HDFS 설치 2 - VirtualBox & Centos
* network 설정 * 인증, 권한 * hostname 설정 * 환경변수 설정
Oracle Virtual Box 6.1 / 포인트 장치 -> usb
Centos 8.0 VM
VM : CentOS_Hadoop00
[계정]
- useradd hadoop
- passwd hadoop / hadoop
Java 버전
- Java 버전 => jdk 1.8 +
- Hadoop v3 : jdk 1.8 +
dnf install java-1.8.0-openjdk
dnf info java-1.8.0-openjdk
dnf remove java-1.8.0-openjdk
dnf install java-1.8.0-openjdk-devel.x86_64 -yjava -version-- command에 java -version 입력했을 때 Java 명령어 못찾으면
Which java -> readlink -f /usr/bin/java입력 -> java_home 보임. 자바 홈 밑에 java 쓰면 됨
Java 환경 변수
-
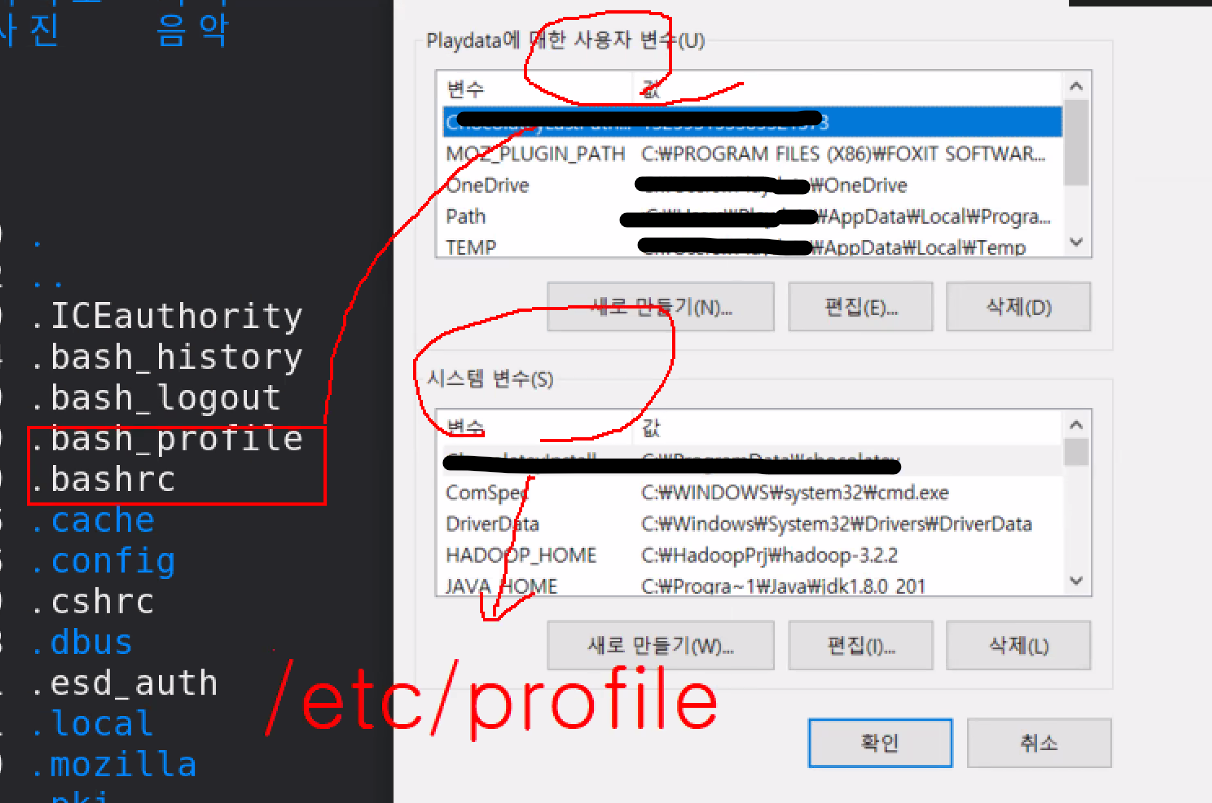
환경 변수 참고 :
bash__는 사용자 변수, /etc/profile은 시스템 변수의 개념이다.
-
기존에 잘 돌고있는 파일을 고치려면 복사해놓아야 함 (cp)

