1. 서론
- 클라우드 컴퓨팅: 컴퓨팅 리소스를 인터넷을 통해 서비스로 사용할 수 있는 주문형 서비스
- 일정 수준 이상의 자원 이용률은 서비스 수준 계약을 위반하고, 낮은 자원 이용률은 에너지 효율성 및 수익 감소로 이어짐
- 따라서 최적의 자원 이용률을 유지하는 것은 중요하고 이를 위한 동적 자원 관리가 필수적임.
- 동적 자원 관리에는 사전 예방적 방법과 사후 대응적 방법이 있는데, 보통 사전 예방적 방법이 선호되며 과거의 자원을 이용하여 예측을 진행함.
- 본 논문에서는 SVR 알고리즘을 사용하고 실험은 다양한 데이터 크기, 자원 유형 및 매개변수 설정 하에 이루어졌으며 예측 정확도, 강건함(robustness), 소요시간으로 성능 비교를 함.
2. 연구 배경
2.1. ARIMA
ARIMA(p,d,q)
p는 자기회귀(AR)의 차수, d는 원 시계열에 대한 차분 변환 적용 횟수, q는 이동평균(MA)의 차수를 의미함.
2.2. SVR
구조적 위험 최소화 관점에서 최적인 초평면(hyperplane)의 분류 경계면을 찾고자 한 SVM을 회귀 문제 풀이에 적합한 형태로 개조한 알고리즘.
- 학습 데이터를 고차원 특징 공간으로 mapping시킨 후 내적하는 과정을 kernel function을 이용하여 수행함
- 이를 통해 계산량을 줄이고 비선형 회귀식을 얻을 수 있음
2.3. 관련 연구 및 연구 동기
[기존 연구들]
ARIMA, LSTM-RNN 기반 예측 모델, GRU-ES 등 하이브리드 모델
[연구 동기]
기존 방법론 외에 커널 방법론에 속하는 SVR 기법이 가상 머신 자원 이용률에서도 우수한 예측 성능을 보이는지 확인하기 위함.
[연구 방법]
Bitbrain, PlanetLab, Google Cluster Workload Traces 데이터를 기반으로 호스트 자원 이용률을 시물레이션하여 실험 진행, 5분 주기로 기록된 데이터의 10일 분량으로 학습을 진행하고 1일 분량의 데이터에 대해 예측 작업을 수행함.
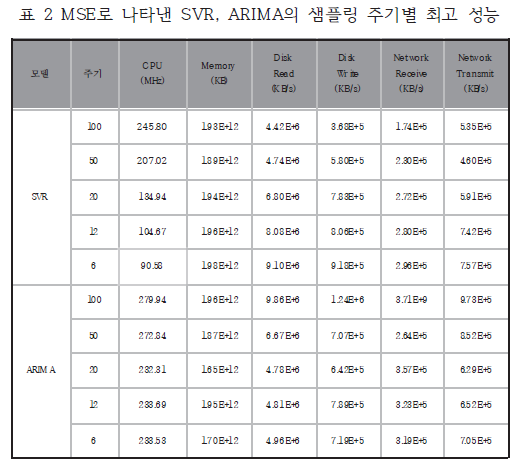
3. 실험
3.1. 매개변수 설정

3.2. 실험 결과 비교 및 분석
- 예측 정확도
- 표2에서는 ARIMA 모델과의 예측 성능이 크게 차이가 나지 않는 것처럼 보임.
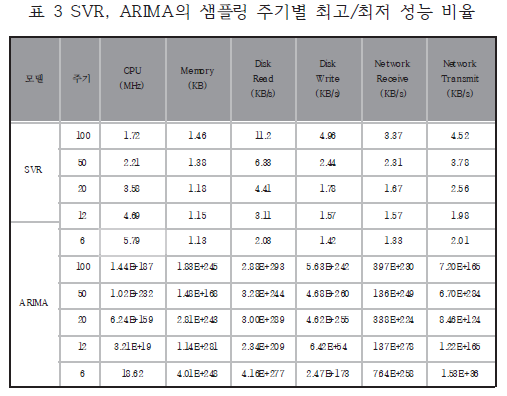
- 강건함(robustness)
- 하지만 표3에서는 ARIMA의 성능과 크게 차이가 나는 것을 확인할 수 있음.
- 또한 SVR은 샘플링 주기가 짧아질수록 최대/최저 성능 비율이 감소하는 양상을 보임. -> 이는 SVR자체가 구조적 위험 최소화를 통한 일반화 성능 최대화를 목표로 설계된 모델임을 알 수 있음.
-> 또한 주기가 짧아지고 더 많은 데이터로 학습한 결과 더욱 강건한 예측 성능을 보인 것으로 해석 가능함.
- 소요시간
- 주기 100에서 SVR의 소요 시간은 98.9초, ARIMA는 864.7초로 큰 차이를 보임
- 이는 SVR이 비교적 큰 규모의 데이터에 대해서도 소요 시간의 급격한 증가 없이 동일 작업을 수행할 수 있음을 ㅡ이미함
4. 결론 및 향후 연구
- 더 강건한 예측 성능을 필요로 하는 경우 SVR 방법을 사용할 수 있을 것임
- 한계점
- 각각의 시계열에 대해 개별 모델을 만드는 방식임. -> 이는 새롭게 실행된 가상머신의 경우 자원 이용률 예측이 불가능함
- 그림1에서 보이듯이 자원 이용량 데이터에서는 급격한 증감패턴, 즉 스파이크가 산발적으로 나타남. -> 이러한 패턴이 처음 나타나는 경우 예측이 정확히 이루어지기 어려움.
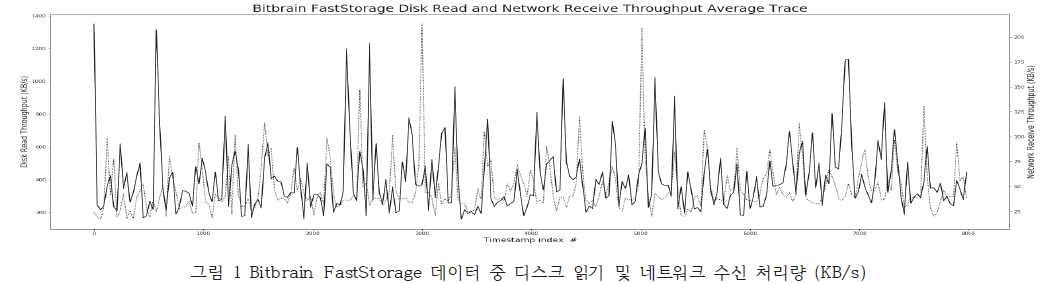
- 이러한 한계점을 해결하기 위해 제시된 DeepAR과 같은 딥러닝 기반의 시계열 알고리즘을 적용해 볼 예정임.

to be data scientist