SPS LAB 2025.02.17 논문 세미나
- 본 내용은 DualNet: Fast and Slow Continual Learning 논문을 읽고 정리한 내용입니다.
- 논문 원본은 해당 링크에서 다운받으실 수 있습니다.
Contribution
- CLS 이론에서 영감을 받아 fast and slow learning system 2가지 요소로 구성된 새로운 continual leanring framework인 DualNet을 제안
- represenatation learning과 supervised learning을 효율적으로 분리하는 DualNet을 위한 새로운 학습 패러다임을 제안
- slow learner는 general representation을 유지하기 위해 background에서 학습되며, 동시에 fast learner는 new knowledge를 빠르게 포착할 수 있는 새로운 adaptation mechanism을 갖추고 있음
- 기존의 adaptation technique가 다르게, task identifier를 필요로 하지 않음
- 광범위한 실험을 통해 DualNet의 효과, slow learner의 objective에 대한 robustness, 그리고 계산 자원에 대한 scalability를 입증함
Introduction
- 인간은 다양한 인지 작업을 수행하기 위해 학습하고 지식을 축적하는 능력을 가지고 있고, 이러한 능력은 서로 연결된 서로 다른 뇌 영역 간의 복잡한 상호 작용으로 이루어짐
- 유명한 모델 중 하나는 Complementary Learning Systems (CLS) theory인데, 이는 '해마(hippocampus)'와 '신피질(neocortex)'의 두 가지 상호보완적 학습 시스템을 통해 이루어진다고 함
- 해마는 특정 경험에 대한 패턴 분리 표현의 빠른 학습에 중점을 두고, 신파질은 장기적인 유지와 새로운 경험으로의 일반화를 지원하는 표현을 학습하는 데 초점을 둠
- Deep Neural Network가 인상깊은 성과를 냈지만, continual learning scenario에 대해 성능이 좋지 않은 상태에서 많은 양의 I.I.D 데이터에 접근해야 하는 경우가 많음
- CLS 이론이 재앙적 망각을 완화하는 것과 지식 전달을 촉진하는 것 사이의 더 나은 절충안을 통해 일반적인 Continual Learning Framework에 어떻게 동기를 부여할 수 있는지 탐구하는 것을 목표로 함
- 여러 Continual Learning strategies는 CLS 이론 원칙에서 영감을 받았지만, 해마나 신피질을 모델링하기 위해 single backbone 모델을 사용하며, 이는 두 가지 표현 유형을 동일한 네트워크에 결합함
- 게다가 특정 네트워크는 supervised loss를 최소화하는 것에만 초점을 맞추고, general representation learnng을 보완하는 별도의 구체적인 slow learning componenet가 부족함
- continual learning중에 소량의 메모리 데이터에 대해 지도 학습을 반복적으로 수행하여 얻은 표현은 과적합될 수 있으며 작업 전반에 걸쳐 잘 일반화되지 않을 수 있음
- 이를 해결하기 위해 CLS 이론에서 영감을 받아 DualNet을 제안
- 두 가지 보완 학습 시스템으로 구성된 새로운 지속 학습 프레임워크로, self-supervised representation을 통해 generic feature를 학습하는 slow learner와 slow learner의 feature를 적응시켜 per-sample based adaptation mechanism을 통해 라벨링된 샘플로부터 빠르게 지식을 얻는 fast learner로 구성
- Supervised learning phase에 새로운 라벨이 붙은 샘플이 들어오는 것은 slow learner의 representation을 query하고 조정하여 fast learner가 예측을 하도록 유도
- 발생한 손실은 두 학습자 모두에게 역전파되어 장기 보존을 위한 현재의 지도 학습 패턴을 통합
- slow learner는 항상 메모리 데이터만을 사용하여 SSL 목표를 최소화하여 백그라운드에서 학습하고, 따라서 느리고 빠른 네트워크 학습은 완전히 동기화됨
- DualNet은 라벨링된 데이터가 지연되거나 제한되는 실제 시나리오에서도 표현력을 지속적으로 향상시킬 수 있음
Method
Setting and Notations
- online continual learning 설정에서 데이터 스트림은 = {} 로 표현되며, 각 인스턴스는 레이블된 샘플 과 선택적으로 작업 식별자 를 가짐
- 각 레이블된 데이터 샘플은 task을 나타내는 기본 분포 에서 가져오며, 작업 전환을 나타내는 로 갑자기 변경될 수 있음
- 작업 식별자 t가 입력으로 제공되면 설정은 multi-head evaluation을 따르며, 해당 분류기만 선택되어 예측을 수행
- 작업 식별자가 제공되지 않으면 모델은 지금까지 관찰된 모든 클래스에 대해 공유 분류기를 가지며, single-head evaluation을 따름
- 일반적인 지속 학습 전략은 에피소드 메모리 을 M 사용하여 관찰된 데이터의 하위 집합을 저장하고 현재 샘플을 학습할 때 이를 상호배치하는 것
- 에서, 랜덤하게 샘플링된 미니배치를 으로 표시하고, M의 두 가지 뷰를 로 표시하며, 이는 두 가지 다른 데이터 변환을 적용하여 얻음
- input data로부터 general representation을 학습하는 slow network의 파라미터는 로, transformation coefficients를 배우는 fast network의 파라미터는 임.
