🔰 공정 데이터 특성에 맞는 데이터 처리 방법 및 모델 정리
📌 [2017 IEEE TRANSACTIONS ON SEMICONDUCTOR MANUFACTURING] A Convolutional Neural Network for Fault Classification and Diagnosis in Semiconductor Manufacturing Processes
@FDC @CNN @Semiconductor Manufacturing Process
😎 1D CNN은 시간축에 따른 변수들의 특징을 잘 뽑아내 ❗❗
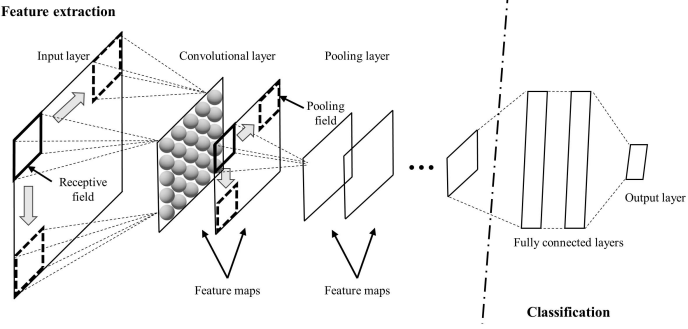
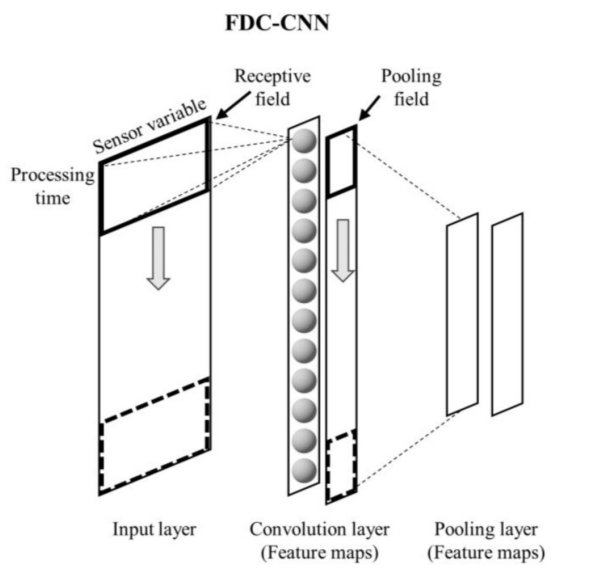
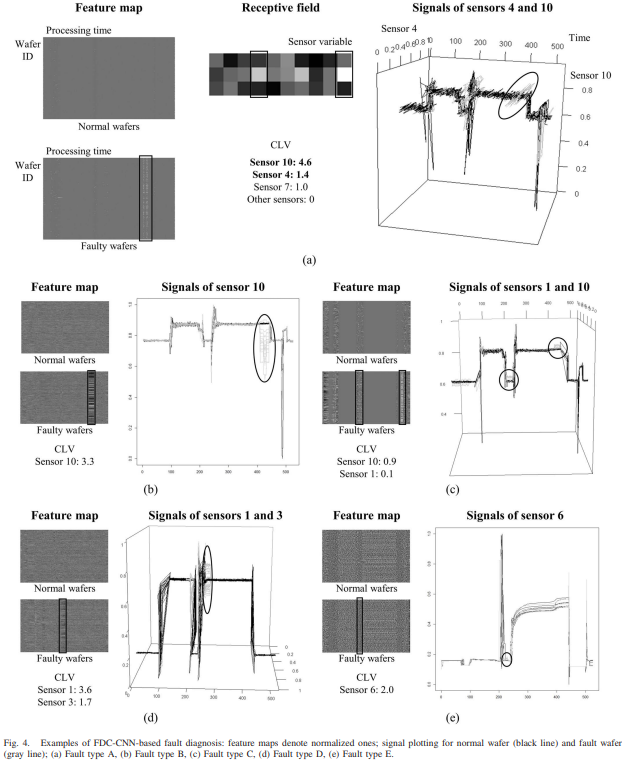
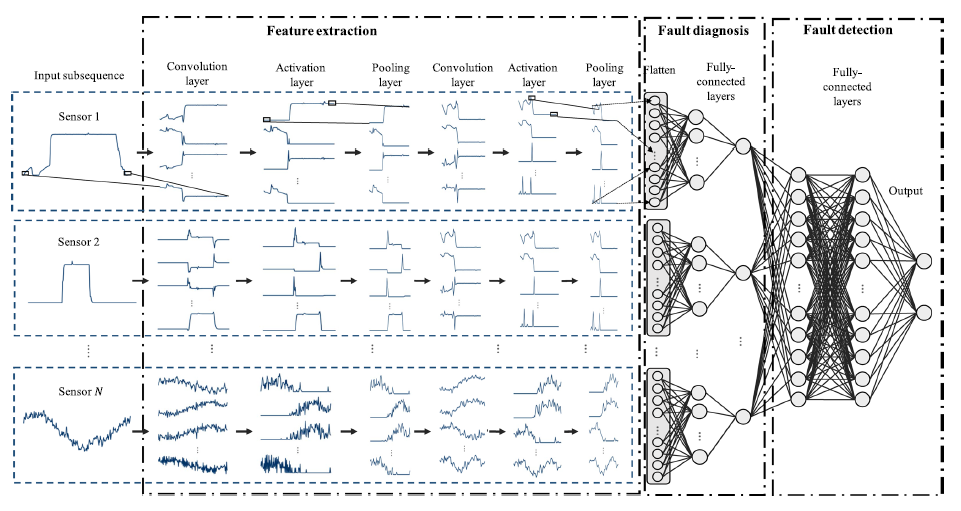
반도체 제조 공정을 위한 FDC(Fault Detection and Classification) 분야에서는 센서 신호를 이용한 제조 결과 예측에 대한 많은 연구가 진행되고 있다. 그러나 근본 원인에 대한 단서를 찾는 데 사용되는 결함 진단은 여전히 어려운 영역으로 남아 있다. 특히 신경망을 이용한 공정 모니터링은 블랙박스 모델이기 때문에 제한된 범위에서만 채용되어 입력 데이터와 출력 결과의 관계는 높은 분류 성능에도 불구하고 실제 제조 설정에서 해석하기 어렵다. 본 논문에서는 고장 특징을 추출하기 위해 다변량 센서 신호에 맞춘 수용 필드가 시간 축을 따라 미끄러지는 FDC-CNN(Convolutional Neural Network) 모델을 제안한다. 이 접근법은 첫 번째 컨볼루션 레이어의 출력을 원시 데이터의 구조적 의미와 연관시켜 프로세스 결함을 나타내는 변수 및 시간 정보를 찾는 것을 가능하게 한다. 화학 기상 증착 공정에 대한 실험에서 제안된 방법은 다른 딥 러닝 모델보다 성능이 뛰어났다.
