RISC-V Calling Convention
앞선 2-2까지는 명령어들에 대해서 알아봤습니다. 각각의 명령어를 아는 것도 분명 중요하지만, 그 명령어들을 잘 사용하는 것 또한 중요한 일입니다. 코딩을 해 봤다면 누구나 알 수 있지만, 프로그램에서는 "함수"라는 것을 정말 많이 사용합니다. 이 함수를 호출하는 규약을 Calling Convention이라고 합니다.
Jump( j )
기본적으로 함수를 호출하면 Jump 명령어를 실행합니다. 하지만 기본적인 Jump 명령어인 j 에는 문제점이 있습니다.
만약 함수를 단 한 번만 호출한다면 아래 그림과 같이 j를 통해 함수를 호출하고, 그 함수 내부에서 다시 main으로 가는 j를 호출하면 됩니다.
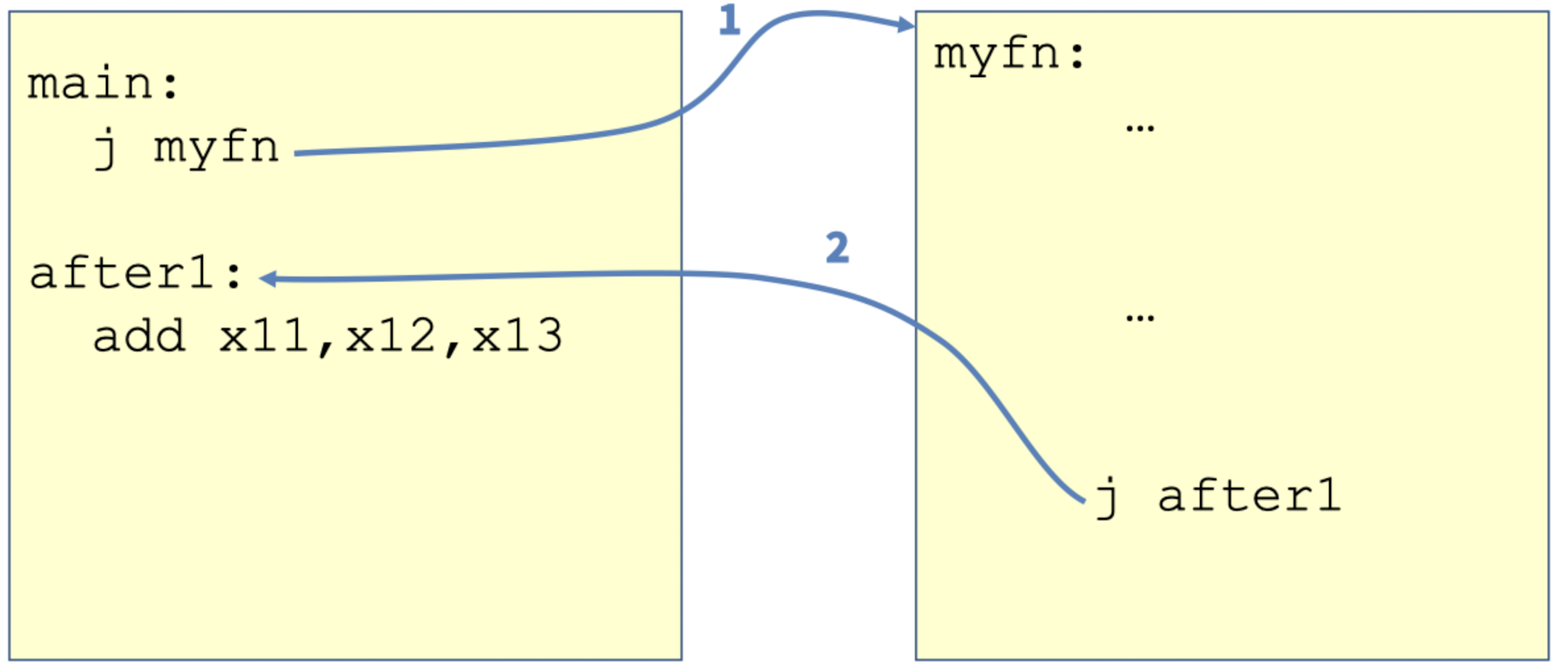
하지만 문제는 같은 함수를 여러번 호출할 때 발생합니다.