-
==> /etc/profile 환경변수
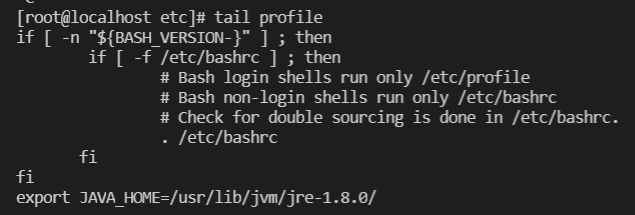
cat >> profile export JAVA_HOME=/usr/lib/jvm/jre-1.8.0/

tail profile
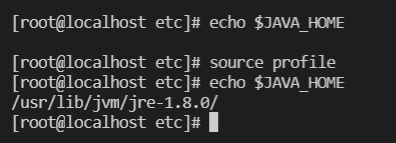
[root@localhost etc]# echo $JAVA_HOME
[root@localhost etc]# source profile
[root@localhost etc]# echo $JAVA_HOME
[root@localhost etc]#
-
JDK 경로 확인

-
ll 확인 (-> : 링크 파일)
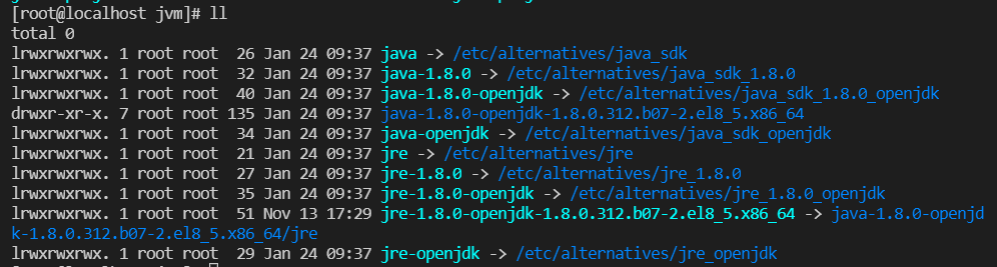
-
hadoop 계정 확인
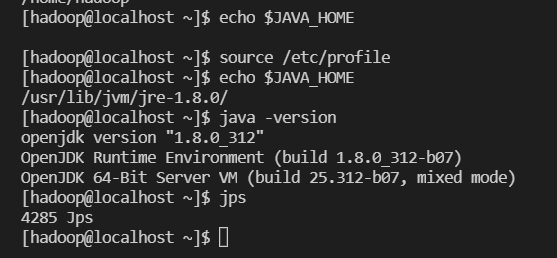
[hadoop@localhost ~]$ echo $JAVA_HOME
[hadoop@localhost ~]$ source /etc/profile
[hadoop@localhost ~]$ echo $JAVA_HOME
/usr/lib/jvm/jre-1.8.0/
[hadoop@localhost ~]$ java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
[hadoop@localhost ~]$ jps
4285 Jps
[hadoop@localhost ~]$ Hadoop 버전
- Hadoop 버전 => Hadoop v3.2.2
- Hadoop v3.2.2
Hadoop 설치
- hadoop 유저 로그인 :
su - hadoop - 하둡 3.2.2 버전 다운
wget http://apache.mirror.cdnetworks.com/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
압축해제
tar -xvzf hadoop-3.2.2.tar.gz
hadoop 환경변수
- hadoop
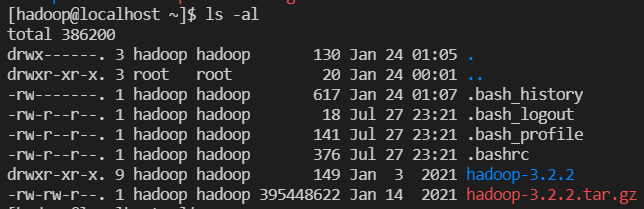
- ==> /.bashrc 환경변수
- cp .bashrc .bashrc~ <== 복사본 .bashrc~
- cat >> .bashrc <== hadoop 계정 환경변수 추가
export HADOOP_HOME=/home/hadoop/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
cat >> .bashrc
export HADOOP_HOME=/home/hadoop/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

