SECTION 5.2 - 선형 자료 구조
.1 자료 구조의 종류
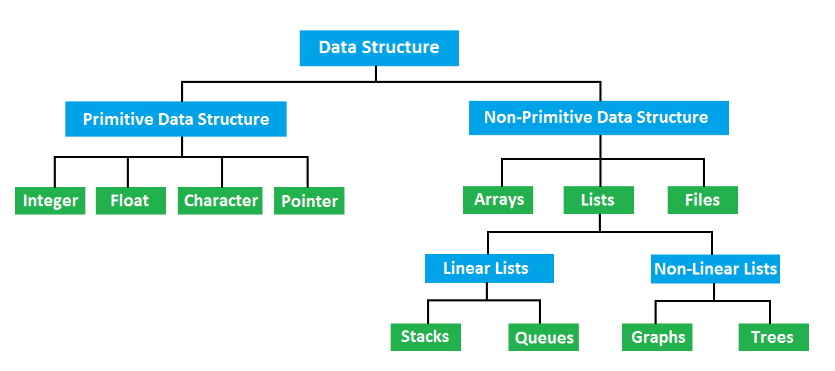
자료 구조는 크게 단순 구조와 비단순 구조 두가지로 분류 할 수 있음
-
단순 구조
프로그래밍에서 사용되는 기본 데이터 타입
Integer, Float, Character, Pointer, Double,Boolean.... 정수 실수 문자 문자열 등등....
-
비단순 구조
단순한 데이터를 저장하는 구조가 아닌 여러 데이터를 목적에 맞게 저장하는 자료 구조
Arrays, List, Files, Tuple, Dictionary, Set .... 배열, 리스트, 파일 등등
-
비단순 구조 ( Non-Primitive Data Structure)
비단순 구조는 저장되는 자료의 전후관계에 따라 선형 / 비선형 나뉘게된다.
-
자료 관계가 1:1 관계 일때 : 선형 구조
선형구조 자료를 저장하고 꺼내는 것이 중점
ex) 순차 리스트, 연결리스트, 스택, 큐.... -
자료 관계가 1:n , n:1 일때 : 비선형 구조
디렉토리, 네트워크 같은 표현에 초점
ex) 트리, 그래프...
-
.2 선형 구조 (Linear)
-
비단순 구조 - 선형 구조 (Linear) - Array
Array ( 배열 )
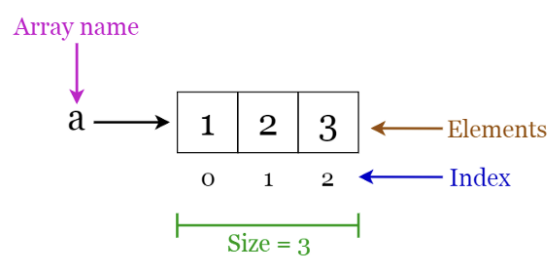
- 요소 ( Element )
배열을 구성하는 각각의 값 - 인덱스 ( Index )
배열에서 위치를 가르키는 숫자 - 유일무이한 식별자 - 크기가 정해져 있음 ( .size )
- 요소 삭제시 해당 공간이 그대로 남아 있음. -> 메모리의 낭비
- 조회 속도가 빠름
- 메모리에 연속적으로 데이터가 저장되기 떄문
- 인덱스를 활용해 빠르게 조회가능
- 요소 ( Element )
- 배열의 삭제 ( 출처 )
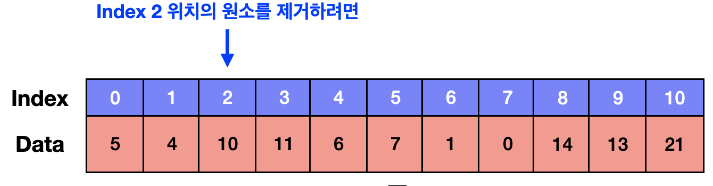
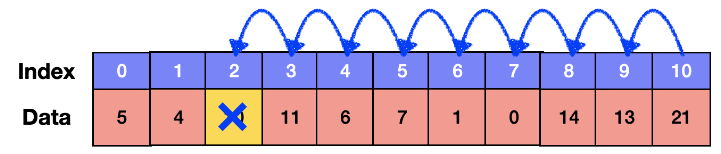