아래 그림과 같이 myfn 내부에서 다시 어디로 돌아갈 것인지 일일이 다 지정해야합니다. 물론 예시처럼 2번만 한다면 그렇게 불편하다고 느껴지지 않을 수 있지만, 같은 함수를 1억번 사용한다고 하면 1억개의 다른 주소들을 일일이 지정해야합니다.
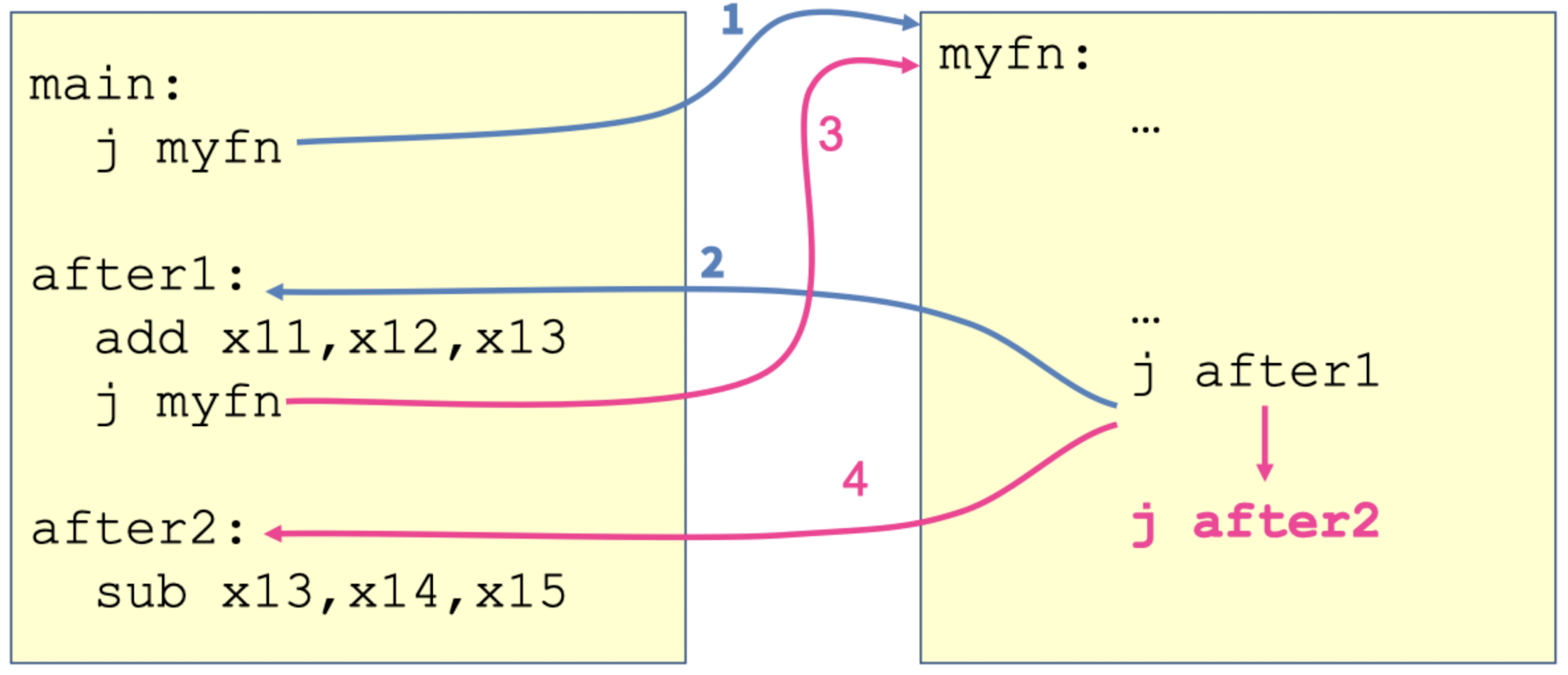
Jump and Link ( jal )
위와 같은 문제를 해결하기 위해서는 jal 명령어를 사용하면 됩니다.
jal 명령어는 함수를 호출할 때 return address를 x1 레지스터에 저장하는 방식을 사용합니다.
아래 그림과 같이 myfn를 호출함과 동시에 x1 레지스터에 다음에 수행할 after1의 주소인 PC+4를 저장해놓고, myfn이 종료되었을 때, jalr(jump and link register)을 사용하여 정해 놓은 주소값으로 이동합니다.