[hadoop@localhost ~]$ source .bashrc: 스크립트 실행
[hadoop@localhost ~]$ hadoop version: hadoop 버전 확인

- ==> /.bashrc 환경변수
폴더 생성
~~/data
/datanode
/namenode- 생성 위치(pwd) :
/home/hadoop/hadoop-3.2.2
- data 디렉토리 생성 :
mkdir data - namenode 디렉토리 생성 :
mkdir namenode - datanode 디렉토리 생성 :
mkdir datanode

폴더 구성/확인
/home/hadoop/hadoop-3.2.2/etc/hadoop
cat hadoop-env.sh | grep "JAVA_HOME"

.sh 파일 구성
- hadoop-env.sh 파일 구성
vi hadoop-env.sh

- :set nu (라인 숫자 확인)
- / 검색모드
- /export JAVA_HOME => 54번에 있음
- :54
- x : 한 자리 지우기
- a : append라서 뒤에 쓰기 가능 - 추가
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0

xml 파일 구성
.xml 파일 구성
- 공식 문서 참고(유사 분산)
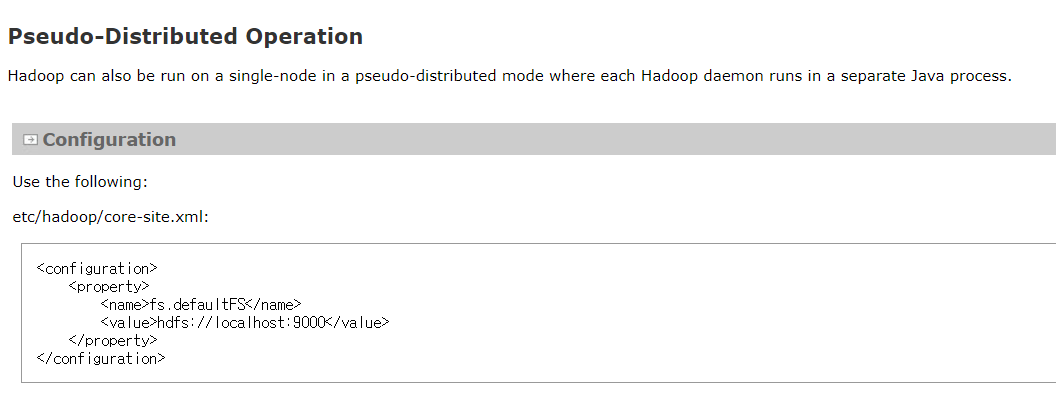
- hdfs-site.xml 구성
#. namenode와 datanode 경로 맞게 변경해줘야 함
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>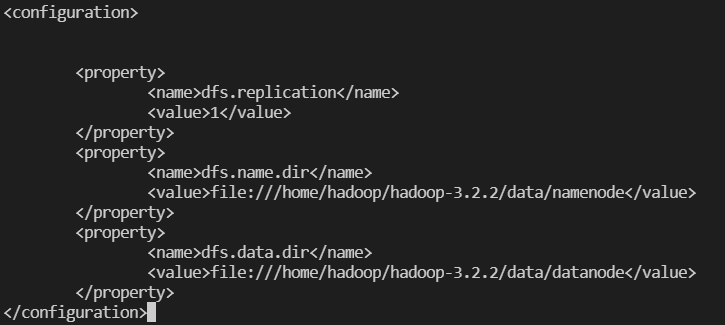
- core-site.xml 파일 수정
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- mapred-site.xml 구성
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>- yarn-site.xml 구성
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property> 
reate and setup ssh certificates
- 공개키, 개인키 생성 ssh-keygen -t rsa
- 생성된 공개키를 로컬의 authorized_keys 에 추가하고 권한을 변경
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 640 ~/.ssh/authorized_keys
- 접속 확인 ssh localhost
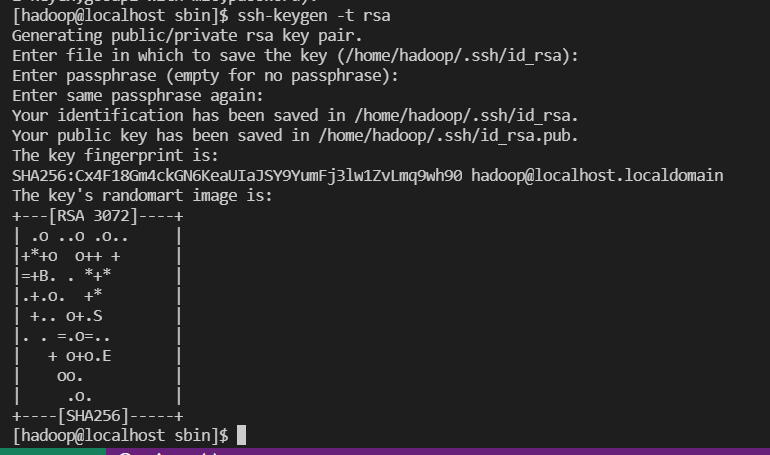
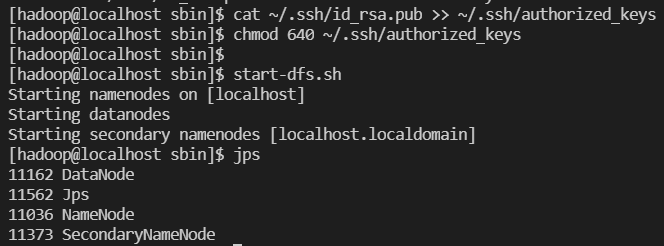
정상 동작
-
hadoop 사용자로 Namenode 포맷
hdfs namenode -format -
hadoop 클러스트 시작
start-dfs.sh -
hadoop 서비스 상태 확인
jps
namenode, datanode, secondary namenode가 나와야 정상

