torch.nn.Module
nn.Module class는 pytorch에서 model을 만들때 항상 상속시켜주는 친구이다.
모델의 뼈대라고 생각하면 좋다.
class Mymodel(nn.Module):
###이하생략###정확히는 아래와 같은 역할을 한다고 한다.
- 딥러닝을 구성하는 Layer의 base class
- Input, Output, Forward, Backward 정의
- 학습의 대상이 되는 parameter(tensor) 정의
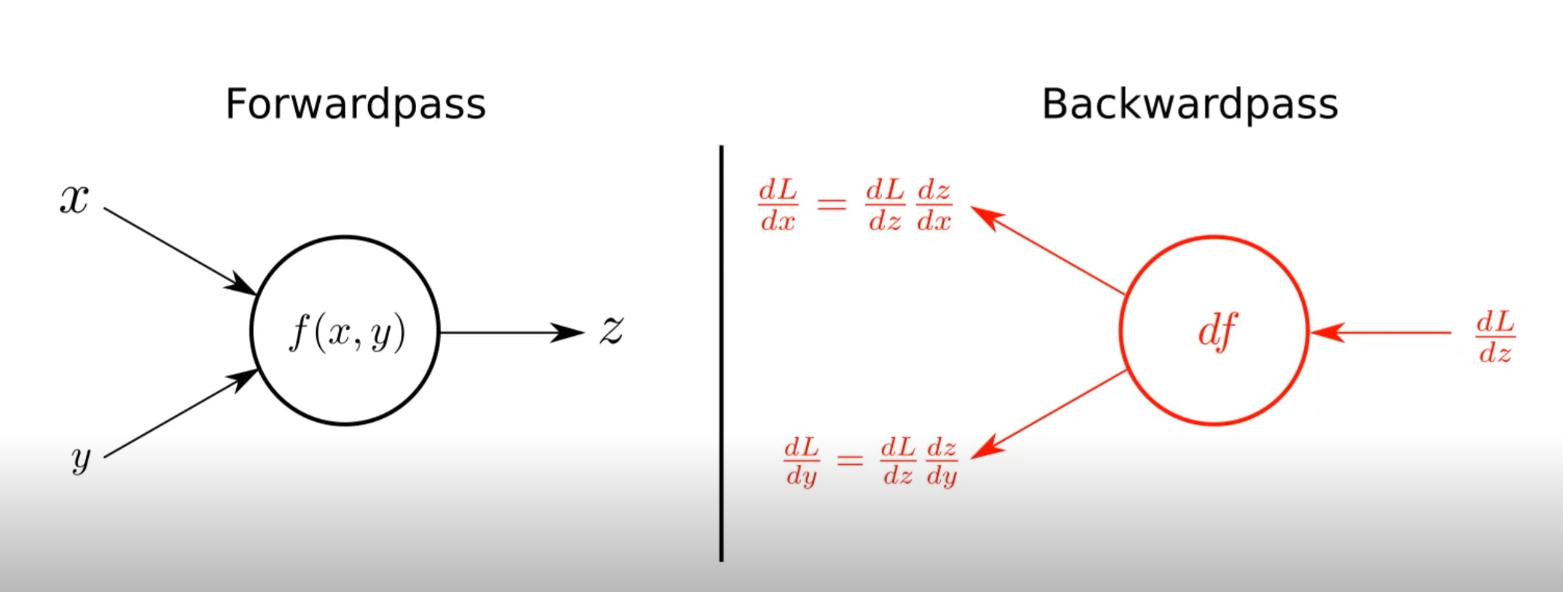
기본적으로 네트워크의 모델들은 2가지로 구성되어 있다고 보면 된다. Input을 통해 Output을 얻는 Forwardpass 그리고 Parameter들을 학습시키는 Backwardpass.
torch.nn.Parameter
우리가 Backwardpass를 할 때 학습되는 것이 바로 Parameter들이다.
다음과 같은 특징을 갖는다.
- Tensor 객체의 상속객체
- nn.Module 내에 attribute가 될 때는 required_grad=True로 지정되어 학습 대상이 되는 Tensor
- 우리가 직접 지정할 일은 잘 없다.
- 대부분 layer에는 weights 값들이 지정되어 있다.
class MyLinear(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = nn.Parameter(torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x: Tensro):
return x @ self.weights + self.bias이해를 위해 코드를 자세히 살펴보자
일단 MyLinear라는 클래스는 nn.Module을 상속하고 있다.
왜냐하면 nn.Module이 모델을 만드는 데에 있어서 뼈대의 역할을 해주기 때문이다.
초기화 부분(__init__)을 보면 in_feautres와 out_features가 있다.
각각 input의 dimension과 output의 dimension을 설명한다.
다시말해, 입력되는 데이터의 차원 그리고 출력되는 클래스(label)의 개수를 의미한다(이미지 분류에서는)
위의 모델에서는 self.weights 그리고 self.bias를 nn.Parameter를 통해 파라미터로써 생성해주었다. 하지만 실제로 모델을 구현할 때에는 nn.Parameter을 사용하여 파라미터를 구현할 일을 거의 없다.
여기서 이러한 의문을 가질 수도 있다.
굳이 weight와 bias를 nn.Parameter를 이용해서 선언해주어야 할까?
Tensor을 이용해서 선언해줘도 되지 않을까?
class MyLinear(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = Tensor(torch.randn(in_features, out_features))
self.bias = Tensor(torch.randn(out_features))
def forward(self, x: Tensro):
return x @ self.weights + self.bias
layer = MyLinear(7,12)
x = torch.randn(5, 7)
layer(x).shape>>> torch.Size([5.12])for value in layer.parameters():
print(value)Tensor로 선언한 경우 아무것도 출력되지 않는다. 그 이유는 Tensor는 미분의 대상이 되지 않기 때문이다. 반면에, nn.Parameter로 선언하는 경우에는 출력된다. 직접해보면 쉽게 이해할 수 있을 것이다.
