Intro
여태까지 Vanilla data에서 pre-processing 과정을 거쳐서 model에 feeding 해줄 수 있는 형태까지 Data Processing 과정을 마쳤다.
오늘은 모델에 대해 알아보자!
1. Model
지금까지 열심히 정제한 데이터를 이제 Model안으로 넣어주어야 한다. 여태까지와 마찬가지로 PyTorch 모듈로 해결 할 수 있다.
하지만 , 한번쯤은 왜 많고 많은 framework 중에 PyTorch를 사용해야 하는지 의문이 들 수 있다. Tensorflow, Keras 등 유명한 많은 framework를 뒤로하고 PyTorch의 장점은 무엇일까?
1-1) PyTorch
https://velog.io/@yh8109/PyTorch-Introduction
위의 링크에 자세하게 설명되어 있다. 간략하게 요약해보면
다이나믹한 그래프를 이용하기 때문에, 즉 높은 자유도를 갖고 있어 연구하고 공부하기에 편하기때문이다.

또한, Python과 매우 유사하기때문에 python의 형식과 구조를 미리 알고 있다면, 추가적인 공부 없이 여러가지 응용이 가능할 뿐더러, 에러를 핸들링하기도 쉽다.
1-2) PyTorch의 nn.module
모델을 정의할 때 아래와 같은 형태로 정의하는 것이 보편적이다.
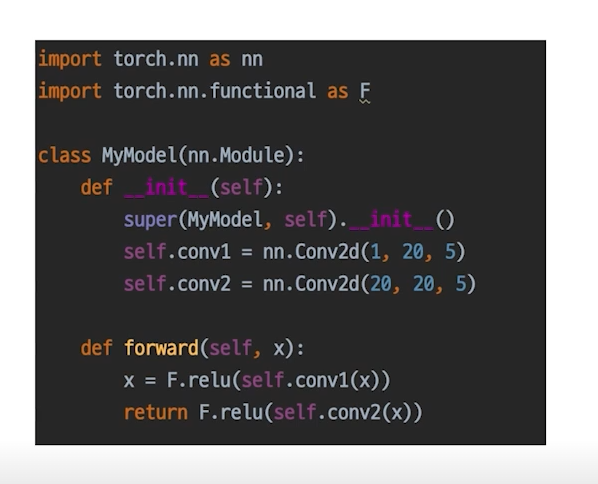
모든 nn.Module 은 forward() 함수를 갖는다.
내가 정의한 모델의 forward()를 한번만 실행하는 것으로 모델안에 정의된 다른 모듈의 forward()가 각각 실행된다는 점을 명시해야한다.
1-3) nn.Parameters
위에서 정의된 모델의 Layer 각각 parameter를 가지고 있다. parameter는 쉽게 말해 layer의 weight, bias 등을 가리킨다.
기본적으로 PyTorch에서 구현된 parameter들은 Tensor를 상속하고 있다.
또한 parameter는 기본적으로 data, grad, requires_grad 변수 등을 갖고 있다.
data는 parameter의 Tensor 값을 의미한다. param.data
grad는 각 parameter들의 gradient 값이 저장 되어 있다. param.grad
requires_grad는 boolen 형태로 parameter가 backpropagation을 통해 학습을 할지 말지 결정하는 요소이다. (True 이면 학습 False 이면 학습 X) param.requires_grad
모델을 불러왔을 때 어떤 parameter들은 가지고 있는지 확인하고 싶으면 어떻게 해야될까?
두가지 방법이 있다.
model.state_dict()
- 모델들의 파라미터가 key - value 쌍으로 출력된다.
model.parameters()
- iterable한 값으로 모델의 parameter들이 나열된다.
for param in model.parameters():
print(param)-> 위와 같은 반복문 형태로 출력해 볼 수 있다.