임의의 위치(N)에 있는 원소를 삭제 시키리면 뒤쪽 N개만큼 존재하는 원소를들 한칸 씩 앞으로 당겨와야 함. O(N) -> 배열은 연속적인 데이터이기 떄문
- 배열의 탐색 (조회)
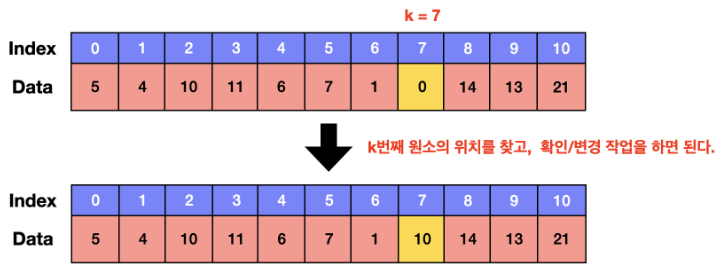
메모리 상에 연속적으로 나열되어 있으니 Index 만 알면 쉽게 조회 가능. O(1)
-
비단순 구조 - 선형 구조 (Linear) - 벡터 ( Vector )
벡터의 자료구조는 배열과 비슷하기 때문에 배열의 특징을 다시 짚어보자
-
배열의 특징
- 배열의 크기는 고정
- 처음 설정한 크기를 넘어서 데이터를 저장할수 없음
- 중간에 데이터 삽입, 삭제가 용이하지 않음.
- 배열은 데이터를 순차적으로 저장하기 때문
- 랜덤 접근이 가능함.
- 인덱스로 순차적으로 저장하기 때문
그럼 벡터와 배열의 차이는 무엇일까?
배열의 크기는 고정이지만 vector는 동적으로 변하는 점이 vector와 배열 자료구조의 큰 차이
차이를 알면, 배열과 벡터를 사용해야 할 상황을 구분하는것이 쉬워 짐.
- 배열의 크기는 고정
-
벡터를 사용하는 경우
- 데이터의 개수가 가변적
- 중간에 데이터의 삽입이나 삭제가 거의 없음
- 빈번하게 겁색하지 않는 경우
- 데이터를 순차적으로 저장하므로 많은 데이터를 저장하면 검색속도가 느림
- 자주 검색을 한다면 map, set, hash_map을 사용
- 데이터 접근을 랜덤하게 할 경우
또 골때리는게 이제 List랑도 비슷한 부분이 많아서 매우 헷갈렸다... 간단하게 표로 체크해보고 List를 알아보자...
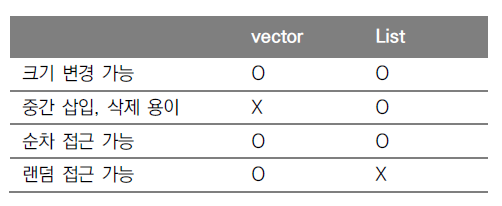
-
-
비단순 구조 - 선형 구조 (Linear) - List
-
( Array ) List ( 순차적 리스트 )
구현할 자료들을 논리적인 순서대로 메모리에 연속 저장하는 자료 구조
저장 시작 위치부터 빈자리 없이 순서대로 저장
논리적 순서 = 물리적 순서
-
Array vs ArrayList
모든 것이 비슷하지만, 길이를 조정할 수 있는가의 차이가 있음.