이러한 방식을 사용하면 함수를 언제 어디서 얼마나 호출하더라도 x1 레지스터에 저장되어 있는 곳으로 돌아갈 수 있습니다.
하지만 이 또한 재귀를 만났을 때는 무력해집니다. 아래 예시를 보면 myfn에서 myfn을 다시 호출하는 과정에서 after2의 주소를 x1 레지스터에 저장하게 되어 다시 main으로 돌아가지 못하게 됩니다.
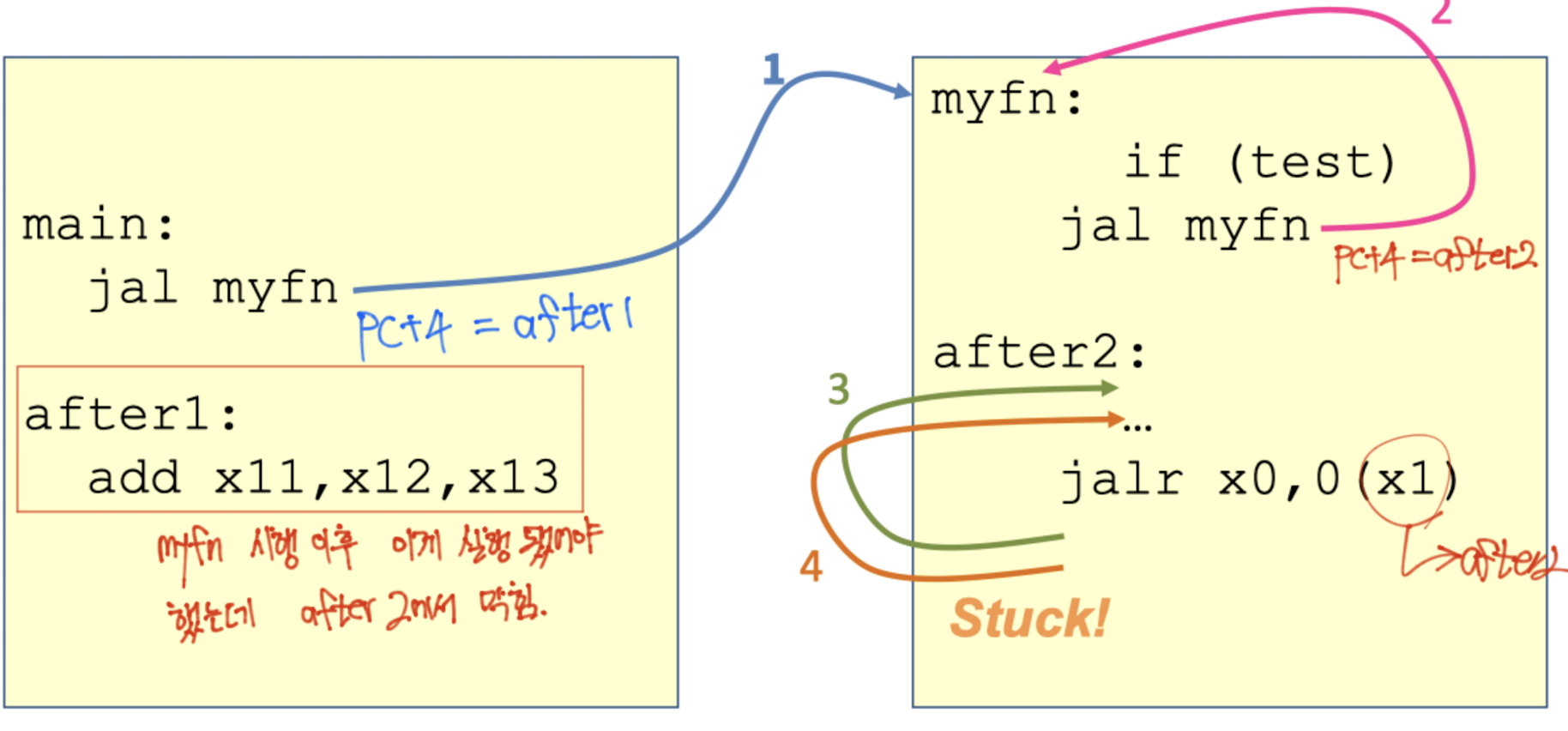
Stack
이번 2-3에서 핵심적인 부분이 바로 위의 문제들을 해결하는 것입니다. 위의 문제에서 보였듯이 after1의 주소를 담을 공간이 필요한 것이고, 그 공간을 Stack으로 만든 것입니다.