-
Fault Diagnosis에서 근본 원인을 찾는 것은 어려운 일임.
-
따라서, convolutional neural network (CNN)을 사용한 FDC-CNN 모델을 제안함.
- 시간 축을 따라 receptive field를 적용하고 falut features를 추출함.
-
이는 첫번째 컨볼루션 레이어의 출력을 원본 데이터의 구조적 의미와 연관시켜 프로세스 결함을 나타내는 변수 및 시간 정보를 찾는 것을 가능하게 함.
-
Contribution level of variable (CLV)를 새롭게 정의함.
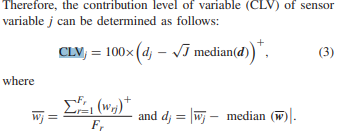
결론
- 그냥 1D CNN 썼다는 말인 거 같음
- Feature map, Receptive field를 시각화함으로써 설명력 제공함
📌 [2019 IEEE TRANSACTIONS ON SEMICONDUCTOR MANUFACTURING] Fault Detection and Diagnosis Using Self-Attentive Convolutional Neural Networks for Variable-Length Sensor Data in Semiconductor Manufacturing
@Fault detection, @fault diagnosis, @variable-length signal classification, @raw sensor data, @self-attentive convolutional neural networks, @semiconductor manufacturing.
