| Paper arXiv | Introduction to Total-Decom | Github repo |
Decomposition is the key to manipulate and edit the 3D geometry of the reconstructed scene.
Neural implicit feature distillation
Normal
- gradient of SDF: the direction of the surface normal
- Normal(p)=∣∇d(p)∣∇d(p)
Depth
- directly obtained from the SDF values along the ray
- Depth(p)=∫tneartfarT(t)σ(t)t,dt
Semantic Logits
- class probabilities for semantic segmentation at each sample point
- features extracted from the SAM encoder
- Semantic Logits(p)=∫tneartfarT(t)σ(t)logits(t),dt
Generalized Features
- texture, material properties, ...
- Generalized Features(p)=∫tneartfarT(t)σ(t)features(t),dt
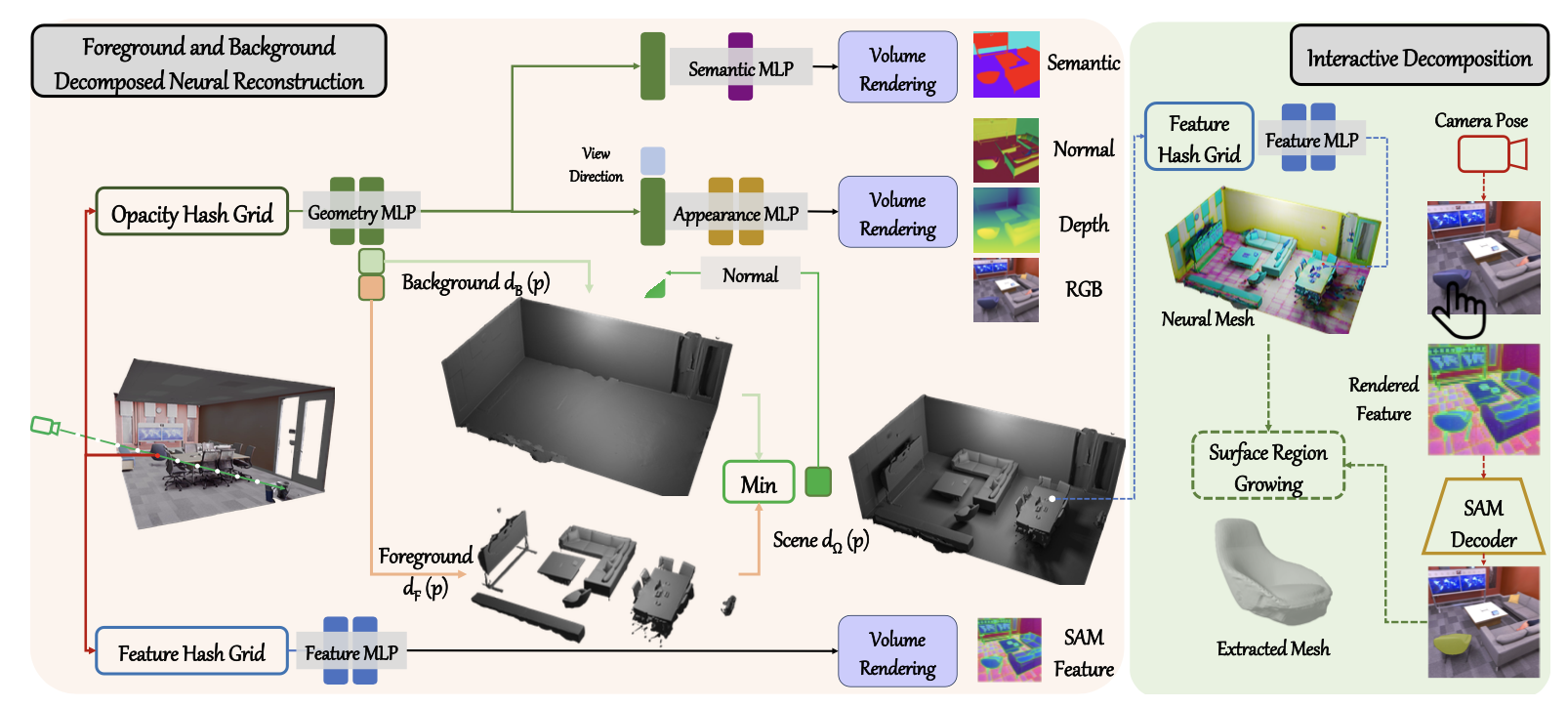
Foreground and Background Decomposed Neural Reconstruction
Foreground
: Objects
- 각 Foreground와 Background는 SDF field를 따로 가짐
- S={F,B}, 최종 scene은 Ω=F∪B, 최종 scene SDF는 두 SDF의 min
- SDF function d(p), point p
- ray r(t)=o+tv Camera position o, direction v
- Color C(p,v), SDF S(p), generalized feature F(p)
- Occlusion-aware Opacity Rendering: Guides the learning process →LO
- Object Distinction Regularization: Ensures a clean foreground mesh →Lreg
Background
: Walls, floors, ceilings
- Manhattan World Assumption: 인공 구조물은 x, y, z축을 따라 만들어졌다는 가정 →Lman
- Root Finding Method: 천장에서 ray를 쏘아 surface에 부딪치면 floor로 가정 →Lfloor
- Root는 SDF=0, 즉 d(p+t⋅d)=0 임
Loss function
L=Lrgb+Lgeo+λ1LO+λ2Lreg+λ3Lman+λ4Lfloor+λ5Lsem+λ6Lf
- Lrgb,Lgeo : MonoSDF
- LO=Er∈R[∑Si∈S∣∣O^Si(r)−OSi(r)∣∣]
- Lreg=Ep[∑dSi(p)=dΩ(p)ReLU(−dSi(p)−dΩ(p))]
- Lman=Er∈F(p^f(r)∣1−n^(r).nf∣)+Er∈W(mini∈{−1,0,1}p^w(r)∣i−n^(r).nw∣)