Stack은 함수가 호출되었을 때 저장이 필요한 정보들을 담고 있는 메모리의 특정 공간이며 LIFO(Last In First Out) 형식으로 관리됩니다.
또한 Stack에는 여러가지 정보들이 담기는데, 이는 아래와 같습니다.
- Return Address
- Local Variables
- Argument Value (more than +8)
- Argument Build
그리고 Stack의 최상단을 가르키는 포인터가 존재하는데, 이를 stack pointer(sp)라고 부르며 고정적으로 x2 레지스터에 저장됩니다.
Stack Operations
Stack에는 Push & Pop 이라는 두 개의 operation이 있습니다.
자료구조를 배웠다면 잘 알겠지만, 이론적으로 Stack에 대해 배울 때는 밑에서부터 쌓아올리는 형식입니다. 이를 상상하면 주소값을 증가시키면서 데이터를 저장할 것이라 생각할 수 있지만, CPU가 바라보는 Stack은 조금 다르게 주소값을 감소시키면서 아래로 데이터를 저장하고, 가장 아래에 있는 데이터부터 다시 가져옵니다.
그렇기 때문에 Push와 Pop 각각의 명령어는 아래와 같은 형태를 띱니다.
push
sub sp, sp, 8
sd t5, 0(sp)pop
ld t4, 0(sp)
add sp, sp, 8명령어에서 볼 수 있듯이 push 할 때 주소를 8만큼 빼고, pop할 때 주소를 8만큼 더합니다.
64bit architecture에서 포인터의 크기는 8byte이므로 8만큼 연산을 하는 것이며, 만약 return address 뿐만 아니라 다른 data들도 stack에 담겨있다면 data의 수 * 8 만큼 sp를 옮겨주면 될 것입니다.

Stack을 사용하여 recursive의 문제가 해결된 것을 확인할 수 있습니다.
Manage Registers
모든 문제가 다 깔끔하게 해결된 거 같지만, 여전히 문제는 남아있습니다. 바로 Caller와 Callee가 같은 레지스터를 사용하는 경우입니다.
main 함수에서 특정 함수로 인자를 넘겨주는 일은 매우 빈번하게 일어납니다. 하지만 같은 레지스터에 있는 값을 callee에서 수정하고 나면, caller에서 다시 사용할 때 원래 사용하던 값이랑 다른 값이 들어오는 문제가 발생합니다.
이를 막기 위해 caller와 callee는 레지스터 값을 stack 영역에 따로 저장하고 함수를 호출한 뒤 복원하여 사용합니다.
Passing Argument
처음 stack 설명 중 stack 영역에 저장되는 것에 Argument Value(more than +8)이라는 것이 있었습니다. 왜 more than +8이라는 말이 붙었는지 여기서 알게 됩니다.
기본적으로 caller는 callee에게 최대 8개의 레지스터를 제공할 수 있습니다. 이는 x10-x17이며, 이 레지스터의 original value가 caller의 stack frame에 저장되고, 이 후에 재사용됩니다.
그럼 인자가 8개가 넘어가는 경우는 어떻게 처리하지? 라는 의문이 들 수 있습니다. 8개가 넘어가는 경우에는 stack 영역에 저장하게 됩니다.
Stack Frame
저장하는 것까지 완료하였다면 이제 저장한 데이터들을 가져와서 써야합니다. 여기서 Stack Frame이라는 개념을 사용할 수 있는데, 이는 한 번의 함수가 호출될 때 만들어지는 Stack 영역을 의미하며, frame의 크기는 최초 호출 시에 정해집니다.
이후 sp는 stack 영역의 최상단으로 옮겨가지만, frampe pointer(fp)는 stack frame의 시작점에 고정되어(x8 레지스터에 저장) 함수가 실행되는 동안 데이터를 사용할 수 있게 합니다.
아래 그림을 보면 쉽게 이해할 수 있습니다.