Architecture
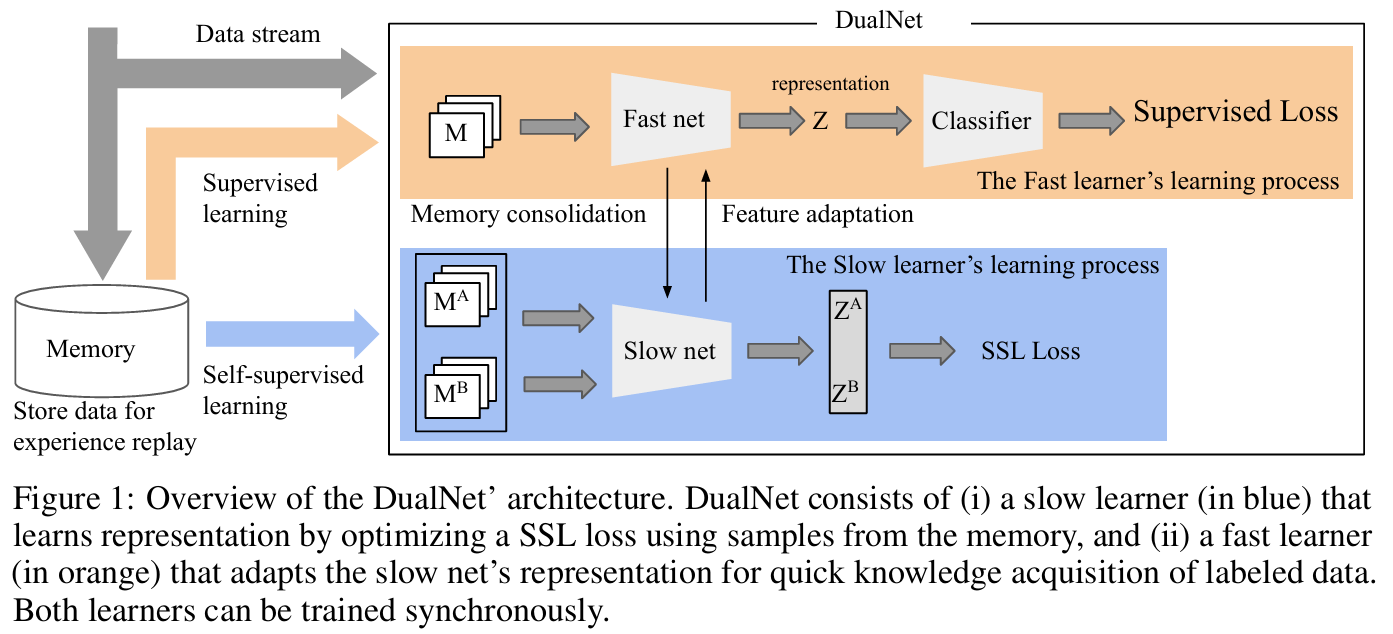
- DualNet은 작업 레이블에 독립적인 데이터 표현을 학습하여 지속적인 학습 시나리오에서 작업 전반에 걸쳐 더 나은 일반화 기능을 제공
- 2가지 main learning modules로 구성
- slow learner는 general, task-agnostic한 표현을 학습
- fast learner는 라벨링된 데이터를 사용하여 새로운 정보를 빠르게 포착한 다음 지식을 slow learner에 통합
- 2개의 synchronous phases로 구성
- slow learner가 episodic memory 의 레이블이 없는 데이터를 사용하여 SSL objective를 최적화하는 Self-superveised learning phase
- 레이블이 지정된 샘플이 도착할 때마다 발생하며, fast learner가 slow learner의 표현을 쿼리하고 이 샘플을 학습하도록 조정하는 supervised learning phase
- fast learner의 adaptation은 샘플별로 이루어지며 작업 식별자와 같은 추가 정보가 필요하지 않음
- DualNet은 샘플과 라벨을 저장하는 다른 방법들과 동일한 에피소드 메모리를 사용하지만, slow learner는 sample만 필요로 하고 fast learner는 sample과 label을 모두 사용
The Slow Learner
-
SSL loss 를 최적화하기 위해 훈련된 standard backbone network 로, 일반적인 표현을 보장하면서 추가적인 computational resources를 최소화하기 위헤 오직 SSL 손실만 고려
- MoCo처럼 추가 메모리 유닛이 필요하지 않음
- BYOL처럼 항상 네트워크의 추가 복사본을 유지하지 않아도 됨
- JIGEN과 같은 수작업 기반 손실을 사용하지 않음
-
최소한의 계산 오버헤드로 유망한 결과를 달성한 최신 SSL 방법인 Barlow Twins를 고려
- 메모리에서 샘플링된 이미지 M 배치에 두 가지 다른 데이터 변환을 적용하여 얻은 두 가지 뷰 가 필요
- 증강된 데이터는 네트워크 를 거쳐 SSL의 표준 관행을 따라 느린 네트워크의 마지막 레이어 위에 projector를 사용하여 두 표현 를 얻음
-
Barlow Twins 수식
- 는 trade-off factor이고, 는 의 cross-correlation matrix임
- b는 mini-batch index이고, i, j는 vector dimension indices임