- p^f,p^w : prob of the pixel being floor and wall (from semantic MLP)
- F,W : sets of camera rays of the pixels labeled as floors and walls
- n^r : rendering normal of rays r
- nf=<0,0,1>
- Lfloor=∣1−n(pf).nf∣
- pf,nf : floor, the assumed normal direction in the floor regions
- nw : learnable normal for walls
- Lsem=−Er∈R[∑l=1LPl(r)logP^l(r)]
- Cross-entropy loss
- Pl(r),P^l(r) : multi-class semantic probability as class l of the ground truth map and rendering map for ray r
- Lf : L2 loss, rendered generalized feature F^(r) for distilling the F(r) from the SAM encoder
- λ = 0.1, 0.1, 0.01, 0.01, 0.5, 0.1
Interactive decomposition
-
Mesh Surface Extraction: Converting implicit neural representations into explicit mesh representations
-
Feature Distillation: Features into mesh vertices
-
Object Seeds Generation: SAM features and human clicks to generate initial object seeds
-
Region-growing Algorithm
- foreground mesh를 얻어 이에만 growing 알고리즘을 적용함으로써 low-noise에서의 growth 가능
- 각 object에 속하는 seed가 object 전체를 덮도록 확장되어 segmentation을 더 잘 하도록 도움
Object Decomposition

- Seed Points Expansion: Initial seed points expanded along the mesh using a
region-growing method
- sim(fs,fn)<−∣∣fs∣∣∣∣fn∣∣fs.fn
- Boundary Constraints
- 2D seed pixels and boundary pixels are references for 3D seed vertices and boundary vertices
- SAM decoder: provides dense mask
- explicit geometry information (vertices and edges): rules out vertices with high feature similarities
Evaluation
- Replica and ScanNet
- Metrics: Acc, Comp, C-L1, Prec, Recall, F-score