😎 가변 길이의 시계열 고려한 방법❗❗
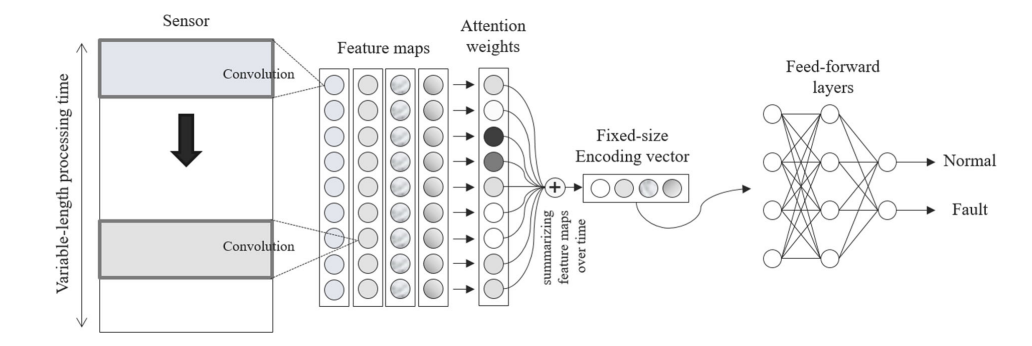
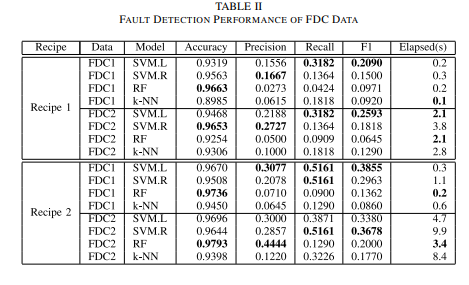
요즘 반도체 업계에서는 원가 절감과 수율 제고에 더 많은 관심이 쏠리고 있다. 제조 과정에서 고급 기계에 내장된 센서에 의해 상당량의 상태 변수 식별(SVID)이라는 센서 데이터가 수집된다. 이 데이터는 경쟁 우위를 유지하기 위해 초기 제조 단계에서 데이터 중심의 자동 고장 감지 및 진단을 위한 귀중한 자료입니다. 그러나 웨이퍼 처리 시간은 웨이퍼마다 약간씩 달라 가변 길이 신호 데이터가 생성됩니다. 기존의 접근 방식은 수동으로 설계된 기능 추출에 의해 만들어진 결함 감지 및 분류(FDC) 데이터라고 하는 압축된 데이터를 많이 사용한다. 또는 최근의 딥 러닝 접근법은 모든 웨이퍼가 동일한 처리 시간을 가지고 있다고 가정하며, 이는 가변 길이 SVID에 대해 무력하다. 가변 길이 SVID에서 직접 결함을 감지하고 진단하기 위해, 우리는 자가 주의 컨볼루션 신경망을 제안한다. 반도체 제조업체의 실제 데이터를 사용한 실험에서 제안된 모델은 더 적은 훈련 시간으로 다른 딥 러닝 모델보다 성능이 뛰어나고 서로 다른 시퀀스 길이에서 견고성을 보였다. FDC 데이터에 비해 SVID 데이터가 더 우수한 결함 검출 성능을 보였다. 긴 센서 신호를 수동으로 조사하지 않고 모델이 지정한 시간에 비정상적인 센서 값 패턴이 발견되었습니다.
-
기존 모델은 데이터를 동일한 처리 시간을 가지고 있는 데이터라고 가정하고 사용함.
-
따라서, 가변 길이 SVID에서 사용할 수 있는 self-attentive convolutional neural network를 제안함.
- 어떤 가변 길이 신호든 고정 크기 벡터로 인코딩함.
- Attention은 관련도 높은 시간에 더 초점을 맞출 수 있게 해줌.
-
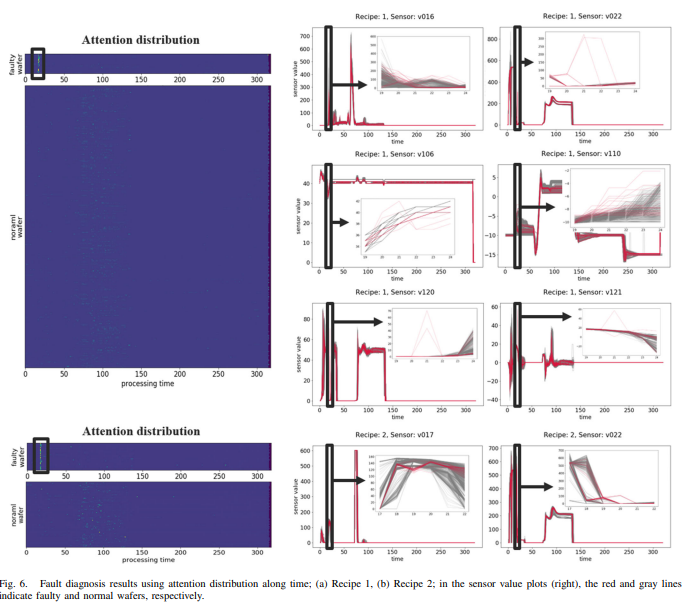
시각화 제시
-
반도체 제조 업체의 실제 데이터 활용함.