- cross-correlation matrix을 identity로 최적화함으로써, Barlow Twins가 왜곡(distortion)에 불변하는 필수 정보(대각선의 단위 요소)를 학습하도록 강제하면서 데이터의 중복 정보(다른 곳에서는 0개의 요소)를 제거
-
해당 논문에서는 slow learner를 Look-ahead optimizer를 사용하여 최적화
- 대부분의 SSL 방법에서 LARS optimizer는 많은 장치에서 분산 학습을 위해 사용되며, 이는 라벨이 없는 대량의 데이터를 활용헤야 함
- 그러나, continual Learning에서는 episodic memory가 작은 양의 sample만 저장하는데, 이 또한 memory updating mechansim 떄문에 항상 변화함
- 그 결과, 에피소드 메모리의 데이터 분포는 항상 학습 중에 이동하며, DualNet에서의 SSL 손실은 이러한 기존의 SSL 최적화와 다른 도전 과제를 제시
- 특히, continual learning에서 SSL 목표는 하나의 장치를 사용하여 쉽게 최적화할 수 있지만, 현재 저장된 샘플을 최신 샘플로 대체하기 전에 빠르게 파악해야 함
-
optimizer 업 데이트 수식
- 는 Look-ahead의 learning rate이고, 는 파라미터 에 대한 손실 의 gradient를 반환하는 standard optimizer임
-
K = 1의 특별한 경우로서, 최적화는 전통적인 SGD로 축소되고, K > 1이면 표준 SGD 옵티마이저를 사용하여 업데이트를 수행함으로써 Look-ahead weitht 를 사용하여 slow learner의 momentum update를 수행함
- 결과적으로, slow learner의 최적화는 전통적인 최적화 도구에 의해 발견되지 않은 영역을 탐색하고 더 빠른 훈련 수렴을 가능하게 함
- SSL은 이러한 손실을 보지 못한 샘플로 일반화하기보다는 학습 손실을 최소화하는 데 중점을 두며, 학습된 표현은 다운스트림 작업에서 잘 수행되도록 적응해야 함
- slow learner는 백그라운드에서 지속적으로 학습되며, fast learner의 학습과 동기화되어 진행됨
The Fast Learner
- fast learner의 목표는 라벨이 붙은 샘플 {}가 주어졌을 떄, slow learner의 representation을 활용하여 adaptation mechanism을 통해 이 샘플을 빠르게 학습하는 것
- 본 논문에서는 channnel-wise transformation을 확장하고 향상시킨 context-free adatation mechanism을 제안
- 특히, task-identifier를 기반으로 transformation coefficients를 생성하는 대신, 이미지 x의 원시 픽셀로부터 이러한 계수를 학습하도록 fast learner를 훈련시키는 것을 제안