- Array : ( 고정 길이 ) 새로운 데이터를 추가 -> 배열을 만들어야 함
- ArrayList : ( 가변 길이 ) 내부적으로는 배열로 구성
=> 편리함의 대가로 Array보다 느림, 따라서 Array로 충분히 처리 가능할 경우 테스트 or 알고리즘을 풀때는 Array를 활용하는 것이 좋음
-
ArrayList vs Vector
동기화처리가 되어있으면 Vector 아니면 ArrayList
- 즉, Vector는 하나의 스레드만 접근 가능. (동기)
- ArrayList는 동시에 여러 스레드가 작업 가능(비동기)
- 동기화 (Synchronous) / 비동기화 (Asynchronous)
쉽게 말하면 동기 방식은 서버에 요청이 들어왔을때 응답이 돌아와야 다음 동작을 수행할 수 있는 것 -> A작업이 끝나야 B작업 시작 가능 비동기 방식은 응답 상태와 상관없이 A작업,B작업이 실행 가능하고 결과값이 나오는데로 출력
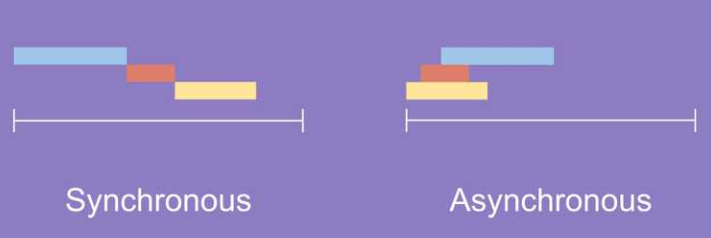
-
-
(Linked) List ( 연결 리스트 )
메모리에 저장된 물리적 위치나 순서 상관없이 링크에 의해 순서를 표현
연속적인 메모리에 저장되는 방식이 아니라 노드라는 각각의 독립된 공간을 사용해 데이터를 담음

노드는 실제 데이터가 저장되는 공간인 데이터 필드와 다음 노드의 주소값을 가진 링크 필드로 이루어짐
-
순차 리스트 ( Array ) vs 연결 리스트 ( Linked )
두 리스트는 삽입,삭제 탐색과정에 차이가 있음
-
순차 리스트 삭제 과정
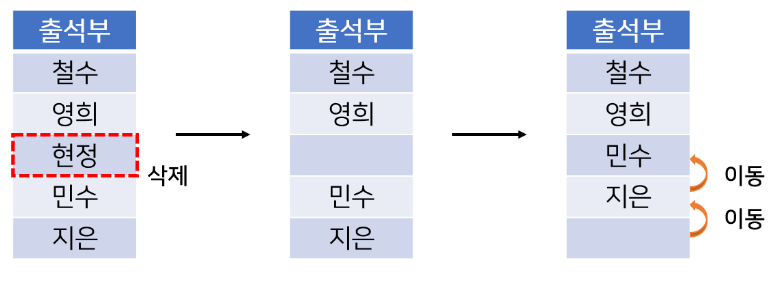
순차 리스트는 데이터를 삽입하거나 삭제하고 나면, 연속적인 물리적 위치를 유지하기 위해 원소를 옮기는 추가작업 진행
=> 따라서 삽입이나 삭제 연산이 많다면 시간이 많이 필요함.
-
-
연결 리스트 삭제 과정
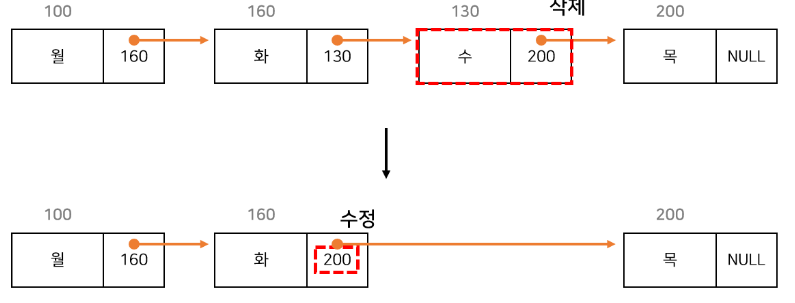
연결 리스트는 특정 노드를 삽입하거나 삭제할 때 노드의 링크 필드만 수정하면 되므로 순차 리스트에 비해 연산 속도가 빠름
- 두 그림을 비교해 보면 순차 리스트는 데이터의 삭제 작업이 이루어 진 뒤 주소의 변화가 생겼으나, 연결 리스트는 주소가 변경된 노드가 없었음
- 순차 리스트는 배열로 구현하기 때문에 인덱스를 통해 원소를 탐색할 수 있으나, 연결 리스트는 노드를 통해서만 다음 노드를 참조할 수 있는 특성 때문에 처음부터 다음 노드들을 탐색 해야함
-
추가, 삭제에는 연결 리스트 / 조회 (탐색)에는 순차 리스트가 더 효율적
저장되는 데이터가 적을 경우 배열,벡터,리스트 어느것이나 성능상 큰 차이가 없음 -
-
비단순 구조 - 선형 구조 (Linear) - 스택 ( Stack )
LIFO(Last In First Out) - 가장 최근에 추가된 항목이 가정먼저 제거되는 방식.