-
YARN 서비스 실행
start-yarn.sh -
hadoop 서비스 상태 확인
jps
ResourceManager, DataNode, NameNode, NodeManager, SecondaryNameNode가 나와야 정상
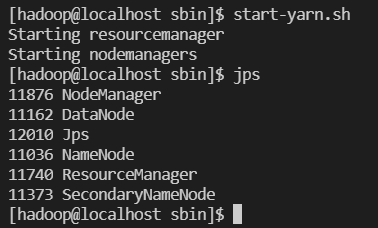
-
hadoop 서비스 중지
stop-all.sh
Configure Firewall
hadoop이 포트 9870, 8088을 사용 => 포트를 방화벽에서 허용해줘야 함(로컬환경에서는 방화벽 설정 안해줘도 됨)
firewall-cmd --permanent --add-port=9870/tcp
firewall-cmd --permanent --add-port=8088/tcp
firewall-cmd --reload최종 확인
http://localhost:9870 or http://your-server-ip:9870
-
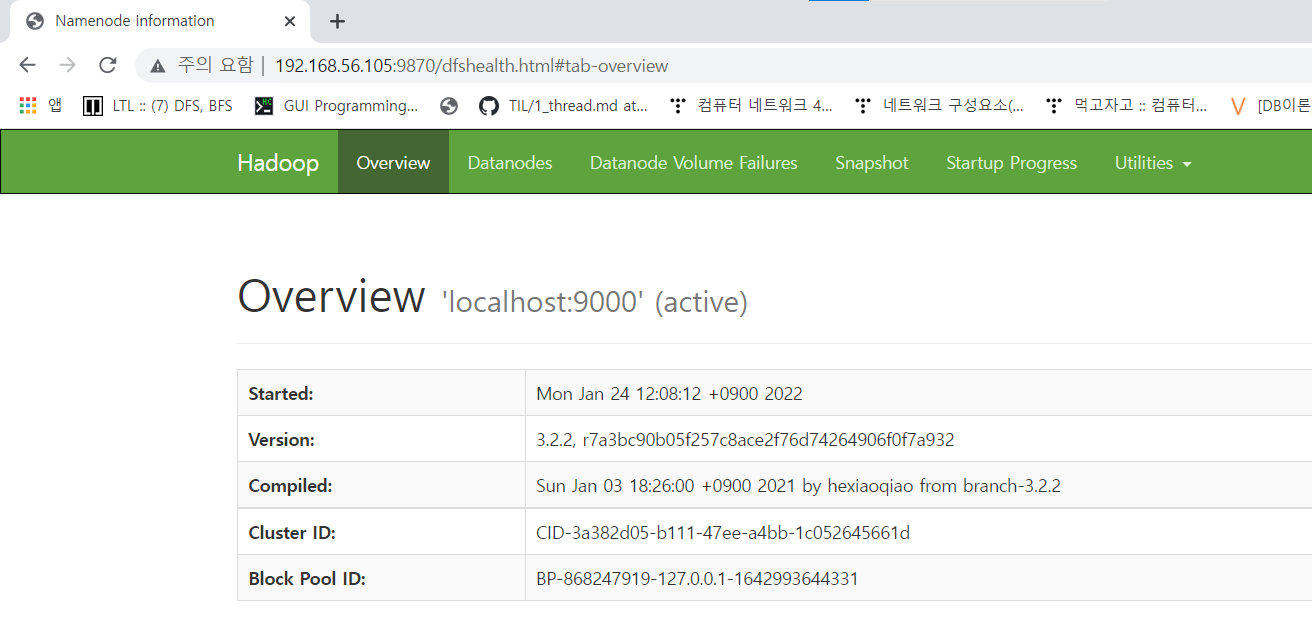
localhost 9000 확인