- 작업 식별자의 누락된 입력을 보완하기 위해 변환이 channel-wise가 아닌 pixel-wsie로 이루어짐
- image 가 slow learner의 layer를 통과하여 얻어진 feature map을 라고 함
- 우리의 목표는 이미지 x에 조건을 맞춘 적응된 특징 을 얻는 것으로, Fast learner를 L개의 레이어를 가진 Simple CNN으로 설계하여 를 얻음
- = element-wise multipication
- = fast network 의 l번째 레이어의 출력
- 최종 변환된 특징 는 분류기에 입력되어 예측을 수행
- fast learner는 간단한 CNN 구조를 사용하므로 경량이며, slow learner의 풍부한 표현을 활용할 수 있음
- 결과적으로 빠른 네트워크는 데이터 스트림에서 지식을 빠르게 습득하여 online continual learning에 적합함
- Fast learner's Objective
- Supervised learnin 중 fast learner의 빠르게 지식 습득하기 위해 Experience Replay(ER) 방식을 활용하여 현재 샘플과 이전 메모리 데이터를 혼합함
- 새로 라벨링된 샘플 {}와 메모리 데이터 M의 미니 배치가 주어졌을 때, 우리는 soft label loss가 사용한 ER을 통해 지도 학습을 수행
- CE : Cross-Entropy Loss
- : KL-Divergence
- : DualNet의 예측값
- : Softmax 함수 (온도 포함)
- : Softmax 함수의 온도 파라미터
- : Soft label과 Hard label 간 trade-off factor
- 이 손실 함수는 현재 샘플의 손실과 메모리 데이터의 손실을 결합하고, 소프트 레이블을 사용하여 과거 지식을 유지
Experiment
Goal
- 다음 3가지 가설을 조사하는 것이 목표임
- (i) DualNet의 representation learning은 supervised continual learning에 도움이 됨
- (ii) DualNet은 라벨링된 데이터 없이 백그라운드에서 self-training을 통해 성능을 지속적으로 향상시킬 수 있음
- (iii) DualNet은 representation learning과 continual learning을 원활하게 통합할 수 있는 일반적인 프레임워크를 제시하며, self-supercised learning 목표를 선택하는 데 견고함
Setup
- benchmark
- 미니 ImageNet과 CORE50 데이터셋에서 구축된 "Split" 연속 학습 벤치마크를 각각 세 가지 검증 작업과 17개, 10개의 연속 학습 작업으로 고려