-
결과적으로, 더 적은 훈련 시간으로 학습이 가능하고, 다양한 시퀀스 길이에서 로버스트함.
-
또한 위 2017 논문에서 제안한 CLV (센서 중요도 지표)에 대한 한계점 지적
- 장기간(~100개의 타임스탬프)데이터에서는 괜찮지만, 짧은 데이터 (~5개의 타임스탬프)의 데이터에서는 잘 작동하지 않음
- 본 모델에서 이를 극복했다고 주장함.
결론
- 단, 성능이 그닥 좋지 않음
- 우리는 가변 길이 고려할 필요 없을듯?
📌 [2021 Intelligent Manufacturing] Multiple time-series convolutional neural network for fault detection and diagnosis and empirical study in semiconductor manufacturing
@Fault detection and diagnosis, @Time Series classification, @Convolutional neural network, @Smart manufacturing
😎 그냥 다변량 데이터에서 특징 추출하여 이상 탐지 ❗❗
첨단 제품과 스마트 제조의 급속한 변화로 정보기술과 공정기술의 발전이 강화되면서 사양이 더욱 정교해졌다. 제조 공정 중 장비 상태를 기록하기 위해 많은 양의 센서가 설치됩니다. 특히 센서 데이터의 특성은 시간적이다. 시계열 분류를 위한 기존의 대부분의 접근 방식은 다수의 센서 데이터에서 효과적인 특징을 적응적으로 추출하고, 고장을 정확하게 감지하고, 고장 진단을 위한 할당 가능한 원인을 제공하는 데 적용되지 않는다. 본 연구는 반도체 제조에서 결함 감지 및 진단을 위한 다중 시계열 컨볼루션 신경망(MTS-CNN) 모델을 제안하는 것을 목표로 한다. 이 연구는 결과의 양을 생성하여 다양성을 향상시키고 과적합을 방지하기 위해 슬라이딩 윈도우와 데이터 확대를 통합한다. 장비 센서의 주요 기능은 적층된 컨볼루션 풀링 레이어를 통해 자동으로 학습할 수 있다. 제안된 MTS-CNN에서 각 센서의 중요성은 진단 계층을 통해서도 확인되며, 제안된 MTS-CNN을 검증하고 다른 다변량 시계열 분류 방법들 간의 성능을 비교하기 위해 웨이퍼 제작의 실증적 연구를 수행하였다. 실험 결과는 MTS-CNN이 높은 정확도, 리콜 및 정밀도로 결함 웨이퍼를 정확하게 감지할 수 있으며 기존의 다른 다변량 시계열 분류 방법보다 성능이 우수함을 보여준다. MTS-CNN에서 진단 계층의 출력 값을 통해 각 고장과 다른 센서 간의 관계를 식별하고 고장 진단을 위한 Excursion을 연결하는 귀중한 정보를 제공할 수 있다.