리스트의 한 쪽 끝에서만 데이터의 삽입 및 삭제가 이루어짐
-
스택의 추가
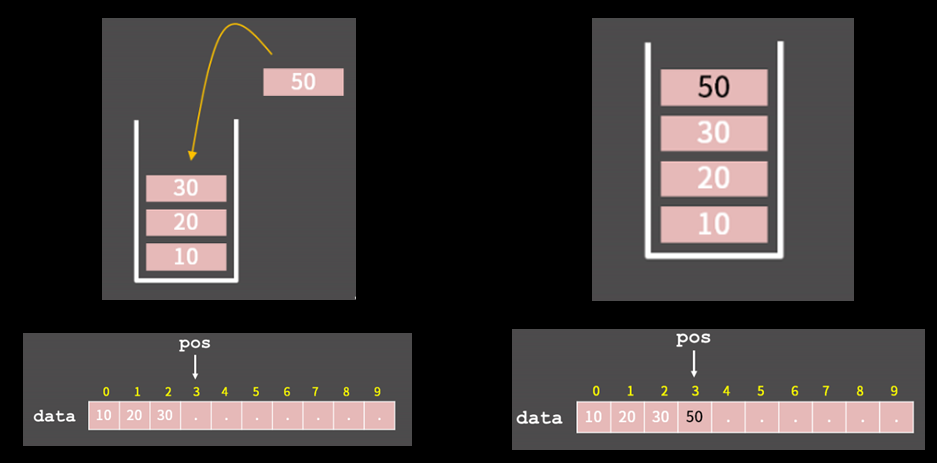
pos가 가르키는 곳에 새로 삽입할 원소를 쓰고 pos를 1증가시켜주면 끝
간단 코드
case1 void push(int val) { dat[pos] = val; // step1 pos++; // step2 } case2 void push(int val) { dat[pos++] = val; // step1, 2 } -
스택의 삭제
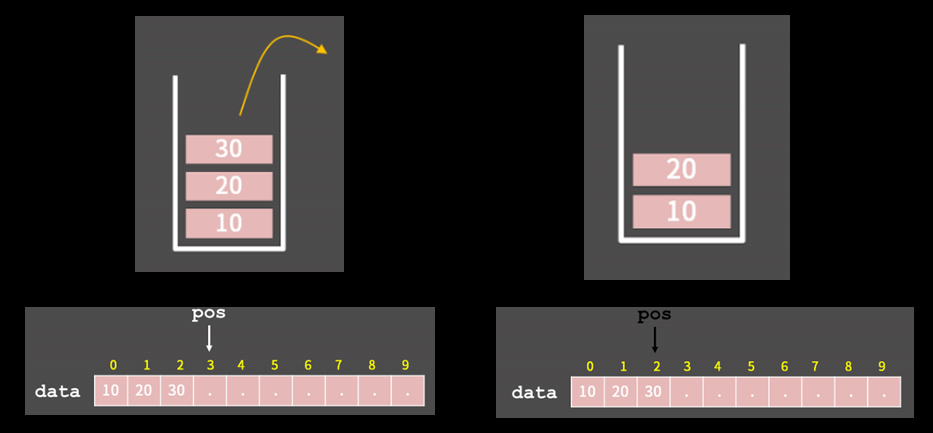
삭제는 더 간단하게 pos를 빼주기만하면 된다.
간단 코드
void pop() { pos--; } -
스택의 구현
- 배열과 달리 스택은 상수 시간에 i번째 항목에 접근 불가
- 스택에서 데이터를 추가하거나 삭제하는 연산은 상수 시간에 가능
- 배열처럼 원소들을 하나씩 옆으로 밀어 줄 필요가 없음.