- 각 작업은 원래 데이터셋에서 다섯 개의 클래스를 대체하지 않고 무작위로 샘플링하여 생성
- task-aware(TA) protocol의 경우, 모든 메서드에 작업 식별자를 제공하고 해당 분류기만 평가를 위해 선택
- task-free(TF) protocol의 경우, 훈련과 평가 모두에서 태스크 식별자가 제공되지 않으며, 모델은 지금까지 관찰된 모든 클래스에서 예측해야 함
- 종합적인 평가를 위해, 우리는 실험을 다섯 번 실행하고 훈련이 끝난 후 모든 과제/클래스의 평균 accuracy(ACC),forgetting measure(FM), learning accuracy(LA)를 측정
- baseline
- DualNet을 state-of-the-art continual learning methods가 비교하고, baseline의 하이퍼파라미터는 cross-validation에 대해 grid-search를 수행하여 결정
- ER, DER++, CTN
- architecture
- miniImageNet benchmark에서 모든 baseline과 DualNet의 DualNet의 slow learner's architecture에서 filter 수가 3배 적은 축소된 ResNet18을 backbone으로 사용
- CORE50 benchmark에서 full ResNet18을 backbone으로 사용
- 2 benchmarks에서 DualNet의 fast learner는 slow learner의 residual blocks과 동일한 수의 convolutional layer를 가지며, 동일한 output dimension을 가짐
- Training
- supervised learning phase에는 모든 방법이 한 에포크에 걸쳐 SGD optimizer에 의해 최적화 진행
- miniImageNet: mini batch size 10
- CORE50: mini batch size 32
- representation learing phase에는 DualNet의 slow learner를 훈련하기 위해 Look-ahead optimizer 사용
- task-aware setting에서 작업당 50개의 샘플이 포함된 episodic memory와 Ring-buffer management strategy를 사용
- task-free setting에서 memory는 클래스당 100개의 샘플로 구성된 reservoir buffer로 구현
- DualNet에서 동기화된 학습 속성을 시뮬레이션하기 위해, 라벨링된 데이터의 미니 배치를 관찰하기 전에 에피소드 메모리 데이터를 사용하여 slow learner를 n번의 반복으로 훈련시킴
