[2019 IEEE transactions on cybernetics] Recurrent Reconstructive Network for Sequential Anomaly Detection
Paper review
Abstract
- 이상탐지에서는 imbalanced sample distribution으로 어려움을 겪기 때문에, one-class classification이 널리 사용되고 있음.
- 최근에는 RAE(recurrent autoencoder)가 sequential anomaly detection에서 좋은 성능을 보임.
- 하지만 RAE는 long-term dependency 문제가 있고 fixed-length input만 사용할 수 있다는 한계점이 있음
- RAE의 한계점을 극복하기 위해, RRN(recurrent reconstructive network)를 제안함
(1) a self-attention mechanism
(2) hidden state forcing
-> 다양한 길이의 input sequence를 활용할 수 있음
(3) skip transition
-> reconstruction performance를 향상시킴
3. Proposed RRN Model
A. Self-Attention Mechanism
- RAE에서 sequence길이가 길어질 수록 하나의 context-vector에 모든 정보를 다 담는것이 부담이 되고 성능도 하락함
- 그래서, Attention mechanism 도입!!
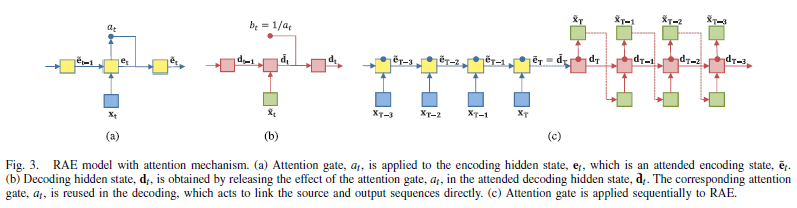
[기존]
- decoding hidden state d_t가 encoding hidden state와 관련있는 것을 찾는 것
- 그리고 d_t를 어떻게 연결할 건지 학습함
- 여기서 context vextor c_t가 모든 encoding hidden states와 연결되고, d_t로부터 각각의 encoding hidden state와의 연결 강도가 학습됨.
- 이 과정에서 attention score가 사용되고 이 지표는 encoding hidden stae와 d_t가 얼마나 관련있는지를 뜻하고, shortcut path로 행동함
[제안]
- 우선 target sequence와 input sequence의 길이는 같고 반대의 순서로 놓음
- 상응하는 hidden state d_t와 e_t사이 하나의 connection만 필요함
- 즉, attention gate의 score이 e_t만으로 결정되어, 일반적인 attention mechanism의 오리지널 함수를 유지하며 모델의 복잡성을 낮춤
- 이 self-attention은 decoder의 target sequence를 재구성하기 위한 정보 전달을 하기 때문에 필수적임
- attention gate 식은 (9)와 같고 w는 scalar value를 얻기 위한 weight vector임.
- 기존 encoder의 모든 hidden state와 계산을 하는 방식이 아닌, Fig3처럼 sequential하게 계산함.

- d_t는 (12)식과 같이 encoding에 적용된 attention 효과를 제거함으로써 얻어짐.
-> attention gate를 공유함으로써 접근가능한 nodes의 개수가 증가했고, 이는 long-term dependency 문제를 완화함.
-> attention gate가 shortcut역할을 하기 때문에, sequence길이에 상관없이 long-term dependency 문제를 완화함.
-> 기존 하나의 context vector에 모든 정보를 함축해야 했던 것의 부담을 덜어줌
-> attention gate를 share함으로써, input sequence의 local featuers에 접근 가능하게 하고 input sequence 길이에 관계없이 robust한 output을 생산할 수 있게 됨
B. Hidden State Forcing
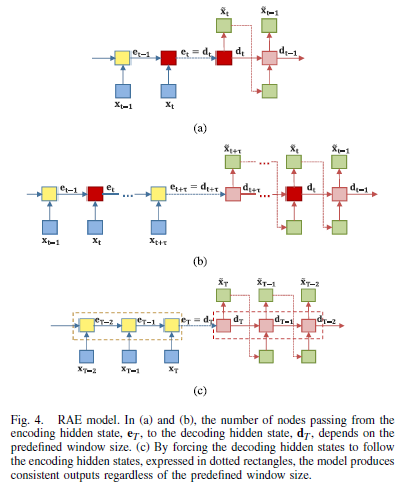
- 실제 시계열 데이터를 사용하려면 사용자정의 윈도우 사이즈로 segment하는 것이 불가피함.
- 또한 서로 다른 윈도우 사이즈를 사용할 때마다 output이 크게 다름
(dT와 d(T+t)-t) - input의 window size가 달라도 일관된 output을 얻기 위해서는, decoding hidden state의 dT와 d(T+t)-t가 같은 값을 가져야 함!
- 그래서 Professor forcing 도입!!
