aug강건한 temporal 표현을 학습하기 위
14.[2022 Information Sciences] Contrastive autoencoder for anomaly detection in multivariate time series
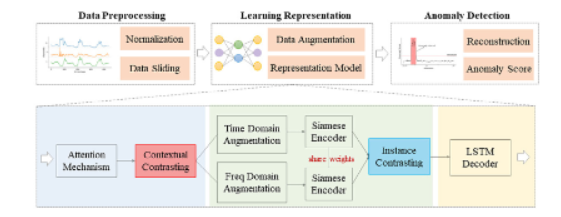
MTS의 dependencies와 dynamics를 파악하기 힘듦.multi-grained contrasting methods를 사용한 CAE-AD 제안temporal dependency를 파악하기 위해 → contextual cotrasting method 2.tim
15.[2022 CVPR] Selective-Supervised Contrastive Learning with Noisy Labels (52회 인용)
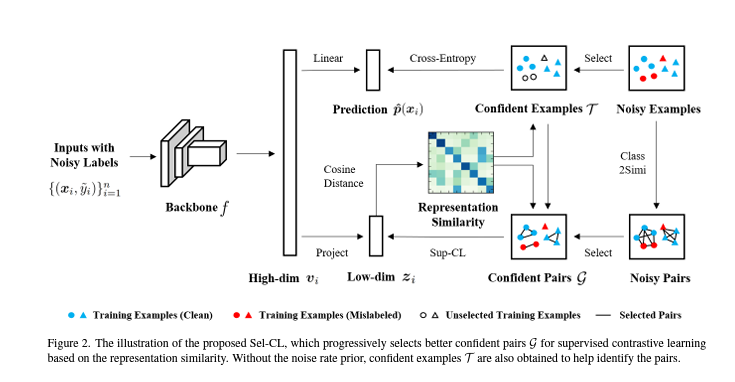
Abstract고품질의 라벨을 획득하는 것은 비용이 많이 듬노이즈가 있는 라벨은 잘못된 표현을 학습할 수 있고, 일반화 성능이 하락함.따라서 robust한 표현을 학습하고 노이즈가 있는 라벨을 다루기 위해서 Selective-Supervised Contrastive L
16.[2020 NeurlPS] Time series Anomaly Detection using Temporal Hierarchical One-Class Network
THOC : Deep SVDD와 Dilated RNN을 기반으로 timeseries anomaly detection에서 SOTA 성능을 도출한 모델 Dilated RNN을 기반으로 short/long term 정보를 포함한 multiscale temporal featu
17.[2022 ICML] Iterative Bilinear Temporal-Spectral Fusion for Unsupervised Representation Learning in Time Series (23회 인용)
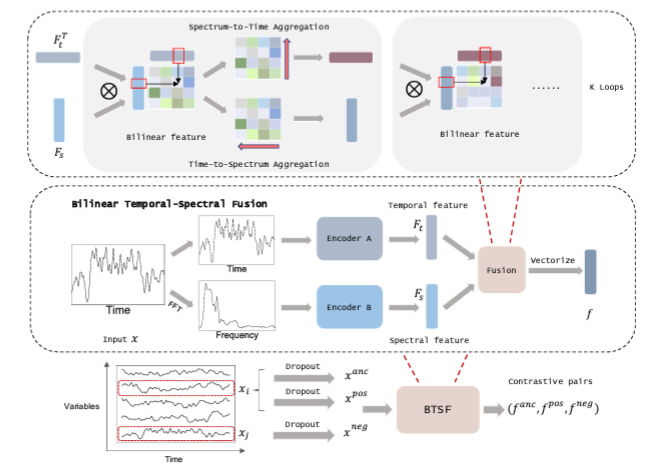
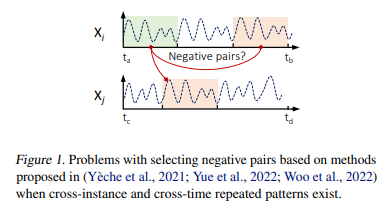
Abstract다변량 시계열 데이터를 위한 비지도 표현학습은 어려움 1\. Complex Dynamics 2\. Sparse Annotations그래서 보통 data augmentation을 활용해 positive/negative sample을 만들고 contra
18.[2023 preprint] SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting (2회 인용)
Abtract대조학습을 시계열 예측에서 사용하고자 함또한 positive pair와 negative pair를 정의하는데 일반화된 기법이 없음본 논문에서는 잠재 공간에서 과거로부터 미래를 예측하는 방법을 학습하여 시계열 예측을 개선하기 위한 간단한 표현 학습 접근법인
19.[2023 CVPR] MaskCon: Masked Contrastive Learning for Coarse-Labelled Dataset
Abstract대규모 데이터셋을 정확하고 효율적으로 주석을 다는 것은 비용이 많이 들고 어려움. coarse 라벨들은 전문가의 지식을 요구하지 않기 때문에 더욱 얻기 쉬움. 따라서, 더 미세한 라벨링을 위해 coarse 라벨을 사용하는 Masked Contrastive
20.[2022 AAAI] N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
📌 [AAAI 2022] N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting 😎 해석가능한 시계열 예측 모델 구조 ❗ ❗ 긴 길이를 예측하는 것은 1. 예측 값의 변동성 2. 계산 복잡도
21.[2018 preprint] An empirical evaluation of generic convolutional and recurrent networks for sequence modeling
1. TCN Bai, S., Kolter, J. Z., & Koltun, V. (2018). An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. ar