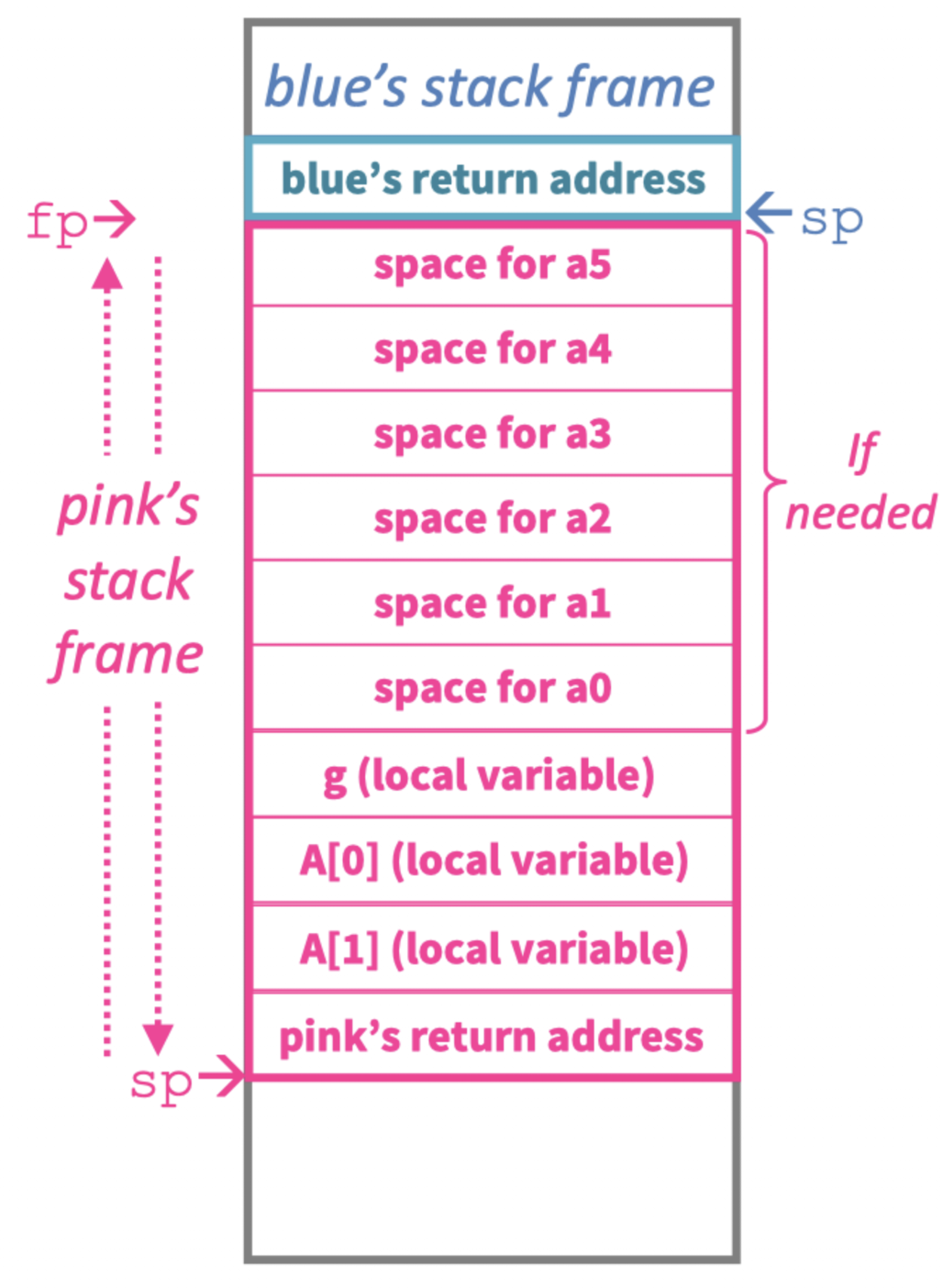
Heap
Heap은 메모리를 동적으로 할당합니다. malloc 함수를 통해 메모리를 할당하고, free 함수를 통해 해제할 수 있습니다. 프로그램은 포인터를 통해 할당된 메모리의 주소를 유지해야 합니다. 또한 free를 호출하지 않게 되면 메모리 누수가 발생할 수 있습니다.
void some_function(){
int *x = malloc(1000);
int *y = malloc(2000);
free(y);
int *z = malloc(3000);
}예시로 위와 같은 코드를 실행하게 되면 x 할당, y 할당 후 해제, z 할당의 과정을 거쳐 총 4000byte의 공간을 차지하게 됩니다.
Data Segment
Data Segment란 프로그램 내 전역 변수와 정적 변수가 저장되는 메모리 영역입니다.