[Professor forcing]
: Discriminator가 free running/teacher forcing에서의 hidden state의 분포인지 구분하지 못하게 학습
1) Free Running: 이전 time step의 output이 현재 time step의 input으로 사용
2) Teacher forcing: ground truth(정답)을 input으로 사용
=> Free Running + Teacher forcing = Professor Forcing
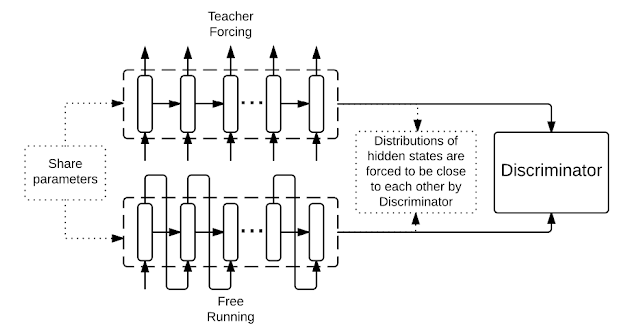
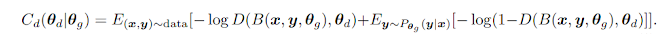
- 원래 Professor Forcing을 진행하기 위해서는 FR과 TF가 연결되는 추가적인 네트워크가 필요한데 이 모델에서는 encoding과 decoding hidden states가 연결되어 있기 때문에 필요없음.
- Reconstruction error function은 다음과 같음
- L_0는 reconstruction error이고, L_h는 hidden state forcing과 관련된 error임.
- L_h를 더함으로써 window size의 변동성에 robust함.
- L_h의 t'은 selected hidden state pairs의 개수임.
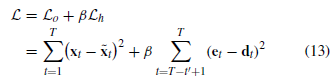
C. Skip Transition With Attention Gate
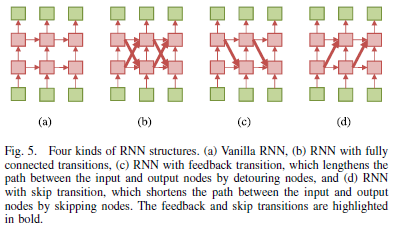
(b): detour와 shortcut path가 둘다 있음
(c): feedback transition인 detour path
(d): skip transition인 shortcut path
- input과 output의 길이가 길어지면 vanishing/exploding gradient problem이 발생하기 때문에 skip transition 도입.
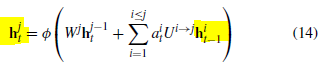
- 위 식에서 a는 h_t-1의 attention gate로 h_t-1에서 h_t로 이동하는 정보량을 조절하는 것임.
- 최종적으로 attention gate와 함께 사용하는 skip transition을 제안함.
- detour path를 사용하지 않은 3가지 이유
1) 복잡한 connection이 항상 성능 향상을 이끄는 것은 아님
2) 정보 흐름의 길이를 늘려 ineffective 전달이 포함되면 학습에 어려움을 겪음
3) path가 늘어남에 따라 불필요한 정보가 전달될 수 있음
4. Sequential Anomaly Detection
RRN: sequential data 처리를 위한 AE
1) Training
normal data로만 학습
2) Validation
normal data로만 검증
- validation dataset에서 나온 에러값들 e_t들로 추정된 Gaussian distribution N(평균, 분산)
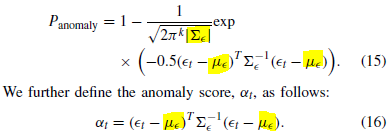
3) Test
anomaly threshold를 정해서 이보다 큰 것은 anomaly로 판단
5. Experiment
- Dataset: ECG(심박수), Gesture(동작), Power Demand(전력 소비), Space Shuttle(셔틀 운행 엔진)
- 사용자 정의 window size 사용해서 segment함
A. Experimental Setting
- five-fold cross-validation using normal data를 통해 validation data에서 평균 재구성 오차가 가장 작게 나온 parameter 사용
- window size=64, regularization=variational dropout
- train할 때, 평균이 0이고 분산은 error of validation set의 분산과 같은 Gaussian noise 분포를 더함.
- control paramter 베타는 reconstruction error가 오르는 순간인 0.1로 설정함
- target data는 noisy-free original input data로 설정함
- hidden state forcing을 적용할 레이어는 top8개로 설정함
- Adam optimizer 사용하고 learning rate은 10^-3으로 설정함
[평가]
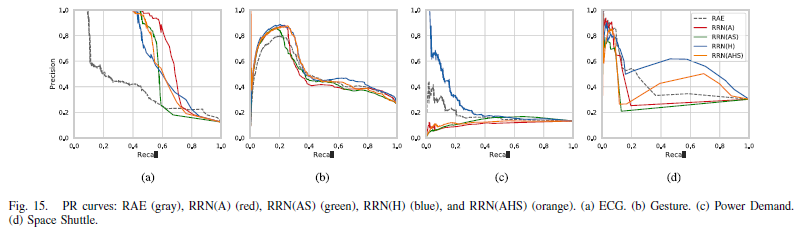
- anomaly threshold를 바꿔가면서 precision-recall(PR) curve를 그림
- area under curve(AUC)와 F-measure로 성능 평가
- 아래 식에서 파라미터는 0.1과 1로 설정함
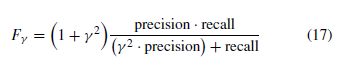
[비교모델]
모든 window size는 동일하게 64
- K-means clustering
- 50% overlapping- 10 clusters
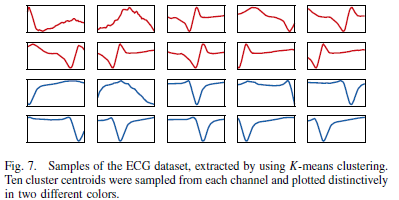
- 10 clusters
- DTW
- RAE
B. Experimental Results
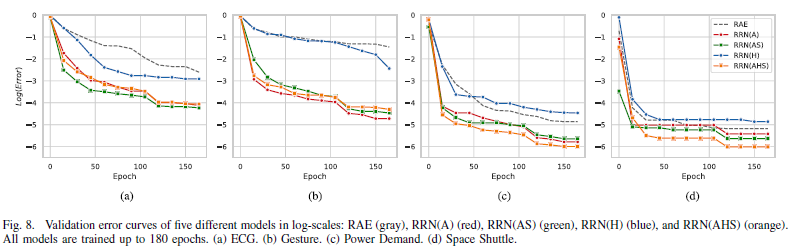
-> RRN이 RAE보다 정확도도 높으며 더 빠른 속도로 학습됨.