-
스택의 사용 사례
문제의 종류에 따라 배열보다 스택에 데이터를 저장하는 것이 더 적합할 수 있음
- 재귀 알고리즘
- 웹 브라우저 방문기록 (뒤로가기)
- undo (실행취소)...
-
-
비단순 구조 - 선형 구조 (Linear) - 큐 ( Queue )
FIFO(First In First Out) - 가장 먼저 넣은 추가된 데이터가 먼저 나오는 방식 ( 출처 )
한쪽 끝(rear) 에서는 삽입연산 다른 한쪽 끝(front)에서는 삭제연산이 이루어짐
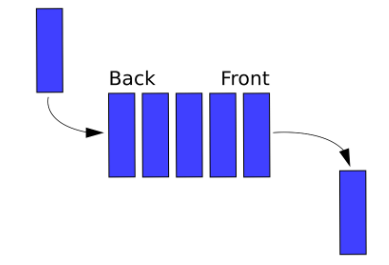
-
큐의 삽입
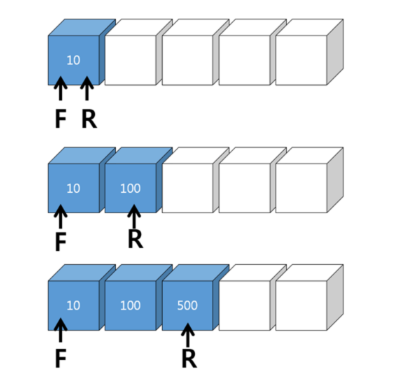
큐에 데이터를 넣는 경우 : F는 고정, R은 추가되는 데이터를 가리키며 이동
-
큐의 삭제
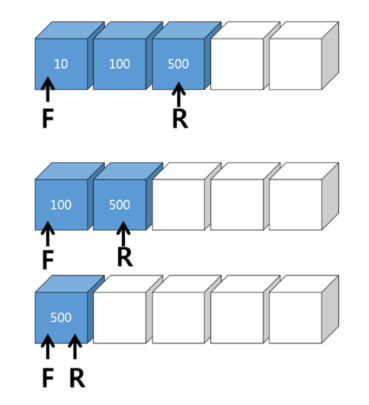
( Front 고정 ) 데이터 삭제 : F는 고정,삭제 될때마다 R이 이동
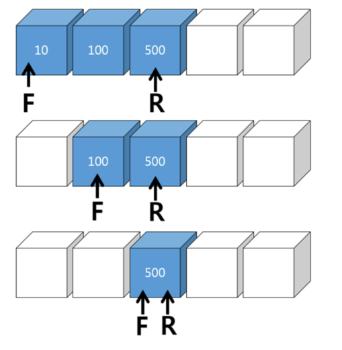
( Rear 고정 ) 데이터 삭제 : R은 고정, F가 내보낼 데이터를 순차적으로 가리킴
-
큐의 문제점
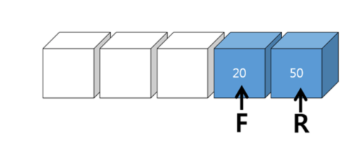
R이 배열의 끝까지 갈경우 새로운 데이터를 받을 수 없음 -> 재정렬 필요
-
큐의 사용 사례
주로 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있을 경우- 은행 업무
- 콜센터 고객 대기시간
- 프로세스 관리
- 너비 우선 탐색 (BFS ,Breadth-First Search) 구현
- 캐시 ( Cache ) 구현
-
-
비단순 구조 - 선형 구조 (Linear) - 덱 ( Deque )
모든 방향의 끝에서 삽입과 삭제가 모두 가능한 방식
->큐와 스택을 합친 형태의 구조

- 특징
- 크기가 가변적
- 중간 요소가 삽입,삭제될 때, 요소를 앞/뒤로 밀 수 있어 Vector보다 좋은 성능
- 앞/뒤 삽입 삭제 성능은 좋지만, 중간의 삽입/삭제 성능은 좋지 않음
- 특징