-
localhost 9870 확인
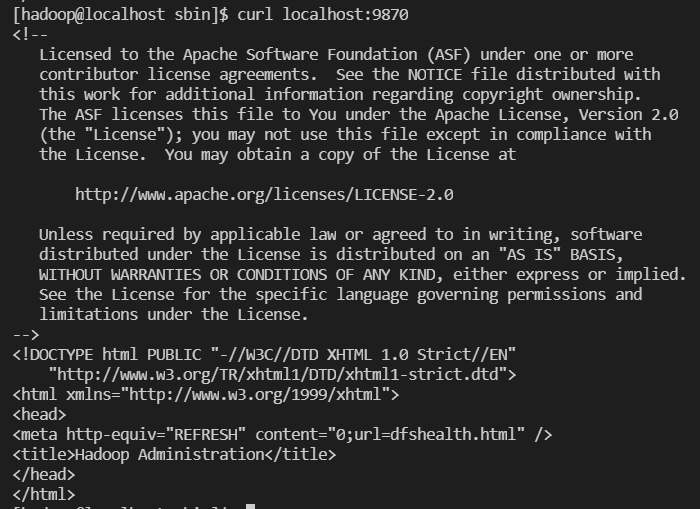
-
cli 환경에서 local pc로 접속하려면
ip주소:9870, ip주소:9000 으로 들어가야 함
참고 자료
-
hadoop.org => single node setup
https://hadoop.apache.org/docs/stable/
여기서 분산 자료 참고