여기서 한가지 응용이 가능하다
위에서 언급된 requires_grad와 model.parameters()를 사용해
모델에서 내가 학습하고 싶은 parameter들만 학습을 시킬 수가 있다.
for param in model.parameters():
param.requires_grad = False
model.fc.weight.requires_grad = True
model.fc.bias.requires_grad =True 위의 코드를 보면 model에서 fc 레이어의 weight 와 bias 의 requires_grad를 True로 설정하는 한다.
이렇게 학습을 하게 되면 fc 레이어의 parameter만 학습을 시키고 나머지 layer들의 parameter 들은 학습하지 않게 된다.
2. Pretrained Model
Pretrained Model 미리 학습되어 성능이 검증된 모델을 이야기 한다.
모델 일반화를 위해 매번 수많은 이미지를 학습시키켜야 하는 데 이는 매우 까다롭고 시간이 오래걸린다.
또 모델을 충분히 학습시킬 만한 데이터가 부족할 수도 있다. 이 때 사용하는 것이 Pretrained Model 이다.
성능이 검증된 Pretrained Model을 사용하면 좋음 품질, 대용량의 데이터로 미리학습한 모델을 바탕으로 내 목적에 맞게 다듬어서 사용하면서 시간과 자원을 매우 효율적으로 사용할 수 있게 된다.
아래는 torchvision.models에서 제공하는 Pretrained Model들이다.

3. Transfer Learning
Transfer Learning(전이 학습)이란 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경마의 학습에 이용하는 것을 의미한다. 전이 학습은 데이터의 수가 적을 때 도 효과적이며, 학습 속도도 빠르다. 물론, 전이학습 없이 학습하는 것보다 훨씬 높은 정확도를 제공한다는 장점도 존재한다.
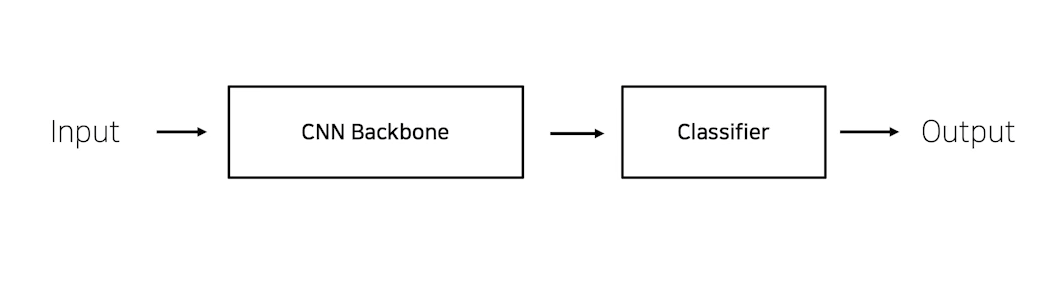
3-1) CNN base 모델 구조 (simple)
이미지 분류 CNN 모델의 기본적인 구조는 아래와 같이 크게 CNN Backbone과 Classifier로 구분되어 진다.
torchvision.models 에서 하나의 CNN 모델을 생성해 마지막 layer 부분을 살펴보면 다음과 같다.

여기서(fc)가 바로 fully connected layer, 즉 classifier를 의미한다.
out_features=1000으로 설정되어 있는 것을 보아 , class는 1000개가 있음을 짐작해 볼 수 있다.
3-2) Case by Case
Pretrained model을 사용할 때에는, pretrainig 할 때 설정했던 문제와 현재 문제와의 유사성을 고려해야 한다.