- supervised learning phase에는 모든 방법이 한 에포크에 걸쳐 SGD optimizer에 의해 최적화 진행
- Data pre-processing
- representation learning phase에는 DualNet에 BarlowTwins에서 사용하는 data transformation 방법 적용
- supervised learning phase에는 2가지 setting을 고려
- 첫번째, 훈련과 평가 모두에서 데이터 증강이 없는 표준 데이터 전처리
- 두번쨰, 공정한 비교를 위해 DualNet의 표현 학습에 사용된 증강을 다른 baseline의 지도 학습 단계로 전파
- 그러나 모든 설정에서 추론 중에는 데이터 증강이 적용되지 않음
Results on Continual Learning Benchmarks
- Evaluation metrics
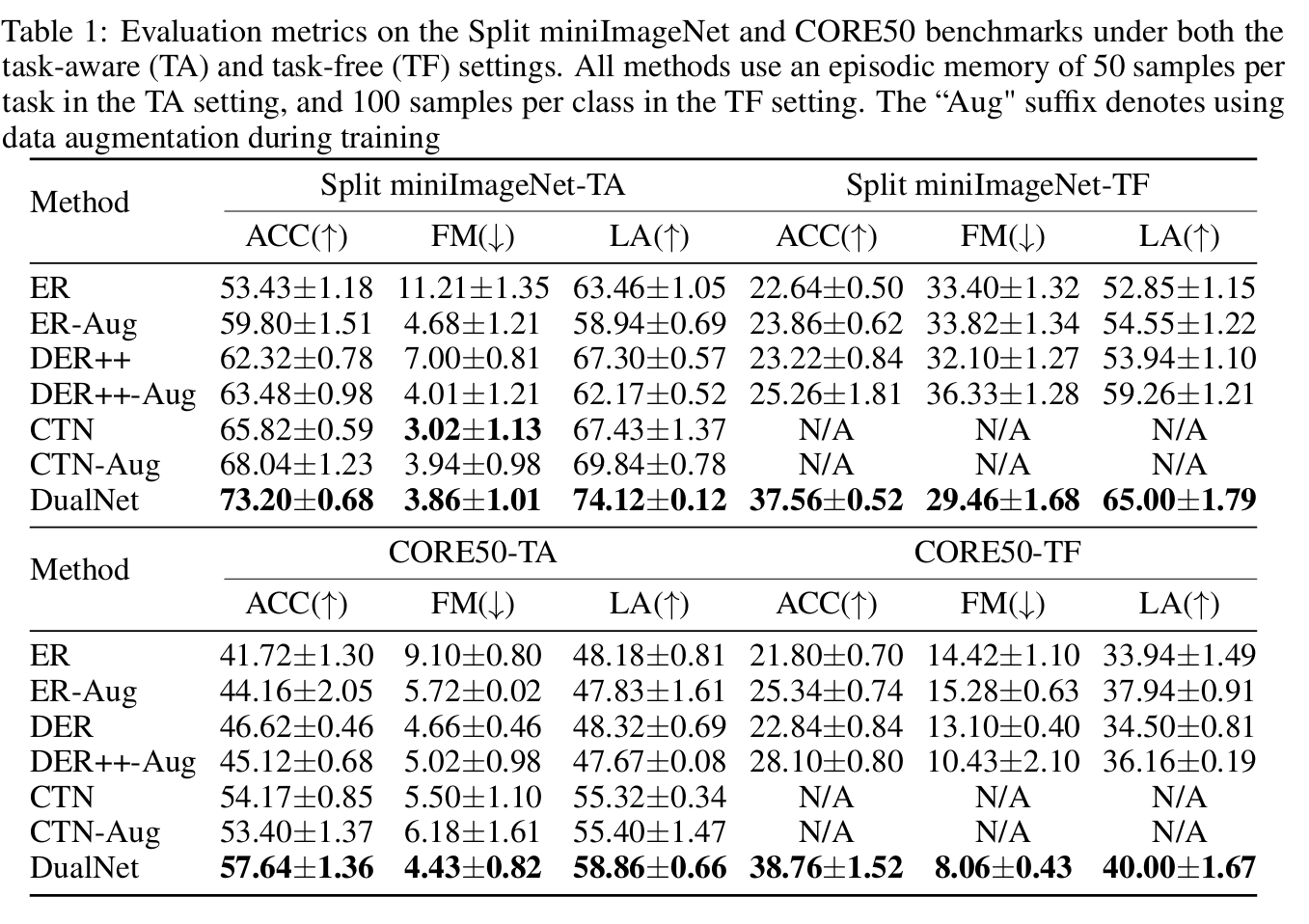
- CTN은 엄연히 task-aware method이므로 task-free에서의 성능 측정은 배제함
- DualNet의 slow learner는 라벨링된 데이터의 모든 mini-batch 사이에 3회 반복할 때 Barlow Twins objective를 최적화
- 데이터 증강은 모델을 학습하기 위해 더 많은 샘플을 만들고, 이는 모든 baseline의 성능 향상에 기여
- 평가 해석
- DER++가 soft label loss 덕분에 ER보다 약간 더 나은 성능을 보임
- CTN은 task-specific features을 모델링할 수 있기 때문에 ER과 DER++보다 더 나은 성능을 보임
- DualNet은 다른 baseline을 능가하는 성능을 지속적으로 보임
- 특히, DualNet은 catastrophic forgetting(낮은 FM)에 더 강하고 knowledge transfer(높은 LA)을 크게 촉진하여 높은 ACC를 가짐
- DualNet은 DER++와 유사한 objective를 가지고 있기 때문에, 이 결과는 DualNet의 분리된 representation과 빠른 adaptation mechanism이 contiunual learning에 유익하다는 것을 보여줌
Ablation Study
- Ablation Study of Slow Learner Objectives and Optimizers
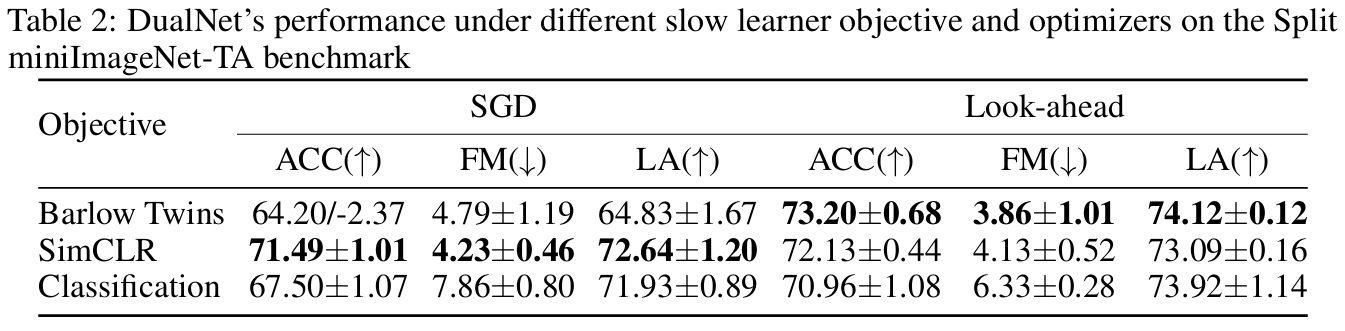
- slow learner를 학습하기 위해 여러 objective를 고려
- classification loss를 고려하여 slow net를 훈련시키고, 이는 DualNet의 표현 학습을 지도 학습으로 축소시킴