결론
- 정상과 유사한 형태의 이상 패턴 & 같은 길이의 공정 스텝 반복하는 데이터
📌 [2022 ICCAD] 1D ResNet for Fault Detection and Classification on Sensor Data in Semiconductor Manufacturing
@Fault detection, @Raw multivariate sensor data, @Deep learning, @ResNet, @Semiconductor manufacturing
😎 1D ResNet 사용한 방법❗❗
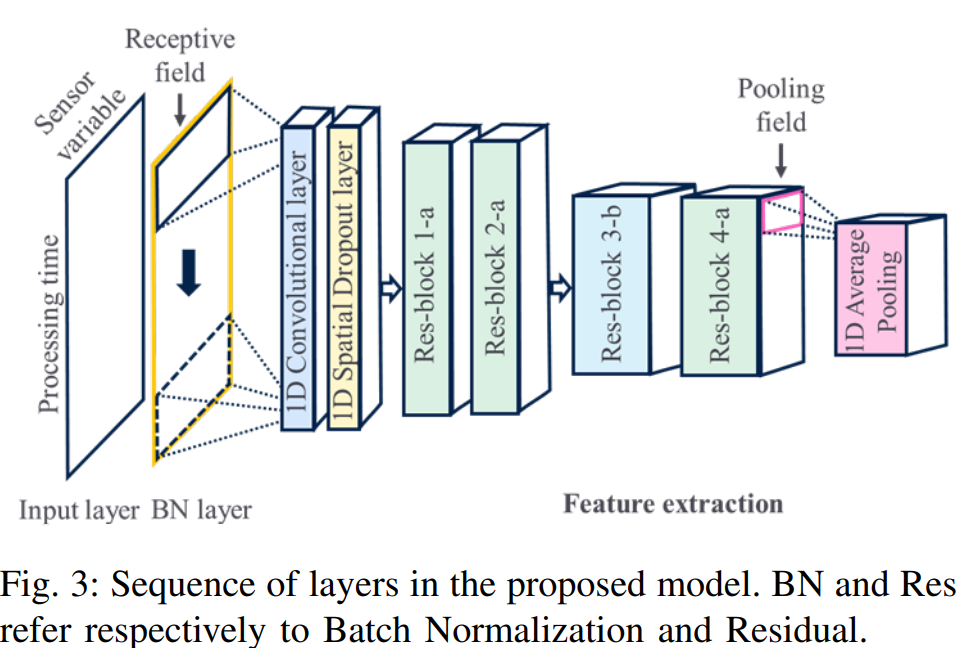
제조 비용 절감과 생산성 향상에 많은 관심이 집중되고 있는 상황에서 공정 도구를 양호한 작동 조건으로 유지하는 것이 가장 중요한 목표 중 하나입니다. 제조 공정 중에 엄청난 양의 데이터가 수집되며, 오늘날의 과제는 이러한 방대한 데이터를 효율적으로 활용하는 것입니다. 본 논문에서는 1D ResNet 알고리듬을 기반으로 하는 다변량 시계열 고장 감지 방법을 제안한다. 반도체 제조 과정에서 다양한 센서를 통해 수집된 Raw data를 분석하여 이상 웨이퍼를 검출하는 것이 목적이다. 이를 위해 제조 체인의 특정 공구에서 파생된 일련의 특징을 선택하고 평가하여 웨이퍼 상태를 특성화합니다. 제안된 접근 방식을 검증하기 위해 두 개의 별개의 데이터 세트가 사용된다. 얻은 결과는 제안된 방법의 장점을 강조하며, 이는 반도체 제조 공정에서 비정상적인 웨이퍼 검출에 대한 귀중한 의사 결정 지원이 될 수 있다.
-
반도체 공정 모니터링을 위한 다변량 센서 신호에 대한 ResNet 기반 고장 감지 방법 제안함.
-
원본 데이터의 구조적 특성을 고려하고 의미 있는 상관 관계 및 시간 정보의 추출을 가능하게 하기 위해 첫번째 convolution layer를 재설계함.
-
또한 딥러닝의 degradation문제를 완화하면서 훈련을 개선하기 위해 skip connection이 있는 residual block을 사용함.
-
실제 반도체 업계의 데이터를 사용하여 우수한 성능을 확인함. (STMicroelectronics Rousset 8” fab)
-
향후 연구로, 일반화와 성능 향상을 위해 Augmentation과 transfer learning을 도입할 예정임.
-
또한 가변 길이 데이터에서도 작업할 수 있는 모델을 만들고자 함.
결론
- FDC는 정확하게 감지할 뿐만 아니라, 결함을 특성에 따라 분류하고 장비의 근본 원인을 진단할 수 있어야 함.