-
download -> binary 들어가 아무거나 다운로드
https://hadoop.apache.org/releases.html
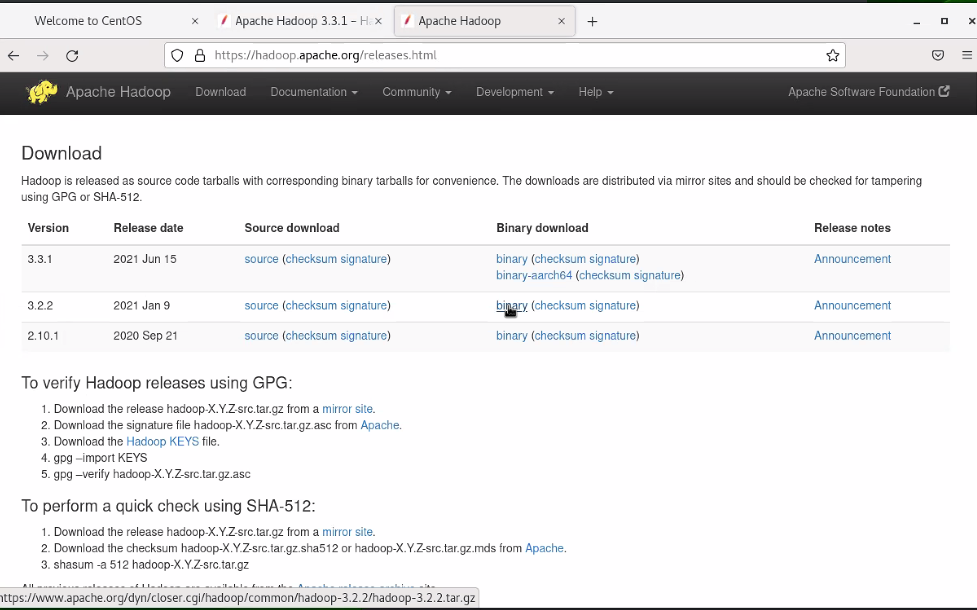
-
hadoop 3.2.2 on centos 8 검색
https://tdoodle.tistory.com/entry/How-To-Install-and-Configure-Hadoop-on-CentOSRHEL-8
실습
[ 실습 01 : File 생성, 주입 ]
디렉토리 생성 /test00
- touchz
- put README.txt- 디렉토리 생성 /test00


- touchz (0 bite 파일 생성)
hdfs dfs -touchz /test01/test11.txt

- put README.txt
hdfs dfs -put ./README.txt


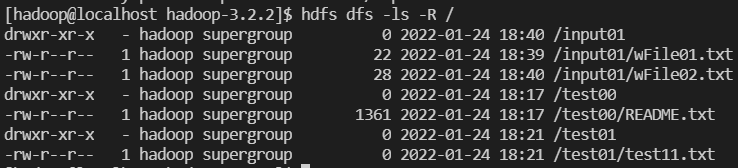
[hadoop@localhost hadoop-3.2.2]$ hdfs dfs -mkdir /test00
[hadoop@localhost hadoop-3.2.2]$ hdfs dfs -mkdir /test01
[hadoop@localhost hadoop-3.2.2]$ hdfs dfs -put ./README.txt /test00
[hadoop@localhost hadoop-3.2.2]$ hdfs dfs -ls -R / [ 실습 02 : java wordcount 1 ]
- 목적 : 하둡 맵리듀스의 이해
#. hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /대상폴더 /출력폴더
hdfs /input01
/wFile01.txt : [Hello World Bye World]
/wFile02.txt : [Hello Hadoop Goodbye Hadoop]
hadoop fs -put ./wFile01.txt /input01
hadoop fs -put ./wFile02.txt /input01
hadoop fs -ls -R /-
input01 폴더에 현재 경로에 있는 wFile01, wFile02 파일 복사
hdfs dfs -put ./wFile01.txt /input01


-
확인
hadoop fs -cat /input01/wFile01.txt
hadoop fs -cat /input01/wFile02.txt

-
hadoop jar 명령으로 wordcount
hadoop jar /~~~~/hadoop-mapreduce-examples-3.2.2.jar wordcount /input01/output01 -
생성파일 조회 및 내용 확인
hadoop fs -ls /
hadoop fs -ls /output01
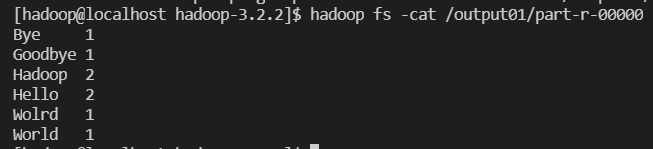
output01 폴더 안에 part-r-00000 파일은 txt 파일이므로 cat으로 읽을 수 있음
hadoop fs -cat /output01/part-r-00000
[hadoop@localhost hadoop-3.2.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /input01 / output01