- 두 개의 데이터 증강으로 얻은 이미지의 두 가지 다른 표현 간의 일치를 최대화하는 최근 contrastive SSL 손실인 SimCLR framework를 고려
- 실험 설계
- 작업당 50개의 메모리 슬롯이 있는 스플릿 miniImageNet-TA 벤치마크를 고려하고 SGD 및 Look-ahead 옵티마이저를 사용하여 각 목표를 최적화
- 평가 해석
- supervised learning loss로 학습한 경우, fast feature와 slow feature가 각각 예측에 사용되어 disagreement가 발생해 좋지 않은 성능을 보임
- SimCLR objective가 Barlow Twins보다 간단하기 때문에 SGD optimizer는 경쟁력 있는 결과를 도출
- Look-ahead optimier는 모든 objective에서 일관되게 더 나은 성과를 달성하며, Barlow Twins 손실에서 최고의 성과를 달성하는 것을 확인
- DualNet의 설계가 일반적이며 다양한 slow learner의 목표에 잘 부합할 수 있음을 보여줌
- slow learner를 학습하기 위해 여러 objective를 고려
- Ablation Study of Self-Supervised Learning Iterations
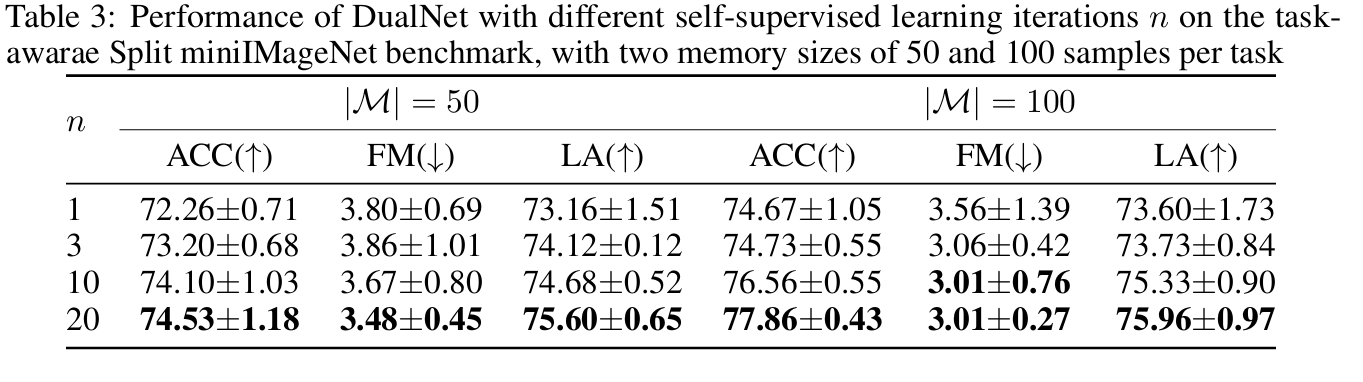
- 서로 다른 SSL optimization iteration n을 사용하여 DualNet의 성능을 조사
- n이 작으면 연속체에서 라벨링된 데이터가 거의 delay되지 않으며, fast learner가 slow learner의 representation을 지속적으로 쿼리해야 함을 나타냄
- n이 크면 레이블이 지정된 데이터가 delay되는 상황을 시뮬레이션하므로, slow learner는 fast learner의 각 쿼리 사이에 더 많은 반복 횟수로 SSL 목표를 학습할 수 있음
- 실험 설계
- 실험에서는 n 값을 1부터 20까지 점진적으로 증가시켜 SSL 학습 반복 횟수가 DualNet 성능에 미치는 영향을 측정
- 각 설정에서 에피소드 메모리 크기(50개와 100개 샘플)를 다르게 하여 결과를 비교
- 평가 해석
- n=1인 경우, SSL 학습 반복이 단 한 번만 수행되더라도 DualNet은 경쟁력 있는 성능을 보임. 이는 DualNet이 기본적인 SSL 학습만으로도 효과적임을 시사
- n값이 증가함에 따라, DualNet은 망각(forgetting)을 줄이고 지식 전이(knowledge transfer)를 촉진하여 더 나은 성능을 달성
- 서로 다른 SSL optimization iteration n을 사용하여 DualNet의 성능을 조사
Results on the Semi-Supervised Continual Learning Setting