Case 1. 문제를 해결하기 위한 학습데이터가 충분하다
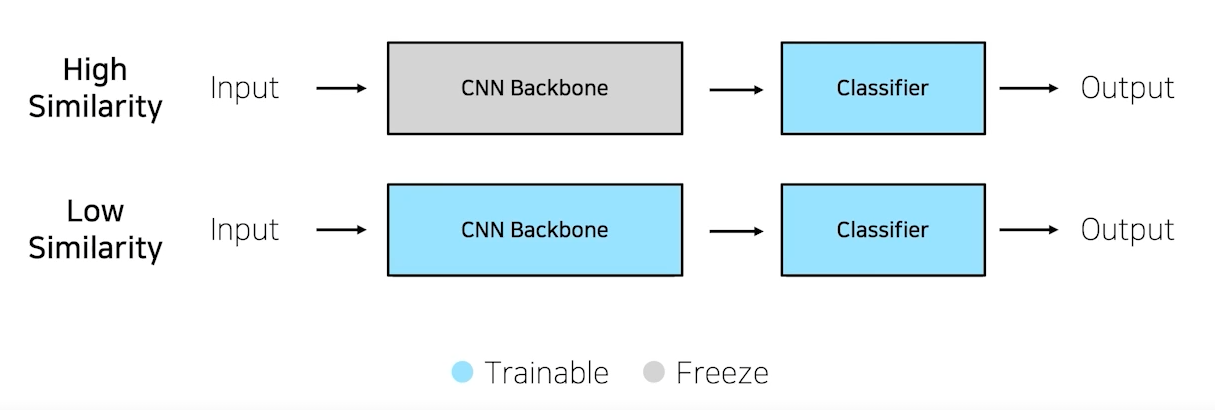
High Similarity : pretrained model과 현재 문제가 유사할 때는 CNN Backbone을 freeze하고 classifier만 학습시키며 이를 Feature Extraction이라고 한다.
Low Similarity : pretrained model과 현재 문제가 유사하지 않을 때, CNN Backbone과 classifier 모두 학습시키며 이를 Fine-Tuning이라고 한다.
Case 2. 학습데이터가 충분하지 않은 경우
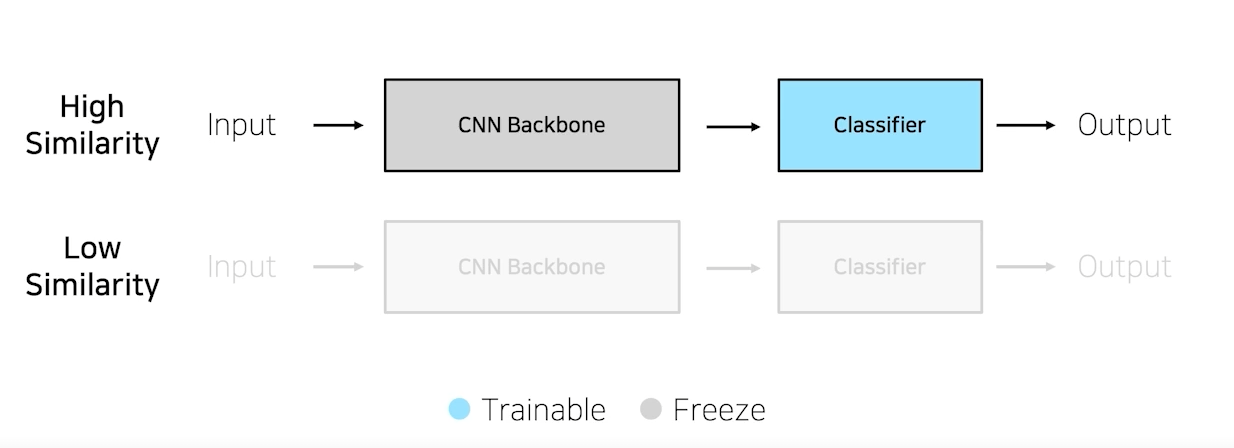
학습데이터가 충분하지 않은 경우 High Similarity는 동일하게 Feature Extraction을 하면 되지만 Low similarity 일 경우 학습이 불가능하다. (overfitting, underfitting 할 가능성이 높음)
개인 학습 회고
어제 기본적인 CNN 모델을 구성해서 학습을 하고 테스트를 해봤는데 거의 학습이 되지 않았다.