프로그램 실행 동안 항상 유지됩니다. 즉, 함수 호출 및 종료와 관계없이 데이터가 존재합니다.
Data Segment의 중앙을 가리키는 gp가 존재하며, gp를 기준으로 상대적 주소를 사용하여 전역 변수에 접근합니다.
Memory Layout of RISC-V
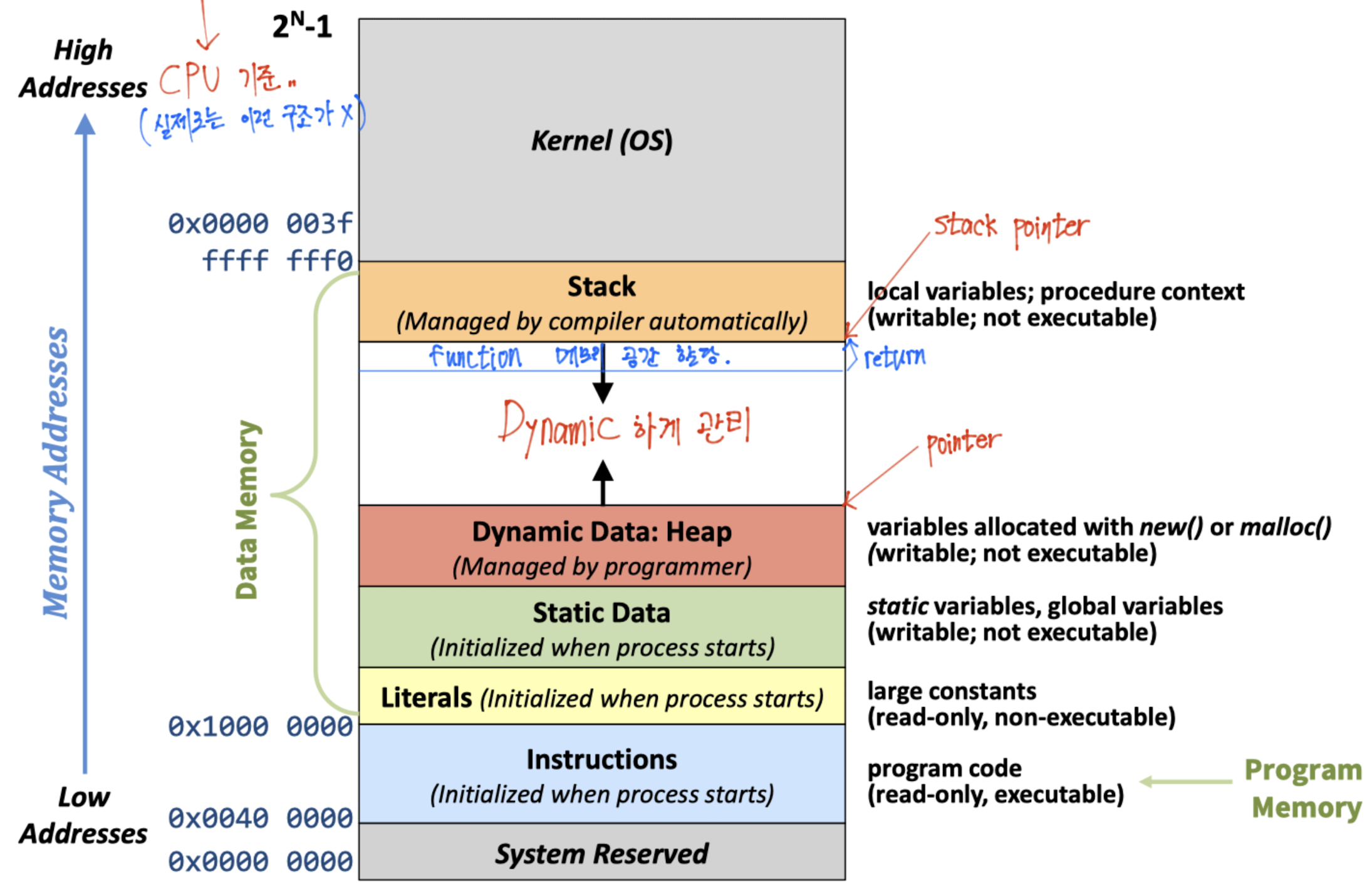
마지막으로 위에서 설명한 stack, heap, data segment를 포함하여 RISC-V에서 CPU가 바라보는 메모리의 모습은 이렇습니다.