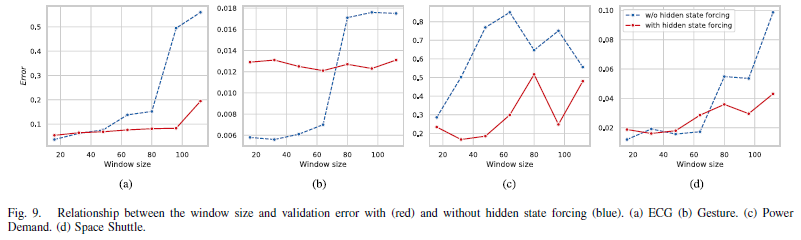
-> hidden state forcing technique를 사용한 RRN(H)는 비교적 window size의 변화에 robust함.
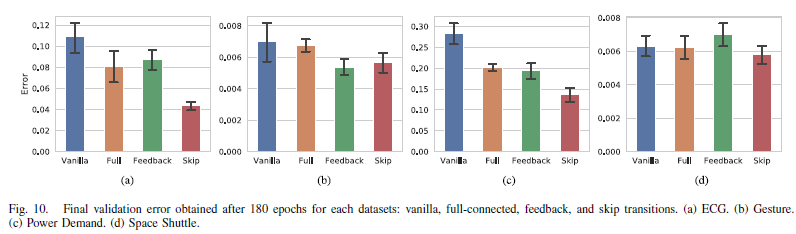
-> Skip transition이 가장 성능을 향상시킴
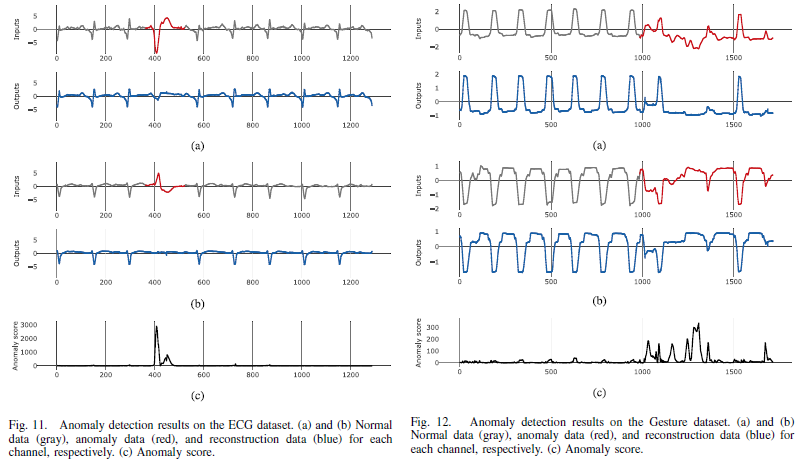
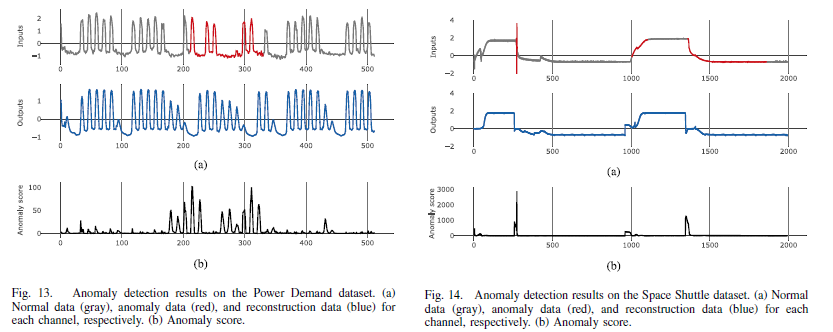
-> ECG와 Space Shuttle dataset같이 dynamic하지 않은 데이터에서도, Gesture와 Power Demand와 같이 dynamic한 데이터에서도 이상을 잘 탐지함.