오늘은 transfer learning을 시도해 보았다. resnet-18를 사용해서 여러가지 hyper-parmeter를 조정한 결과 테스트 시 Accuracy가 78%정도의 성능이 나왔다. 모델을 학습하면서 느낀점은 Epoch가 크면 클수록 좋은 것은 절대 아니라는 점이다. 오히려 epoch가 어느 지점을 지나면 Accuracy가 떨어지는 현상이 발생했다. 또한 data Augmentation을 하겠다고 데이터를 여러가지 PyTorch transfomrs을 통해 변형시켜봤지만 이것 조차 Accuracy에 부정적인 영향을 줄 뿐이었다.
모델 학습이외에 Model framework 구성에 대해서도 조금 알아보았다.
python 기본 모듈의 Config parser를 이용하면 모델을 학습할 때 도움이 될 것 같다.
Config parser
# config_file_create.py
from configparser import ConfigParser
config = ConfigParser()
config['settings'] = {
'debug': True,
'gpu': True,
'log_path': '/log',
'data_path': '/data'
}
config['hyper_params'] = {
'epoch': 10,
'batch_size': 64,
'lr_rate': 1e-3
}
with open('./config.ini', 'w') as f:
config.write(f)위의 코드를 실행하면 config.ini 파일이 워킹 디렉토리에 생성이 된다. 사실 이렇게 생성해줄 필요는 없고 한번 생성된 파일을 직접 바꾸면서 학습을 시켜주면된다.
[settings]
debug = True
gpu = True
log_path = /log
data_path = /data
[hyper_params]
epoch = 10,
batch_size = 64,
lr_rate = 1e-3
이런식으로 저장된다. main 스크립트를 실행하기전 파일에서 epoch나 batch_size, 등 하이퍼파라미터들을 변경해주면 학습시 자동으로 설정된다.
# main.py
from configparser import ConfigParser
parser = ConfigParser()
parser.read('config.ini')
print(parser.sections()) # ['settings','hyper_params']
print(parser.get('settings','gpu')) # True
print(parser.options('settings')) # ['debug', 'gpu','log_path','data_path']main.py 파일 즉, 실행되는 스크립트 상단에 선언해주면 끝이다.
추가적인 코드는 여러가지가 있다.
- sections(): 모든 section 리스트 반환
- get(<section_name>,<option_name>): 섹션의 옵션값 str로 반환
- getint(),getfloat(),getboolean(): int/float/boolean으로 반환
- options(<section_name>):섹션 안의 선택가능한 옵션들반환
- in: 섹션 존재 여부 확인
framework에서 argparser부분은 어느정도 틀이 잡힌 것 같다.
다음번에는 state_dict()를 log로 남겨서 load 하는 것과 torchvision 모듈이 아닌 timm 모듈을 활용해서 모델을 학습시켜볼 게획이다. timm 모듈을 사용하면 Vit 모델을 사용할 수 있다고 한다.
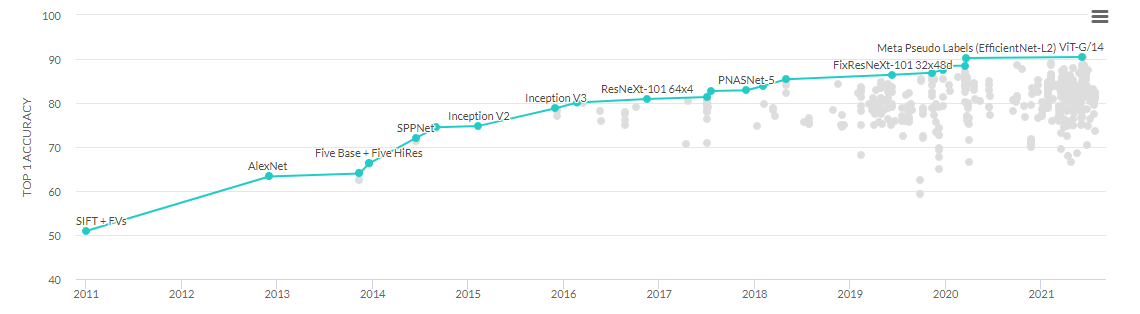
vit 모델을 이해하진 못했지만 2021년 상단에 위치한 것을 보니 무조건 써봐야 겠다는 생각이 든다