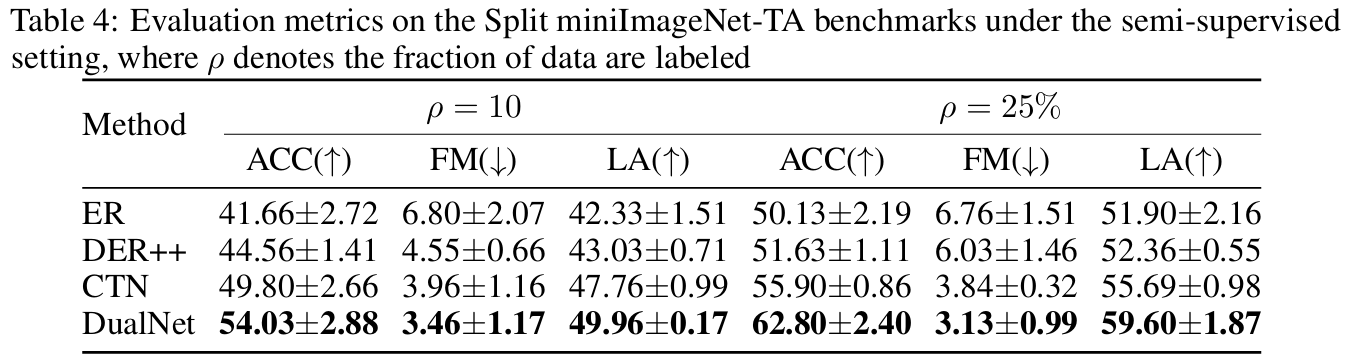
- 실제 continual learning 시나리오에서도 라벨링되지 않은 데이터가 많이 존재하며, 이는 모든 데이터를 라벨링하는 데 비용이 많이 들고 심지어 불필요함
- 따라서 실용적인 continual learning 시스템은 라벨이 없는 샘플을 사용하여 라벨이 붙은 데이터를 기다리면서 표현력을 향상시킬 수 있어야 함
- 데이터 스트림에 레이블이 있는 데이터와 레이블이 없는 데이터가 모두 포함된 semi-supervised continual learning benchmark를 만듦
- 실험 설계
- Split miniImageNet-TA 벤치마크를 고려하지만, 전체 샘플 중 일부()에 무작위로 라벨을 제공 (10%, 25%)
- 라벨링되지 않은 샘플은 지금까지 고려한 기중네 딸 처리할 수 없으나, fast learner가 비활성 상태를 유지하는 동안 듀얼넷의 slow learner가 표현력을 향상시키는 데 직접적으로 도움이 될 수 있음
- 평가 해석
- 제한된 양의 라벨링된 데이터가 있을 경우, ERand DER++의 성능이 크게 저하
- CTN은 작업 식별자의 추가 정보 덕분에 여전히 경쟁력 있는 성능을 유지할 수 있음
- DualNet은 라벨이 없는 데이터를 효율적으로 활용하여 성능을 향상시키고 CTN보다 뛰어난 성능을 발휘
- 라벨이 있는 데이터가 지연되거나 라벨이 없는 실제 환경에서도 작동할 수 있는 DualNet의 잠재력을 보여줌
Conclusion
- CLS 이론의 fast and slow learing principle에서 영감을 받은 continual learning paradigm인 DualNet을 제안
- DualNet은 2가지 학습 요소로 구성
- slow learner는 메모리 데이터를 사용하여 일반적이고 task-agnostic한 표현을 학습
- fast learner는 새로운 adaptation mechanism을 통해 새로운 지도 학습 지식을 포착하는 데 중점을 둠
- 두 가지 도전적인 벤치마크에 대한 광범위한 실험을 통해 DualNet의 효율성을 입증
- Ablation Study를 통해 DualNet이 더 많은 리소스를 사용하여 느린 학습자의 목표 확장에 견고하다는 것을 보여줌
- DualNet은 실제 continual learning 시나리오에 뛰어난 확장성을 가진 general continual learing framework를 제공
- 하지만, 느린 학습자를 지속적으로 훈련시키기 위해 발생하는 추가 계산 비용을 적절히 관리해야 함
- 또한 특정 도메인에 대한 응용 프로그램은 고유한 도전 과제를 고려해야 함