📌 [2022 CSTIC] ANOMALY DETECTION OF SEMICONDUCTOR PROCESSING DATA BASED ON DTW-LOF ALGORITHM
@DTW; @FDC;
😎 DTW와 LOF 사용한 방법❗❗
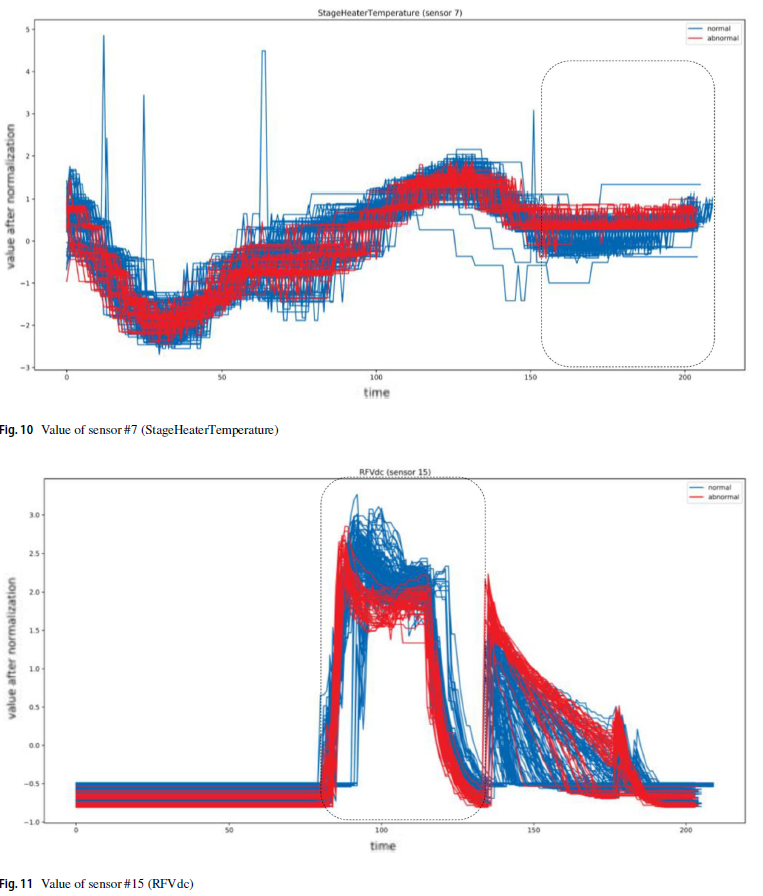
장비 센서 데이터의 FDC(Fault Detection and Classification)는 장비 및 처리 웨이퍼 상태를 모니터링하기 위한 반도체 웨이퍼 제조에서 매우 중요하다. 센서 데이터의 이상 징후를 조기에 감지하면 나중에 프로세스 조정을 용이하게 하고 추가적인 경제적 손실을 방지할 수 있다. 센서 데이터는 유지보수 주기 중 기계 상태 변화로 인해 처리 웨이퍼 로트마다 크게 다릅니다. 이 논문은 불안정한 기계 조건에서 센서 데이터의 안정적인 이상 징후 감지를 달성하기 위해 동적 시간 왜곡(DTW) 알고리듬과 로컬 이상치 계수(LOF) 알고리듬을 결합한다. DTW-LOF 모델은 적은 양의 데이터로 다양한 칩 처리 기술에서 우수한 이상 탐지 정확도를 보여준다. 반도체 처리의 이상은 보통 동일한 시간 범위에서 다중 센서의 종합적인 이상으로 반영되었기 때문에, 이들 센서의 정상화된 DTW 거리는 처리 이상 단계 및 센서를 효과적으로 파악할 수 있었다.
-
LOF: 밀도 고려하여 이상 구분하는 알고리즘
-
센서들은 반도체 처리 단계마다 다르게 동작하기 때문에, 실제 이상은 보통 특정 단계에서 다수의 센서들에서 나타남.
-
따라서, 센서 데이터를 단계별로 구분하여 웨이퍼 간 동일한 단계에서 동일한 센서에 대한 LOF 이상 검출을 수행함.
-
서로 다른 센서의 이상을 비교하기 위해 훈련 세트의 LOF 점수를 표준화함
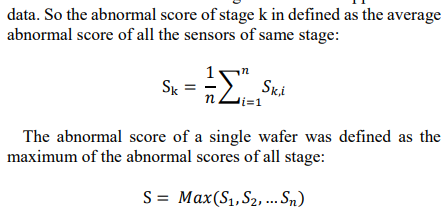
-
-
DTW: 유사한 모양이 시간 차원에서 위상을 벗어나더라도 일치하도록 하는 알고리즘
-
반도체 처리에서 수집되는 센서 데이터는 샘플링 등의 문제로 인해 시작 시간이 다르게 나타남.
-
하지만, 동일한 두개의 시계열 데이터도 1초 만에 큰 유클리드 거리 이동을 생성함.
-
따라서, DTW 거리를 이용하여 시차의 영향을 최소화하여 서로 다른 웨이퍼 가공 간의 센서 값 차이를 보다 정확하게 비교함
-

Figure 1. Sensor data from etching process: (A) different lot (B) same lot
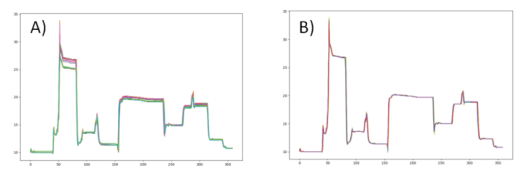
-
반도체 웨이퍼의 처리는 일반적으로 Lots 단위로 처리됨.
-
동일한 로트에 있는 웨이퍼는 일반적으로 인접한 시간에 동일한 기계 조건에서 수행됨.
-
그림1에서 보듯이, 서로 다른 로트의 센서 데이터는 차이가 있지만, 동일 로트 내 센서 데이터는 매우 유사함.
-
이로 인해, 모든 센서 데이터에 대해 고정된 수치 표준이 설정된 경우 기계 상태가 변경될 때 많은 수의 경보가 발생함.
-
그렇다고 느슨한 표준을 설정하면, 이상이 잘 탐지되지 않음
Figure 2. semiconductor processing sensor data. A) steps B) actual anomalies
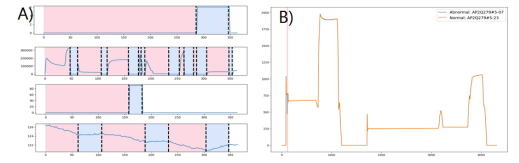
-
반도체 웨이퍼 처리 공정의 각 단계는 보통 여러 단계로 나뉘는데, 서로 다른 센서들은 이러한 단계들 사이에 큰 차이를 가짐.
-
센서 데이터는 안정적인 위상과 불안정한 위상으로 구분되는데, 불안정한 단계에서는 센서 데이터의 변동이 클 수 있으며, 안정적인 단계에서이 키 센서의 비정상적인 변동은 극히 작음.
-
Fig2 (A)에서 나타난 바와 같이 서로 다른 센서의 변화 시점이 같지 않아 실제 이상 감지 알고리즘에 더 큰 어려움을 초래함.
-
Fig2 (B)에 표시된 실제 이상 징후는 약 300초의 모든 처리 과정 중 0.3-0.4초만 존재함
Figure 3. Anomaly of processing reflected by different sensors
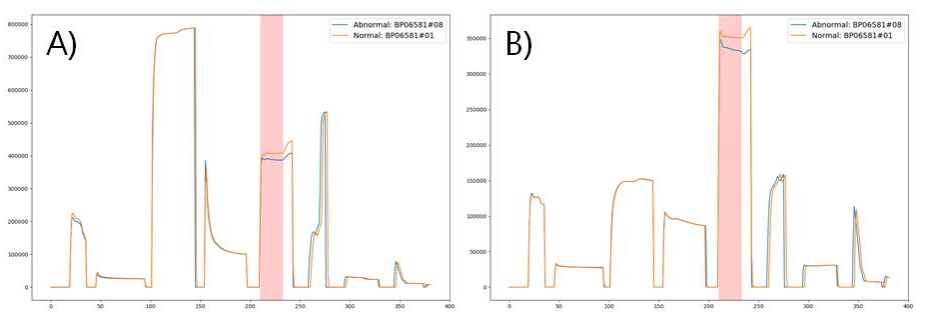
-
반도체 공정 과정을 모니터링하기 위해 다수의 센서가 사용됨.
-
실제 센서 변동은 그림 3과 같이 2개의 센서에 의해 동시에 발생함.
-
따라서, 본 연구에서는 이상 공정 단계를 평가할 때 이 단계에서 각 센서의 이상 점수를 채점하여 특정 센서 이상의 단독판단을 회피하여 이상 탐지의 효율성과 정확도를 향상시킴.
-
동시에, 비인접 가공 단계들 간의 직접적인 상관관계는 필요없기 때문에 웨이퍼 공정 이상을 판단할 때 모든 단계를 고려할 필요는 없으며, 공정 과정에서 불안정한 단계들의 영향도 피할 수 있음.
-> 결국 이상은 stage별로 나타나기 때문에, stage별로 구분하여 이상 score를 계산하여 위와 같은 장점을 얻음.
결론
-
실제로 반도체 공정은 일괄적으로 수행되며, 이는 기계 고장이나 생산 절차의 변경과 같은 시스템적인 이유에서만 발생할 수 있기 때문에 전체 배치의 모든 웨이퍼가 동일한 패턴의 이상을 갖는 경우는 드묾
- 복잡한 웨이퍼 생산 공정에서 기계 고장으로 인해 전체 배치에 품질 문제가 발생하는 경우는 거의 없음.
- 우발적인 요인에 의한 웨이퍼 레벨 이상이 발생할 가능성이 높음.
-
전체 배치의 센서 데이터 변동이 유사한 경우 서로 다른 웨이퍼 데이터의 로컬 밀도가 더 높음. (=당연한말)
- 전체 웨이퍼 배치에서 소수의 웨이퍼의 성능이 다르기 때문에 이러한 웨이퍼는 더 낮은 로컬 도달 가능성 밀도, 즉 더 높은 로컬 이상치 계수를 가짐. (=당연한말)
-
LOF 알고리즘에서 이웃 수를 의미하는 하이퍼 파라미터가 한 배치안에 있는 웨이퍼 수보다 적으면
-> 배치 내 웨이퍼 간의 이상만 LOF 점수가 상승함. (배치 간의 전반적인 변동으로 LOF 점수가 증가 x)
-> 이는 기계 상태나 원자재 변화로 인한 모델의 false alarm을 효과적으로 피할 수 있게 해 줌. -
따라서, 이 알고리듬은 기계 상태 및 원료의 변화로 인한 모델의 잘못된 경보를 효과적으로 방지하고 이상 탐지의 정확도를 향상시킬 수 있음.
📌 [2022 IEEE Transactions on Semiconductor Manufacturing] Anomaly Detection in Batch Manufacturing Processes using Localised Reconstruction Errors from 1-Dimensional Convolutional AutoEncoders
@Deep Learning, @Fault Detection and Classification, @Semiconductor Manufacturing, @Convolutional AutoEncoder,@Reconstruction Error
😎 1d-CAE와 LRE 사용한 방법❗❗
반도체 제조 프로세스 내의 다변량 배치 시계열 데이터 세트는 효과적인 이상 탐지(AD)를 위한 어려운 환경을 제공한다. 문제는 레이블이 지정된 실제 데이터의 제한된 가용성으로 증폭된다. AD가 가능한 시나리오에서 블랙박스 모델링 접근법은 모델 해석 가능성을 제한한다. 이러한 과제는 딥 러닝 솔루션의 광범위한 채택을 방해한다. 이 연구의 목적은 1차원 컨볼루션 자동 인코더(1d-CAE)와 국부 재구성 오류(LRE)를 사용하여 AD 성능과 해석 가능성을 향상시키는 AD 접근 방식을 시연하는 것이다. LRE를 사용하여 이상을 초래하는 센서와 데이터를 식별하면 딥 러닝 솔루션의 설명 가능성이 향상된다. 테네시 이스트먼 프로세스(TEP) 및 LAM 9600 메탈 에처 데이터 세트를 사용하여 제안된 프레임워크를 검증했다. 결과는 제안된 LRE 접근 방식이 1.00의 AUC를 달성하는 유사한 모델 아키텍처에 대한 전역 재구성 오류를 능가한다는 것을 보여준다. AE 및 LRE를 사용하여 제안된 비지도 학습 접근법은 모델 설명성을 향상시켜 프로세스 엔지니어링 팀에 해석 가능하고 신뢰할 수 있는 결과가 중요한 반도체 제조에서 배치에 도움이 될 것으로 예상된다.
- LRE가 사용되는 이유
- 재구성 오류 임계값을 평가할 때 각 입력 채널 및 센서에 제공되는 독립성 때문에 LRE가 GRU보다 선호됨.
결론
- 단, 데이터셋이 이런 거 같음
- The Tennessee Eastman Process (TEP) and LAM 9600 Metal Etcher datasets